

Графический процессор (GPU) — это специализированный чип, предназначенный для массовой параллельной обработки данных. Изначально он создавался для ускорения 3D-графики и визуальных эффектов: растеризации, шейдинга, постобработки. Сегодня GPU используются не только в играх; их применяют для видеообработки, научного моделирования, обучения нейросетей и других сложных вычислений. GPU для рабочих станций и дата-центров оснащаются большим объемом памяти (VRAM) и обладают повышенной надежностью. Они предназначены для задач, где массивные однородные вычисления критичны.
При работе с матричными операциями, симуляциями и аналитикой такой процессор сокращает время вычислений, тогда как в задачах с последовательной логикой эффективнее использовать центральный процессор (CPU). Как отмечают в руководстве Kvantech «Графический процессор: полное руководство», главная задача GPU — выполнять огромное количество параллельных вычислений. Эту же мысль подтверждает и глоссарий Yandex Cloud, где GPU определяется как компонент, ускоряющий расчеты с однотипной формулой.
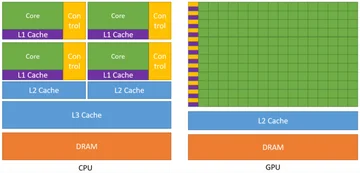
Как работает GPU: архитектура и принцип работы современных GPU
Современные GPU работают по модели массового параллелизма: сотни и тысячи вычислительных ядер исполняют одинаковые инструкции над разными порциями данных. Архитектура GPU включает в себя потоковые мультипроцессоры (SM) и иерархическую систему памяти: регистры, кэши и высокоскоростную видеопамять (VRAM) типа GDDR или HBM. В одном чипе сосуществуют графический конвейер для растеризации и трассировки лучей и вычислительный конвейер для универсальных вычислений (GPGPU), что делает GPU универсальным инструментом.
Также в современных GPU используются специализированные блоки: тензорные и матричные ускорители, RT-ядра для трассировки лучей, аппаратные медиа-кодеки и интерфейсы для подключения дисплеев. Работает GPU через обмен данными по шине PCIe, а для объединения нескольких ускорителей служат высокоскоростные межсоединения вроде NVLink. Производительность и стабильность работы GPU зависят от драйверов и планировщиков, которые управляют очередями и потоками задач.
Ключевые элементы:
- Потоковые мультипроцессоры (SM/CU) и модель вычислений SIMT/SIMD.
- Иерархия памяти: регистры, кэши L1/L2, видеопамять (VRAM) типов GDDR/HBM.
- Пайплайны: графический (растеризация/RT) и вычислительный (CUDA/HIP/ROCm/Vulkan Compute).
- Специализированные блоки: тензорные, матричные и RT-ядра, аппаратные видеокодеки.
- Межсоединения: PCIe, NVLink, технология Resizable BAR.
- Драйверы и планировщики: управление потоками и очередями выполнения задач.
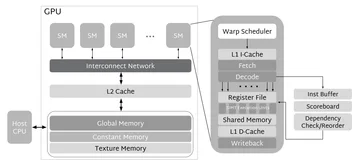
Техническая достоверность подтверждается официальными документами, такими как whitepapers по архитектурам NVIDIA Ada Lovelace и Hopper, технические спецификации AMD RDNA и CDNA, а также материалы Intel по архитектуре Xe HPG и программному стеку oneAPI. Спецификации графических API Vulkan и DirectX детально описывают взаимодействие программного обеспечения с аппаратной частью.
Для чего нужна GPU: что можно сделать и где используют
GPU предназначены для задач, где критичны параллельные операции. GPU для игр повышает частоту кадров (FPS) и снижает задержку. GPU для рендеринга сокращает время отрисовки кадра и ускоряет предварительный просмотр. GPU для ИИ ускоряет обучение моделей и их последующий инференс. Также GPU используются в научных вычислениях, кодировании видео, визуальной аналитике данных, а также в приложениях виртуальной (VR) и дополненной (AR) реальности.
Класс операций, которые эффективно ускоряются на GPU: матричные умножения, шейдинг, фильтрация изображений, декодирование видео, сортировки и редукции. Выигрыш в производительности достигается там, где одна и та же операция повторяется многократно для большого массива данных. Для последовательных алгоритмов с множеством ветвлений или задач, ограниченных скоростью ввода-вывода, GPU не подходит.
GPU для визуализации и для рендеринга изображений
GPU ускоряет визуализацию сложных сцен и рендеринг изображений как в реальном времени, так и в офлайн-режиме. Растеризация, постэффекты и трассировка лучей выполняются на GPU значительно быстрее, чем на CPU при сопоставимом бюджете. Для визуализации в бизнес-аналитике и научных исследованиях ускоритель обрабатывает объемные наборы данных и интерактивные панели.
В пакетах для создания цифрового контента (DCC) поддержка рендеринга на GPU сокращает количество итераций и повышает качество предварительного просмотра. Наличие тензорных ядер позволяет применять технологии интеллектуального масштабирования (апскейлинга) и шумоподавления для улучшения итогового изображения.
Примеры применения:
- Рендеринг изображений в Blender Cycles X и Redshift.
- Трассировка лучей в реальном времени в играх и платформах для создания цифровых двойников, таких как NVIDIA Omniverse.
- Объемная визуализация в медицине для анализа томографических снимков.
- Создание визуальных эффектов (VFX) и композитинг.
- Для рендеринга изображений в CAD-системах и архитектурной визуализации.
- Визуальная аналитика больших данных с помощью библиотек Plotly и VisGL/WebGL.
- Нейросетевой апскейлинг и денойзинг с использованием технологий DLSS и их аналогов.

GPU для вычислений: параллельная обработка данных на GPU
GPU для вычислений применяется там, где в алгоритмах доминируют матрично-векторные и тензорные операции. Программный код переносит тяжелые вычислительные ядра (kernels) на устройство (device), минимизируя обмен данными с центральным процессором (host). Эффективность вычислений на GPU достигается за счет коалесцированного доступа к памяти и использования смешанной точности (FP16, BF16, FP8) с контролем ошибок редукции.
Наибольшая отдача получается при высокой арифметической интенсивности, когда кэш и VRAM успевают снабжать вычислительные блоки данными. Практически всегда полезны библиотеки с оптимизированными ядрами и планировщиками, такие как cuBLAS, cuDNN, oneDNN и MIOpen, так как они уже содержат высокопроизводительные реализации стандартных математических операций.

GPU и сети: ускорение сетей для обучения и инференса
GPU ускоряют работу сверточных нейронных сетей (CNN), трансформеров и мультимодальных моделей. Большие размеры батчей, смешанная точность вычислений и использование тензорных ядер дают основной выигрыш в производительности. При работе с GPU и сетями важен правильный выбор типа данных (dtype), слияние (fusion) нескольких операций в одну и удержание данных в памяти для исключения лишних копирований. В промышленной эксплуатации полезны оптимизаторы графов вычислений и специализированные движки исполнения, такие как TensorRT и ONNX Runtime. Для распределенного обучения на нескольких GPU применяются технологии NCCL, ZeRO и FSDP.
| Режим | Скорость | Качество | Где применять |
|---|---|---|---|
| FP32 | Базовая | Высокая точность | Исследования, критичные к точности вычислений |
| BF16 | Быстрее FP32, экономит VRAM | Близка к FP32 в обучении | Обучение крупных моделей |
| FP16 | В 1.5–2 раза быстрее FP32 | Приемлемая потеря точности | Обучение и инференс CNN и Transformer |
| FP8 | Максимальное ускорение | Снижение точности, нужны методы компенсации | Обучение и инференс, где важен throughput |
| INT8 | Очень высокая, минимум памяти | Возможна деградация качества | Инференс в реальном времени и на периферийных устройствах |
GPU для 1С: есть ли польза и когда это нужно
Для стандартных задач в 1С, таких как проведение транзакций и формирование отчетов, GPU не используется, и его наличие не ускоряет работу. Профиль нагрузки в таких сценариях зависит от производительности CPU и дисковой подсистемы. GPU не приносит пользы для 1С, если речь идет о типовых операциях.
Польза возможна лишь в редких случаях, таких как интеграция с внешними аналитическими модулями или при визуализации сложной 3D-графики в специализированных конфигурациях. Ощутимый эффект достигается при вынесении моделей машинного обучения за пределы 1С и подключении их как внешних сервисов. Для серверов, работающих с 1С, рациональная инвестиция — это мощный CPU, большой объем оперативной памяти, быстрые SSD и оптимизация SQL-запросов.
ПО для GPU: инструменты и библиотеки для создания и работы на GPU
Программное обеспечение для GPU представляет собой стек из драйверов, API и фреймворков. Для создания вычислительных ядер используют CUDA, HIP, SYCL и соответствующие компиляторы. Для графики — DirectX, Vulkan, Metal. Для машинного обучения — PyTorch, TensorFlow, JAX и среды выполнения, такие как ONNX Runtime и TensorRT. Для эксплуатации важны профилировщики, средства мониторинга и системы оркестрации. Работа начинается с установки драйверов и SDK, затем выбирается API под задачу, после чего код профилируется и автоматизируется его развертывание.
Инструменты:
- CUDA, cuDNN, NCCL / HIP, ROCm / SYCL, oneAPI.
- Vulkan, DirectX 12, OpenGL (для совместимости).
- PyTorch, TensorFlow, JAX, Triton.
- ONNX Runtime, TensorRT, OpenVINO (для дискретных GPU).
- Научные библиотеки: cuBLAS, cuFFT, Thrust, MIOpen, oneDNN.
- Профилирование: Nsight, ROCm SMI, VTune, Perfetto.
- Видеостек: NVENC, AMF, QuickSync в связке с FFmpeg.
- Оркестрация: Kubernetes с GPU-операторами.
| Задача | Инструменты | Вендор | ОС | Лицензия |
|---|---|---|---|---|
| Обучение DNN | PyTorch, cuDNN, NCCL | NVIDIA | Linux, Windows | Open Source и проприетарные SDK |
| Инференс | TensorRT, ONNX Runtime | NVIDIA, ONNX | Linux, Windows | Proprietary и OSS |
| Графика | Vulkan, DirectX 12 | Khronos, Microsoft | Linux, Windows | Спецификации открыты |
| Вычисления | CUDA, HIP, SYCL | NVIDIA, AMD, Intel | Linux, Windows | Смешанная |
| Профилинг | Nsight Systems, VTune | NVIDIA, Intel | Linux, Windows | Proprietary |
| Видео | NVENC, AMF, Quick Sync, FFmpeg | NVIDIA, AMD, Intel | Linux, Windows | Смешанная |
| Оркестрация | Kubernetes GPU Operator | NVIDIA | Linux | Open Source |
Современные GPU: основные характеристики и возможности
Современные GPU характеризуются высокой плотностью вычислительных блоков, наличием специализированных тензорных и RT-блоков, глубокой иерархией кэшей и скоростной видеопамятью. Архитектура GPU поддерживает смешанные точности вычислений (BF16, FP16, FP8), содержит ускорители для механизма внимания в трансформерах, аппаратные кодеки формата AV1, а также интерфейсы DisplayPort 2.1 и HDMI 2.1.
В дата-центрах GPU используются с межсоединениями NVLink и технологиями виртуализации MIG или vGPU. На настольных компьютерах применяются шины PCIe 4.0/5.0 и технология Resizable BAR. Современные GPU ориентированы на максимальный throughput (пропускную способность) и энергоэффективность, а также на сближение графических и вычислительных задач.
Характеристики:
- VRAM типа GDDR6, GDDR6X, GDDR7 и HBM2e, HBM3e с широкой шиной.
- Тензорные, матричные и RT-ядра, поддержка форматов FP8 и INT8.
- Высокая пропускная способность памяти и большой объем кэша L2.
- Медиа-блоки с поддержкой AV1 и многопоточными энкодерами.
- Дисплейные интерфейсы DP 2.1 и HDMI 2.1 с поддержкой DSC и VRR.
- Межсоединения PCIe 5.0/6.0, NVLink.
- Технологии виртуализации MIG, vGPU, SR-IOV.
Будущее GPU
Будущее GPU связано с переходом на многокристальные дизайны (чиплеты) и технологию 3D-стекирования, что позволяет интегрировать процессорные ядра с памятью. По мере роста сложности моделей ускорители становятся гибридными, объединяя графические и ИИ-блоки. Появляются аппаратные решения для ускорения механизма внимания (attention) и распределенного обучения.
Современные GPU переходят к использованию формата FP8, что повышает производительность в задачах ИИ. Развиваются умные планировщики задач и интеграция с памятью через интерфейс CXL для расширения адресного пространства. Растет роль низколатентных межсоединений, таких как NVLink, CXL и PCIe 6.0. Для рабочих станций и дата-центров акцент смещается на энергоэффективность на ватт и функции надежности (RAS). Для потребительского сегмента будущее за интеллектуальными апскейлерами, генеративной графикой и кодеками следующего поколения.
GPU и CPU: когда что выбрать
GPU и CPU являются взаимодополняющими компонентами. CPU отвечает за сложную логику и последовательное выполнение задач, в то время как GPU обеспечивает массовый параллелизм для вычислений и рендеринга. Оптимальный подход заключается в комбинации обоих типов процессоров в зависимости от профиля нагрузки.
| Параметр | CPU | GPU |
|---|---|---|
| Тип нагрузки | Ветвистая и последовательная | Массовый параллелизм |
| Память | Мало каналов и низкая латентность | Высокая пропускная способность VRAM |
| Точность | FP64 и FP32 стабильно | BF16, FP16, FP8 и INT8 эффективно |
| Энергоэффективность | Выше на малых задачах | Выше на больших батчах и тензорах |
| Разработка | Универсальна | Нужны API и портирование |
| Стоимость | Ниже на сокет | Выше, но выше throughput |
| Кейсы | БД, бэкенд, 1С | ИИ, рендер, видео, HPC |
| Масштабирование | Сокеты и ядра | Multi-GPU и NVLink |
GPU не работает: типовые проблемы и решения
Если GPU не работает или приложение с ним падает, диагностика начинается с базовых проверок: питание, температура, драйверы и физическое подключение в слоте. Частые причины сбоев: нехватка видеопамяти (VRAM), конфликты драйверов или отсутствующие программные зависимости. На ноутбуках стоит проверить настройки MUX-переключателя, технологии Optimus и выбранный профиль питания. На серверах — корректность настроек IOMMU/SR-IOV и совместимость прошивок. Для диагностики используются утилиты `nvidia-smi` и `rocm-smi`, а также журналы событий операционной системы.
Решения:
- Чистая переустановка драйвера с использованием утилиты DDU в безопасном режиме.
- Проверка питания: корректное подключение коннекторов и соответствие мощности блока питания.
- Контроль температур и чистка радиаторов и вентиляторов от пыли.
- Проверка режима работы слота PCIe (x16) и обновление BIOS/UEFI материнской платы.
- Коррекция настроек приложения для снижения потребления VRAM (уменьшение батча, разрешения, включение постраничной подкачки).
- Отключение сторонних оверлеев и служб защиты, которые могут конфликтовать с драйвером.
- Обновление прошивки видеокарты (VBIOS) и firmware контроллеров на материнской плате.
- На ноутбуках: выбор профиля "Максимальная производительность" и настройка MUX-переключателя.

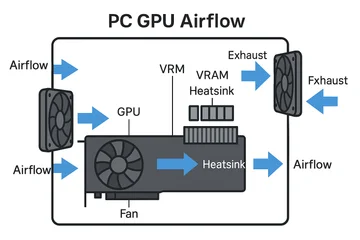
Требования для работы GPU: питание, охлаждение, драйверы
Для стабильной работы GPU необходим блок питания соответствующей мощности, качественные кабели питания, организованный воздушный поток в корпусе и актуальные драйверы. Чтобы GPU работал на полной скорости, убедитесь, что слот PCIe функционирует в режиме x16, а система охлаждения эффективно отводит тепло от чипов памяти (VRAM) и модуля регулятора напряжения (VRM). В серверах следите за совместимостью версий прошивок, ядра ОС и платформ CUDA или ROCm.
Чек-лист:
- Блок питания с запасом мощности 20–30% и необходимыми коннекторами.
- Чистые разъемы без перегибов и сомнительных переходников.
- Достаточный приток холодного и отвод горячего воздуха, чистые пылевые фильтры.
- Температуры ядра, горячей точки и видеопамяти находятся в пределах нормы под нагрузкой.
- Установлены актуальные драйверы и SDK для вашей операционной системы.
- Режим работы PCIe x16 или x8 подтвержден, технология Resizable BAR активирована при необходимости.
- BIOS/UEFI материнской платы, VBIOS видеокарты и драйверы чипсета обновлены до последних версий.
- Профили питания в ОС и ноутбуке установлены на "Максимальная производительность".
GPU в отраслях: примеры применения с GPU в реальных задачах
GPU используются в медицине для реконструкции томографических снимков и создания диагностических моделей, в производстве для визуального контроля качества и цифровых двойников, в медиа для рендеринга и транскодинга. С GPU в финтехе ускоряют оценку рисков и работу антифрод-систем, в логистике — оптимизацию маршрутов, в науке — моделирование и анализ данных. Цель всегда одна: сократить время до получения результата и повысить качество решений.
Практическое руководство по выбору GPU
Ключевой шаг — сопоставить требования задачи с параметрами GPU: объемом VRAM, пропускной способностью памяти, поддержкой API и энергобюджетом. В расчет совокупной стоимости владения (TCO) включается стоимость электроэнергии, уровень шума, цена лицензий на ПО и затраты на размещение в стойке. После выбора модели необходимо подтвердить совместимость и запустить профильный тест для оценки реальной производительности.
| Параметр | Что значит | Рекомендуемые значения |
|---|---|---|
| VRAM | Помещается ли модель или сцена | Игры 8–12 ГБ, 4K и RT 12–16 ГБ, ИИ инференс 12–24 ГБ, обучение 24–80 ГБ |
| Память | Пропускная способность | Игры от 400 ГБ/с, ИИ и HPC предпочитают широкую шину и HBM |
| Tensor и RT-ядра | Ускорение ИИ и трассировки | Наличие и актуальные версии FP8 и RT |
| API и фреймворки | Совместимость со стеком | CUDA или ROCm, Vulkan или DX12, нужные версии |
| Энергопотребление | Пиковый и средний TDP | Соответствие блоку питания и охлаждению |
| Форм-фактор | Габариты и слоты | Совместимость с корпусом или стойкой и притоком воздуха |
| Драйверы и поддержка | Стабильность и цикл обновлений | Профессиональные линии и LTS для продакшена |
| Стоимость и TCO | Цена владения | Энергия, шум, лицензии, место и обслуживание |
Производительность и бенчмарки
Спецификации предоставляют теоретические данные: количество ядер, тактовые частоты, объем и тип VRAM, пропускную способность, а также пиковую производительность в TFLOPS и TOPS. Реальная производительность зависит от программного стека, драйверов и узких мест платформы. Типы бенчмарков: синтетические (3DMark) для общей оценки графики, игровые сценарии, профессиональные (SPECviewperf) для САПР и DCC-приложений, и MLPerf для задач машинного обучения.
Узкие места производительности: недостаточная мощность CPU ("бутылочное горлышко"), ограничения пропускной способности шины PCIe, медленная системная память и неоптимизированные драйверы. Оптимизация включает использование профилировщиков, планировщиков задач, выбор подходящей точности вычислений и слияние вычислительных ядер (kernel fusion).
| Бенчмарк или метрика | Что измеряет | Когда использовать |
|---|---|---|
| 3DMark | Производительность в графике и трассировке лучей | Игровые и визуальные профили нагрузки |
| SPECviewperf | Производительность в DCC, CAD и других проф. приложениях | Оценка рабочих станций |
| MLPerf | Производительность в обучении и инференсе моделей ML | Сравнение систем для задач ИИ |
| FFmpeg throughput | Скорость транскодирования видео, в т.ч. в формате AV1 | Оценка производительности в видео и стриминге |
Методологии тестов доступны на официальных сайтах консорциумов MLCommons, SPEC и UL Benchmarks.
Энергоэффективность, тепловой режим и акустика
Показатели TDP (Thermal Design Power) и Power Limit определяют тепловую и электрическую мощность GPU. Эффективность на ватт влияет на стоимость владения и плотность вычислений в дата-центрах. При перегреве включается механизм троттлинга, который снижает тактовые частоты для предотвращения повреждения. Системы охлаждения бывают воздушными и жидкостными, в их конструкции применяются тепловые трубки и испарительные камеры. В ноутбуках используются схемы динамического перераспределения мощности между CPU и GPU, а также гибридная графика для снижения энергопотребления, шума и нагрева.
Типы и форм-факторы GPU
- Дискретные: отдельные платы PCIe формата 2, 2.5 или 3 слота для настольных ПК, требующие дополнительного питания и массивного охлаждения.
- Интегрированные: встроены в CPU или SoC, энергоэффективны, подходят для офисных задач и легкой графики.
- Виртуальные (vGPU): программные профили для сред виртуализации (VDI, HPC, AI), позволяющие делить ресурсы одного GPU между несколькими виртуальными машинами.
- Внешние (eGPU): подключаются по Thunderbolt или USB4, но их производительность ограничена пропускной способностью интерфейса.
- Мобильные и встраиваемые: решения для ноутбуков и компактных систем с технологиями MUX и Advanced Optimus, рассчитанные на строгий тепловой бюджет.
- Облачные: предоставляются как serviço (GPU-as-a-Service), оплата по времени использования, производительность зависит от качества сети и квот провайдера.

Частые ошибки и мифы
- Сравнение по одному параметру, например, по числу CUDA-ядер или TFLOPS. Реальная производительность определяется архитектурой, памятью и программным стеком.
- Недооценка объема VRAM и ее пропускной способности. Недостаток памяти приводит к резкому падению FPS и throughput.
- Игнорирование требований к блоку питания, охлаждению и габаритам. Это приводит к перегреву, троттлингу и нестабильной работе.
- Неверная интерпретация результатов бенчмарков. Важно понимать, что именно измеряет тест и какие узкие места есть в вашей системе.
- Путаница между GPU и графической картой. GPU — это чип, а графическая карта — это готовое устройство, состоящее из GPU, памяти, системы охлаждения и других компонентов.
Комментарии (0)
Новый комментарий
Новый комментарий отправлен на модерацию