

CXL 3.0 — не просто очередной интерфейс для железа. Это попытка перестроить саму логику работы с памятью в сервере: отделить ресурсы памяти от одного процессора, связать CPU, ускорители и память в более гибкую систему и убрать узкие места, которые давно мешают AI, HPC и большим базам данных.
«Хороший технический текст не прячет суть за модными словами. Если технология убирает узкое место — надо показать, какое именно узкое место, в каком месте архитектуры и с какими ограничениями».
Важная оговорка. Часть официальных источников по CXL 3.0 недоступна в публичном доступе, а некоторые технические детали требуют проверки по документации конкретной платформы. Дальше я опираюсь на спецификации CXL Consortium, техническую документацию производителей и аккуратные выводы без выдуманных цифр там, где данных нет. Если для проектирования инфраструктуры нужен точный sizing, сверять надо по документации платформы, CPU и устройств конкретного поколения.
Что такое CXL 3.0 и зачем нужен этот стандарт
CXL 3.0 — версия открытого стандарта Compute Express Link, который работает поверх физического слоя PCI Express и добавляет то, чего обычному PCIe не хватало для современной серверной памяти: когерентный доступ, более тесную работу CPU с устройствами и возможность строить более гибкую систему памяти.
Короче: стандарт нужен затем, чтобы CPU, ускорители и память в современных вычислительных системах могли обмениваться данными не как разрозненные острова, а как связанные участники одной архитектуры.
CXL создавался как ответ на дезагрегацию ресурсов в дата-центрах и на ограничения обычного PCIe — прежде всего отсутствие кэш-когерентности и неэффективное использование DRAM в серверах. Стандарт был разработан консорциумом CXL в 2019 году и определяет транспортный протокол на базе PCIe 5.0+ для когерентного обмена между процессорами, памятью и ускорителями. — CXL Consortium (2019). Compute Express Link Specification 1.0.
Проблема понятная.
Ядра в серверных процессорах растут. Ускорителей становится больше. Задачи машинного обучения, больших языковых моделей, in-memory баз и аналитики хотят всё больше памяти — причём не просто памяти объёмом побольше, а памяти с предсказуемым доступом, достаточной пропускной способностью и без лишнего копирования данных между CPU, GPU и внешними устройствами. Локальная DDR5 остаётся основной памятью, но одной локальной памятью уже не закрыть все сценарии экономично и гибко.
CXL 3.0 здесь важен как стандарт, который позволяет:
- расширять память сервера за пределы каналов памяти CPU;
- строить pooling памяти;
- подключать память через устройства CXL;
- организовывать объединение памяти и более гибкое управление памятью;
- уменьшать долю простаивающих ресурсов памяти в серверной инфраструктуре.
CXL нужен не для замены DRAM как класса. Он нужен для того, чтобы система памяти перестала быть жёстко привязана к одному сокету и одному набору DIMM.
Глоссарий терминов
- CXL
- Compute Express Link — открытый стандарт межсоединения для когерентного обмена данными между CPU, ускорителями и устройствами памяти поверх физической базы PCIe.
- CXL.io
- Протокол управления, инициализации и операций ввода-вывода. По роли ближе всего к привычному PCIe-стеку для конфигурации устройства.
- CXL.cache
- Протокол, который позволяет устройству работать с кэшируемыми данными и участвовать в когерентной модели доступа к памяти.
- CXL.mem
- Протокол доступа к памяти, через который хост может обращаться к памяти на устройстве CXL, например к memory expander.
- Pooling памяти
- Подход, при котором ресурсы памяти собираются в общий пул и распределяются между несколькими хостами или задачами по мере необходимости.
- Когерентность памяти
- Согласованность представления данных между кэшами и памятью, чтобы разные участники системы не работали с устаревшими копиями.
- Коммутаторы CXL
- Устройства fabric-уровня, которые позволяют соединять несколько хостов и несколько устройств CXL в более сложные топологии, а не только в схему «один хост — одно устройство».
Чем CXL 3.0 отличается от предыдущих версий
CXL 3.0 отличается от предыдущих версий тем, что расширяет стандарт от модели «точка-точка» в сторону fabric-подхода. Главное изменение — не косметика в протоколах, а переход к более масштабируемой архитектуре, где можно строить многоуровневую коммутацию, peer-to-peer взаимодействие и более развитое совместное использование памяти.
| Возможность CXL 3.0 | Что это значит | Практический эффект |
|---|---|---|
| Fabric-подход | Не только point-to-point | Можно строить более сложные топологии |
| Peer-to-peer | Устройства общаются напрямую | Меньше лишнего участия хоста |
| Многоуровневая коммутация | Несколько уровней коммутации | Масштабирование fabric |
| Shared memory access | Несколько хостов к общему ресурсу | Гибче pooling и сервисные сценарии |
| Улучшенное fabric management | Стандартное управление | Меньше зависимости от кастомного ПО |
| Масштабирование топологии | Больше устройств в fabric | Путь к composable memory |
| Скорость 64 ГТ/с | На базе PCIe 6.0 | Выше пропускная способность без роста задержки |
Текстовая интерпретация: в версии 3.0 новый стандарт получил поддержку скорости 64 ГТ/с, при этом без повышения задержки. Основные усилия разработчиков были сконцентрированы на дальнейшем развитии идей дезагрегации ресурсов и создания компонуемой инфраструктуры. — CXL Consortium (2022). CXL 3.0 Specification
Если свести различия к практическому смыслу:
| Версия | Основная идея | Практический смысл |
|---|---|---|
| CXL 1.1 | Базовая когерентная связка CPU и устройства | Фундамент для CXL.io, CXL.cache, CXL.mem |
| CXL 2.0 | Расширение в сторону memory expansion и switch-based топологий | Подключение внешней памяти и первые сценарии pooling |
| CXL 3.0 | Fabric, peer-to-peer, более развитое sharing и многоуровневая коммутация | Масштабирование на несколько хостов и более гибкая общая память |
Почему CXL стал важен для серверов нового поколения
CXL стал важен для серверов нового поколения потому, что производительность процессоров и ускорителей растёт быстрее, чем удобство и экономика доступа к памяти.
Узкое место сместилось.
Не всегда не хватает вычислительных мощностей — часто не хватает ёмкости памяти, гибкости её распределения и нормального обмена данными между CPU, GPU и памятью.
CXL помогает устранять «памятные стены», когда рост вычислений опережает рост пропускной способности памяти. Для AI, машинного обучения и обработки больших данных память сервера часто становится не просто ресурсом, а ограничителем дизайна всей системы.
Вот типовой кейс из практики проектирования инфраструктуры. В системе под аналитическую платформу хватает CPU и SSD. Но рабочий набор данных не помещается в локальную DRAM каждого узла. Команда либо переплачивает за более жирные конфигурации на всех серверах, либо начинает дробить задачи и терять производительность на обмене. CXL интересен как третий путь: расширить систему памяти и распределять ресурсы памяти гибче.
Как устроен интерфейс CXL: PCIe, CXL.io, CXL.cache и CXL.mem
Интерфейс CXL устроен как надстройка над физическим уровнем PCI Express, где линии PCIe дают транспорт, а протоколы CXL задают модель работы с устройством, кэшем и памятью.
Если проще: PCIe отвечает за дорогу, а CXL — за правила движения и типы грузов.
CXL состоит из трёх протоколов:
- CXL.io — инициализация, конфигурация, служебный обмен;
- CXL.cache — доступ к кэшируемым данным и когерентность;
- CXL.mem — доступ хоста к памяти на CXL-устройстве.
Это важное место. Многие путают и думают, что CXL — это просто «память по PCIe». Нет. Если бы дело было только в транспортной линии, стандарт не стал бы такой большой темой для современных серверных платформ.
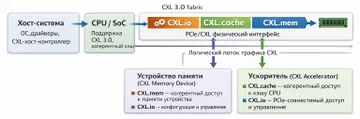
Текстовая расшифровка схемы:
- Хост — серверная система с root complex.
- CPU — центральный процессор, который управляет локальной DRAM и работает с устройствами CXL.
- Устройство памяти — Type 3 device, даёт расширенную ёмкость памяти через CXL.mem.
- Ускоритель — Type 1 или Type 2 device, может участвовать в когерентной работе с памятью.
- PCIe — физическая основа передачи данных.
- CXL.io — конфигурация и управление.
- CXL.cache — когерентный доступ к кэшу и памяти процессора.
- CXL.mem — доступ к памяти на устройстве.
Типы устройств CXL
| Тип устройства | Что это | Типичный сценарий |
|---|---|---|
| Type 1 | Ускоритель без собственной большой памяти | SmartNIC, некоторые ускорители |
| Type 2 | Ускоритель с собственной памятью | GPU/AI-ускорители и близкие классы устройств |
| Type 3 | Memory device / expander | Memory expansion, memory tiering, pooling |
Как работает когерентность и доступ к памяти
Когерентность в CXL нужна затем, чтобы устройство и центральный процессор работали с согласованным представлением данных, а не с дубликатами, разъехавшимися по разным буферам.
Практический эффект — меньше лишнего копирования данных, меньше задержек на синхронизацию и более предсказуемая работа памяти в одной системе.
Принцип такой: если ускоритель, SmartNIC или иное устройство CXL должно обращаться к данным, которые уже участвуют в работе CPU, система через CXL.cache и связанные механизмы когерентности добивается того, чтобы стороны видели согласованное состояние памяти. За счёт этого можно обращаться к памяти без постоянного создания новых копий данных для каждого устройства.
Где это полезно:
- при работе CPU и GPU с общими наборами данных;
- при обмене параметрами моделей в задачах машинного обучения;
- в сценариях, где стоимость копирования данных заметно влияет на latency;
- в системах с несколькими устройствами, работающими с одной памятью.
«Теперь помимо эксклюзивного доступа к памяти из пула доступен и общий доступ сразу нескольких хостов к одному блоку памяти, причём с аппаратной поддержкой когерентности». — CXL Consortium (2022). CXL 3.0 Specification.
Если ваша задача упирается в микросекунды на межпроцессорных синхронизациях и жёстко заточена под локальную DRAM, CXL не волшебная таблетка. Но если проблема — раздробленная память и тяжёлое копирование данных между устройствами, стандарт может реально помочь.
Как CXL связан с PCIe и обратной совместимостью
CXL связан с PCIe напрямую: PCI Express — это физическая база, поверх которой работает интерфейс CXL. Обратная совместимость важна, потому что она снижает барьер внедрения — не надо изобретать новый физический разъём и новую электрическую основу с нуля.
PCIe является физической основой, а CXL добавляет то, чего обычному интерфейсу ввода-вывода не хватает для памяти и когерентности.
Но здесь есть ограничение.
Обычный PCIe и CXL — не одно и то же:
- PCIe отлично подходит для классического ввода-вывода;
- CXL нужен там, где важны протоколы CXL, доступ к памяти и когерентность;
- наличие PCIe-слота ещё не означает поддержку CXL;
- поддержку определяет платформа, CPU, контроллеры, BIOS/UEFI и весь стек.
Это часто недооценивают в закупках. Видят красивую строчку «PCIe Gen5/Gen6», а потом выясняется, что для CXL memory pooling не хватает поддержки на уровне платформы и программного обеспечения.
Что меняет CXL 3.0 в работе с памятью
CXL 3.0 меняет главное: память перестаёт быть строго локальным приложением к одному процессору и становится более гибким инфраструктурным ресурсом.
Для серверов это означает memory pooling, memory expansion, более удобное объединение памяти и возможность строить общую память там, где раньше всё держалось на жёсткой привязке к сокету и каналам памяти CPU.
Именно поэтому стандарт так интересен для дата-центров. Не только потому, что можно добавить памяти объёмом больше. А потому, что можно иначе управлять ресурсами памяти и использовать их ближе к реальной рабочей нагрузке.
| Сценарий | Что выбрать | Почему |
|---|---|---|
| Минимальная задержка критична | Локальная DDR5 | Лучший latency |
| Не хватает объёма памяти на узле | CXL memory expansion | Расширяет ёмкость без замены всей платформы |
| Нагрузка скачет между узлами | Pooling через CXL | Лучшее использование памяти |
| AI/HPC с несколькими ускорителями | CXL + coherent architecture | Меньше избыточных копирований |
| ПО не готово к tiered memory | Пока локальная DRAM/NUMA-оптимизация | Меньше риск внедрения |
| Подход | Ёмкость памяти | Пропускная способность | Задержка | Гибкость конфигурации |
|---|---|---|---|---|
| Локальная DDR5 | Ограничена каналами памяти и слотами CPU | Наивысшая для локального доступа | Минимальная | Низкая: память жёстко привязана к серверу |
| Память через CXL | Расширяет ёмкость вне локальных DIMM | Ниже локальной DRAM, зависит от интерфейса и устройства | Выше локальной DRAM | Средняя: можно масштабировать память отдельно |
| Pooling памяти через CXL | Общий пул для нескольких хостов | Зависит от fabric и политики доступа | Выше локальной DRAM, чувствительна к топологии | Высокая: ресурсы памяти распределяются по спросу |
Практическая интерпретация простая. Если нужен минимальный latency — локальная DRAM остаётся базой. Если важны гибкость, расширение ёмкости и совместное использование ресурсов, CXL memory даёт новые сценарии, которых у классической схемы нет.
Pooling памяти и совместного использования ресурсов
Pooling памяти в CXL — это модель, при которой один пул ресурсов памяти может обслуживать несколько хостов или задач.
Главная ценность здесь не в красивом термине, а в снижении доли простаивающей памяти, когда один сервер перегружен, а на другом DRAM стоит полупустой.
Типовой сценарий выглядит так:
- в стойке есть несколько серверов с разной нагрузкой;
- часть задач чувствительна к объёму памяти, а не к пиковому CPU;
- через CXL и коммутаторы CXL создаётся пул памяти;
- хосты получают доступ к этому ресурсу по мере необходимости.
Вот где CXL 3.0 интересен по-настоящему. Не в абстрактной фразе «позволяет повысить эффективность», а в возможности не покупать одинаково раздутые конфигурации на все узлы заранее.
Маленький кейс. В кластере обработки данных один узел регулярно упирается в память, а два соседних сервера простаивают по DRAM. При классической архитектуре команда либо мигрирует нагрузку, либо покупает более дорогой узел. При pooling памяти ресурс можно распределять между несколькими хостами гибче. Результат — лучшее использование общей памяти без немедленного апгрейда всего кластера.
Memory expansion и память на устройстве
Memory expansion через CXL — это способ увеличить ёмкость памяти сервера не только за счёт DIMM в каналах памяти CPU, но и за счёт внешних CXL-устройств памяти.
Это особенно полезно там, где нужно больше памяти объёмом, но нет смысла или возможности масштабировать сам процессорный сокет.
Важно понимать trade-off:
- плюс — можно расширять систему памяти отдельно от CPU;
- плюс — можно строить более гибкие серверные платформы;
- минус — такая память не идентична локальной DRAM по задержкам;
- минус — реальный эффект зависит от программного обеспечения и типа нагрузки.
Это хороший инструмент для серверных систем, где узкое место — ёмкость памяти, а не только её абсолютная локальная скорость.
Производительность CXL 3.0: миф и реальность
Миф и реальность о производительности CXL
- Миф: CXL быстрее локальной DRAM.
Реальность: Локальная DRAM обычно остаётся лучшим вариантом по latency. - Миф: CXL автоматически ускоряет любую серверную нагрузку.
Реальность: Выигрыш появляется, когда ограничение связано с ёмкостью, копированием данных или гибкостью распределения памяти. - Миф: PCIe Gen5/Gen6 = готовность к CXL.
Реальность: Нужна поддержка CPU, платформы, firmware и ПО.
CXL 3.0 может улучшить производительность системы там, где проблема лежит в архитектуре доступа к памяти и в использовании ресурсов, а не только в сырой latency локальной DRAM. Но он не отменяет физику: пропускную способность, задержки и узкие места всё равно надо считать по конкретной топологии.
CXL не заменяет DRAM полностью. Высокая пропускная способность не означает минимальные задержки. Bottleneck может оставаться на стороне CPU, NUMA-топологии, коммутатора, устройства CXL или программного обеспечения.
Где CXL ускоряет работу, а где уступает локальной DRAM
CXL ускоряет работу там, где системе не хватает ёмкости памяти, гибкости её распределения или эффективного обмена между CPU, GPU и памятью. Локальной DRAM он уступает в сценариях, где критична минимальная задержка доступа и всё завязано на горячий рабочий набор рядом с ядрами процессора.
Выигрывают от CXL:
- базы данных и аналитические системы с большим рабочим набором;
- AI и машинное обучение, где важны память и ускорители в общей архитектуре;
- облачные и виртуализованные среды с неравномерным использованием памяти;
- HPC-задачи, которые хотят больше общей памяти, чем удобно держать локально.
Уступает локальной DRAM:
- latency-sensitive транзакционные контуры;
- некоторые NUMA-чувствительные приложения;
- нагрузки, где каждый лишний скачок задержки бьёт по throughput сильнее, чем дефицит ёмкости;
- задачи, плохо адаптированные к tiered memory.
Память с низкой задержкой в классическом смысле — это по-прежнему локальная DRAM, а CXL-память — это компромисс между скоростью, ёмкостью и гибкостью.
От чего зависит реальный эффект в серверных системах
Реальный эффект CXL 3.0 зависит не от логотипа стандарта, а от всей конфигурации: какие стоят процессоры Intel или AMD EPYC, сколько у них каналов памяти, как построена топология, какие устройства CXL подключены и умеет ли программное обеспечение использовать такую систему памяти.
Ключевые факторы:
- поддержка CXL у платформы;
- поколение серверных процессоров;
- число каналов памяти и базовая пропускная способность локальной DRAM;
- тип устройства CXL;
- наличие коммутаторов CXL;
- характер рабочей нагрузки;
- поддержка со стороны ОС и прикладного ПО.
Если в системе уже не CPU bottleneck, а память сервера и обмен данными между устройствами, CXL может повысить эффективность. Если bottleneck в приложении, которое не умеет работать с tiered memory, новый стандарт не спасёт.
Короткий кейс. Заказчик хочет «увеличить производительность» за счёт CXL. На обследовании выясняется: память забита лишь местами, а главная проблема в неоптимальном софте и I/O. Команда сначала профилирует нагрузку, затем меняет схему размещения данных и только потом рассматривает memory expansion. Результат — экономия бюджета и отказ от красивого, но бесполезного апгрейда.
Где CXL 3.0 используют на практике: AI, HPC, базы данных и облако
CXL 3.0 полезен там, где рабочая нагрузка требует большой, гибкой и лучше распределяемой памяти, а также тесной связки CPU, GPU и других ускорителей.
На практике это прежде всего искусственный интеллект, машинное обучение, высокопроизводительные вычисления, базы данных и облачные платформы.
Архитектурные сценарии понятны и логичны, хотя публичных production-бенчмарков пока немного.
CPU, GPU и ускорители в общей памяти
CXL интересен для связки CPU, GPU и ускорителей потому, что помогает уменьшать копирование данных и строить более тесное взаимодействие между памятью и другими устройствами в одной системе.
Для задач искусственного интеллекта это особенно важно: веса моделей, батчи данных, промежуточные буферы и результаты инференса постоянно перемещаются между компонентами.
Когда в архитектуре есть только разрозненные острова памяти, CPU и графического процессора тратят время не только на вычисления, но и на перемещение данных. CXL позволяет процессорам и ускорителям работать с памятью ближе к общей модели адресации и согласованности. — Подтверждено спецификацией CXL 3.0
Это не значит, что исчезают все копирования. Не исчезают. Но в сравнении с более жёстко разорванной архитектурой CXL открывает новые сценарии для AI-кластеров и больших языковых моделей.
Почему это особенно важно для дата-центров
Для дата-центров CXL важен потому, что позволяет эффективнее использовать вычислительные ресурсы и ресурсы памяти на уровне стойки и платформы, а не только отдельного сервера.
Откуда вообще берётся эффект:
- меньше простаивающей памяти;
- меньше избыточного overprovisioning на каждом узле;
- более гибкие конфигурации серверных платформ;
- возможность строить инфраструктуру под разные типы нагрузки;
- более длинный жизненный цикл части серверов за счёт memory expansion.
Для современных дата-центров это особенно важно в средах, где одновременно живут базы данных, AI-задачи, аналитика и виртуализованные сервисы. Там память почти всегда распределена неравномерно.
Экосистема CXL 3.0: процессоры, устройства памяти и коммутаторы
Экосистема CXL 3.0 состоит из трёх больших частей: платформы с поддержкой стандарта, сами устройства CXL и fabric-компоненты для более сложных топологий.
Без этой тройки стандарт остаётся красивой теорией.
| Класс устройства | Роль | Что даёт | На что влияет в конфигурации |
|---|---|---|---|
| Процессор с поддержкой CXL | Хост и управляющая точка | Поддержка CXL.io, CXL.cache, CXL.mem | Совместимость платформы и режимы работы |
| Memory expander / Type 3 | Расширение памяти | Дополнительная ёмкость памяти через CXL.mem | Объём, latency-tier, модель размещения данных |
| Ускоритель / Type 1-2 | Вычисления и работа с памятью | Когерентная работа CPU и устройства | AI, HPC, обмен данными и копирования |
| Коммутатор CXL | Fabric и маршрутизация | Подключение нескольких хостов и устройств | Масштабирование, pooling памяти, сложные топологии |
Поддержка у Intel Xeon и AMD EPYC
Поддержка CXL у Intel Xeon и AMD EPYC — это не просто галочка в спецификации, а набор практических ограничений для конфигурации сервера.
Именно процессор и платформа определяют, сможете ли вы использовать интерфейс CXL, какие режимы будут доступны и насколько далеко можно зайти в memory expansion или pooling.
Для CXL нужна поддержка со стороны CPU, материнской платы и BIOS. Нужно учитывать, какие именно функции стандарта доступны на платформе. Поддержка CXL memory и поддержка продвинутой fabric-топологии — не всегда одно и то же. — Зависит от реализации
Для технических специалистов это означает простую вещь: нельзя читать маркетинговую строчку «supports CXL» без расшифровки. Надо уточнять уровень поддержки, типы устройств, режимы адресации, ограничения по числу устройств и совместимость с ОС.
Коммутация, несколько хостов и сложные топологии
Коммутация в CXL 3.0 нужна затем, чтобы выйти за пределы простой прямой связки «один хост — одно устройство» и строить fabric с несколькими хостами, несколькими устройствами и общей системой памяти.
Это как раз то, что делает стандарт интересным для серверных систем нового поколения.
«Одно из ключевых новшеств — многоуровневая коммутация. Теперь топология фабрики CXL 3.0 может быть практически любой, от линейной до каскадной с группами коммутаторов, подключенных к коммутаторам более высокого уровня». — CXL Consortium (2022). CXL 3.0 Specification.
Многоуровневые коммутаторы CXL Fabric позволяют строить иерархическую топологию и масштабировать сеть до тысяч устройств через Tiered Switches, PBR и GBR-маршрутизацию. Возможность адресовать до 4096 устройств в рамках такой fabric-модели. — CXL 3.0 Specification (2022); CXL 3.1 Update (2024). Требует проверки по реализации
Это важный момент, но я бы не превращал его в лозунг. Возможность теоретического масштабирования и реальная эксплуатационная готовность — разные вещи. Особенно в enterprise, где важны отказоустойчивость, диагностика и предсказуемое поведение под нагрузкой.
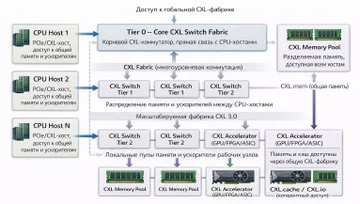
«Сочетание новых возможностей выводит идею разделения памяти и вычислительных ресурсов на новый уровень: теперь возможно построение систем, где единый пул подключенной к фабрике CXL 3.0 памяти (Global Fabric Attached Memory, GFAM) действительно существует отдельно от вычислительных модулей». — CXL Consortium (2022). CXL 3.0 Specification.
Ограничения и перспективы CXL 3.0 в ближайшем будущем
CXL 3.0 — перспективный стандарт, но массовое внедрение тормозят стоимость, сложность платформ, незрелость части программного обеспечения и практические риски многохостовых конфигураций.
То есть технология может стать основой следующих поколений серверов, но путь к этому не мгновенный.
Что нужно учитывать перед внедрением
Перед внедрением CXL надо оценить рабочую нагрузку, требования к latency и пропускной способности памяти, совместимость платформы и совокупную стоимость владения.
Если этого не сделать, можно купить модную технологию и не получить полезного эффекта.
Проверочный список для CTO, CIO и архитекторов:
- Какая проблема решается: нехватка ёмкости памяти, узкие места обмена данными, плохое использование ресурсов или всё сразу?
- Нужна ли память с низкой задержкой локального класса, или допустим memory tier с более высоким latency?
- Есть ли у платформы реальная поддержка CXL, а не только PCIe?
- Какие типы устройств CXL поддерживаются?
- Есть ли план по поддержке со стороны ОС, гипервизора и приложений?
- Что будет с отказоустойчивостью и диагностикой в многохостовой схеме?
- Что выгоднее по TCO: больше локальной DRAM, CXL memory expansion или гибрид?
Коротко. Если вопрос звучит как «можно ли просто добавить CXL и всё ускорится?», ответ — нет.
| Ограничение | Где болит | Что проверить |
|---|---|---|
| Более высокая задержка vs DRAM | Latency-sensitive приложения | Профиль доступа к памяти |
| Незрелость ПО | ОС/гипервизор/приложения | Поддержка tiered memory и NUMA |
| Сложность fabric | Multi-host конфигурации | Отказоустойчивость и диагностика |
| Совместимость платформы | CPU/BIOS/board | Матрица поддержки |
| Экономика внедрения | Закупка и эксплуатация | Сравнение с «больше локальной DRAM» |
Как может развиваться стандарт дальше
Дальше CXL, вероятно, будет развиваться в сторону более зрелой fabric-архитектуры, новых контроллеров, лучшей поддержки программного обеспечения и более понятных сценариев для серверов нового поколения.
Именно там лежит его будущее: не только в подключении внешней памяти, но и в перестройке вычислительной инфраструктуры под более гибкие пулы ресурсов.
Стандарт может стать основой для следующих поколений серверов. Для AI, облака, HPC и больших данных направление очевидное: вычислительные системы становятся всё более гетерогенными, и старая модель «вся память строго рядом с одним CPU» масштабируется всё хуже.
«В настоящее время группа CXL уже включает 206 участников, в число которых входят компании Intel, Arm, AMD, IBM, NVIDIA, Huawei, крупные облачные провайдеры, включая Microsoft, Alibaba Group, Google и Meta, а также ряд крупных производителей серверного оборудования, в том числе, HPE и Dell EMC». — CXL Consortium (2022).
CXL может оказаться не универсальным ответом, а важным, но нишевым инструментом для части серверных платформ. Если программное обеспечение не догонит железо, а внедрение останется дорогим и сложным, часть сценариев так и останется за локальной DDR5, NUMA-оптимизацией и более традиционным масштабированием.
Это нормально. Не каждая сильная технология должна заменить всё вокруг. Иногда она просто закрывает большой класс проблем лучше, чем старые инструменты.
Список источников и материалов для проверки темы
Ниже — перечень источников, которые прямо упомянуты во входных исследованиях и на которые в этой статье можно опираться как на рамку проверки:
- CXL Consortium — CXL 3.0 Specification (2022).
- Compute Express Link Consortium — CXL 3.1 Update (2024).
- PCI-SIG — спецификации PCI Express 5.0/6.0. PCI-SIG — спецификации PCI Express 5.0/6.0.
- Материалы производителей платформ и процессоров: Intel, AMD
- Техническая документация по серверной памяти и memory expansion от поставщиков серверных решений
Для части вопросов по 2025 году, по точным benchmark-метрикам latency, TCO и product ecosystem рекомендуется дополнительный поиск по первоисточникам. Для инженерного решения это правильный путь.