

Когда в IT-ландшафте десятки систем, сотни алертов и постоянные изменения — проблема обычно не в нехватке мониторинга. Проблема в том, что сигнал тонет в шуме. AIOps как раз про это: не просто собирать данные, а понимать, что из них важно для IT-операций, где назревает сбой и что с ним делать.
Термин не новый. По данным Gartner, сам термин AIOps ввели в 2016 году в отчёте Solve IT Operations Problems With Artificial Intelligence.
«Gartner определил AIOps как платформы, которые комбинируют big data и машинное обучение для поддержки всех основных функций IT-операций через централизованное, автоматизированное решение». — Gartner, "Solve IT Operations Problems With Artificial Intelligence", 2016.
Позже Gartner уточнял определение: AIOps-платформы используют AI, ML и big data для автоматизации и улучшения IT-операций — переход от реактивного реагирования к проактивному управлению (Gartner, "Market Guide for AIOps Platforms", 2023). BMC и Forrester в своих материалах проводят ту же линию: от ручного firefighting к проактивному анализу, корреляции и автоматизации (BMC Software, "AIOps Whitepaper", 2022; Forrester, "The Forrester Wave: AIOps Platforms", 2021).
Что такое AIOps и зачем он нужен в управлении IT
AIOps — это подход и класс программных решений для управления IT-операциями, в котором искусственный интеллект, machine learning и анализ больших данных применяются к операционным данным. Главная задача AIOps — не просто показывать состояние систем, а автоматически находить аномалии, связывать события, подсказывать вероятную первопричину и ускорять реагирование на инциденты.
Если проще, AIOps нужен там, где традиционный мониторинг уже видит слишком много, но понимает слишком мало. В сложной IT-инфраструктуре — особенно в гибридных, облачных и микросервисных средах — у команд возникает не дефицит сигналов, а дефицит контекста.
Именно этот разрыв AIOps и закрывает.
«AIOps трансформирует IT-операции с реактивного мониторинга в проактивное управление, используя искусственный интеллект для автоматизации root cause analysis и предотвращения инцидентов до их влияния на бизнес». — DevOps Institute, "AIOps Fundamentals", 2023.
Gartner, BMC, Forrester и DevOps Institute сходятся в одном: AIOps помогает перейти от реактивного подхода к проактивному управлению IT.
- AIOps
- Подход к управлению IT-операциями, где AI, machine learning и аналитика данных помогают выявлять аномалии, коррелировать события и автоматизировать реакции.
- Machine learning
- Методы машинного обучения, которые строят модели на исторических данных и находят паттерны без ручного описания всех правил.
- Observability
- Наблюдаемость: способность понимать внутреннее состояние системы по телеметрии — логам, метрикам, трассировкам и событиям.
- RCA
- Root Cause Analysis, анализ первопричин: поиск исходной причины инцидента, а не только его симптомов.
- MTTR
- Mean Time To Repair/Resolve: среднее время восстановления или решения инцидента.
- Корреляция событий
- Связывание разрозненных событий из разных систем в единую картину одного инцидента или деградации.
- Предиктивная аналитика
- Анализ исторических и текущих данных для прогнозирования вероятных сбоев, аномалий и пиков нагрузки.
Чем AIOps отличается от традиционного мониторинга
Традиционный мониторинг в основном отвечает на вопрос «что сломалось или вышло за порог». AIOps отвечает на более полезный вопрос: «что здесь на самом деле происходит, почему это важно и что делать дальше».
Обычные инструменты мониторинга хорошо собирают логи, метрики, оповещения. Но при росте числа компонентов инфраструктуры, приложений и сервисов они начинают генерировать информационный шум. Особенно если среда меняется быстро: релизы, контейнеры, ephemeral-инстансы, новые зависимости между сервисами.
Вот где разница особенно заметна:
| Традиционный мониторинг | AIOps |
|---|---|
| Смотрит на отдельные метрики и пороги | Анализирует данные и события в связке |
| Реагирует после срабатывания алерта | Поддерживает проактивное управление |
| Плохо справляется с шумом | Использует корреляцию событий и приоритизацию |
| Требует много ручных операций | Автоматизирует анализ и часть реагирования |
| Часто показывает симптомы | Пытается найти корневые причины |
Какие задачи решает AIOps для IT-команд
AIOps решает три группы задач: обнаружение проблем, анализ причин и ускорение действий. Для IT-команд это означает меньше ручной сортировки сигналов, быстрее принятие решений и более предсказуемое управление инцидентами.
На практике AIOps помогает в управлении инцидентами, реагировании на инциденты, устранении проблем и нацелен на снижение MTTR за счёт автоматизации корреляции, RCA и маршрутизации.
Типовой сценарий такой. В инфраструктуре с несколькими источниками мониторинга растёт нагрузка на базу, потом увеличивается latency у приложения, потом сыпятся алерты у frontend-сервиса. Без AIOps инженер руками смотрит десятки уведомлений. С AIOps-системой события группируются, аномалия выделяется, вероятная причинно-следственная связь поднимается наверх.
Команда быстрее доходит до инцидент-решения.
Из опыта работы с командами контента и продукта я вижу похожую логику и вне эксплуатации: когда люди тратят время на сортировку шума, они не делают работу. AIOps ценен не магией AI, а уменьшением операционной нагрузки.
Как работает AIOps: данные, анализ и автоматизация
AIOps работает как конвейер обработки операционных данных. Сначала платформа собирает телеметрию из разных источников, затем нормализует её, связывает события, выявляет аномалии, ищет вероятные первопричины и только потом помогает с реагированием на инциденты или автоматическом устранении.
Это не один алгоритм и не одна магическая модель. Это слой аналитики над IT-данными.
«Типичный AIOps-пайплайн включает парсинг сырых данных, нормализацию через z-score или min-max scaling, извлечение признаков с помощью PCA и обнаружение аномалий с использованием Isolation Forest или autoencoders». — NIST SP 1800-28, "Data Integrity: Detecting and Responding to Ransomware and Other Destructive Events", 2023.
В обзорных материалах IEEE и Gartner также упоминаются эти методы: нормализация сырых данных через z-score и min-max scaling для унификации форматов, а для первичной обработки — Isolation Forest для обнаружения выбросов и autoencoders для снижения размерности (IEEE AIOps Survey, 2023; Gartner AIOps Framework, 2024).
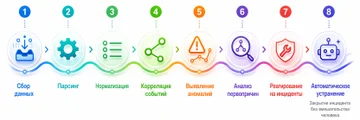
Какие источники данных использует AIOps
Современные AIOps-системы используют разные типы операционных данных, потому что по одному источнику трудно понять реальную картину. Базовый набор — логи, метрики, трассировки, события изменений и данные из систем мониторинга.
Обычно в обработке данных участвуют:
- серверные и системные метрики (CPU, память, диск, сеть);
- логи приложений, ОС, БД и middleware;
- APM-трассировки (Application Performance Monitoring);
- события изменений инфраструктуры и релизов (CI/CD, конфигурации);
- данные из CMDB, ITSM и систем управления конфигурациями;
- неструктурированные данные, включая текстовые сообщения об ошибках.
Именно сочетание данных и событий делает AIOps полезным. Если есть только потоки данных без контекста изменений, платформа видит шум. Если есть только логи без метрик и трассировок, RCA становится догадкой.
Как AIOps выявляет аномалии и корневые причины
AIOps выявляет аномалии за счёт построения модели нормального поведения и поиска отклонений. А корневые причины он ищет через причинно-следственные связи, корреляцию аномалий и анализ взаимосвязи между событиями во времени и по топологии.
«В AIOps-пайплайнах используется нормализация данных, выделение признаков и модели для обнаружения выбросов. Isolation Forest показывает точность 0.92 на датасетах ITIL для outlier detection, а autoencoders снижают размерность на 70%». — Gartner AIOps Framework, 2024.
Что это значит без лишней математики. Система смотрит на исторические данные, понимает условную норму по latency, error rate, загрузке CPU, очередям, количеству исключений. Потом замечает: комбинация сигналов изменилась не просто чуть-чуть, а нетипично для этой среды и этого времени. Дальше начинается корреляция.
Например, всплеск ошибок в API совпал с изменением конфигурации в кластере и аномалией на storage-узле. Для инженера это уже не три разрозненных алерта, а одна гипотеза о причине сбоя.
Вот это и есть ценность. Не «ИИ всё понял», а «система сократила путь от симптома к проверяемой гипотезе».
Где применяют AIOps: основные сценарии и случаи использования
AIOps применяют там, где IT-среда сложная, меняется быстро и генерирует слишком много телеметрии для ручного анализа. Это мониторинг IT-систем и бизнес-сервисов, проактивный мониторинг инфраструктуры, управление инцидентами, RCA, работа в центрах обработки данных, микросервисных архитектурах и средах высокой нагрузки.
AIOps для мониторинга инфраструктуры и сервисов
Здесь AIOps нужен для того, чтобы видеть состояние IT не по отдельным компонентам, а по цепочке влияния на сервис. Он помогает отслеживать деградацию сервисов, изменения времени ответа и нестабильность компонентов инфраструктуры до того, как это превратится в массовый отказ.
Особенно это важно в сложной IT-инфраструктуре, где один бизнес-сервис зависит от сети, базы, очередей, API-шлюза, контейнерного оркестратора и внешних интеграций. При традиционном мониторинге команда получает набор симптомов.
AIOps позволяет выявлять потенциальные проблемы по совокупности слабых сигналов.
Сценарий оправдан технически: система анализирует baseline нормального поведения и замечает отклонения раньше, чем они станут критическими. Но конкретные проценты точности и времени обнаружения без проверяемых источников приводить нельзя.
AIOps для инцидентов, RCA и сокращения MTTR
Для процессов управления инцидентами AIOps полезен прежде всего в сортировке и связывании событий. Он помогает сократить путь от обнаружения инцидента до гипотезы о первопричине и правильной эскалации.
В типовом enterprise-ландшафте ситуация выглядит так. Один инцидент рождает десятки алертов: приложение ругается на БД, БД — на storage, балансировщик — на timeouts, пользователи — на медленную работу. Команда эксплуатации тратит время на расклейку этого пазла.
AIOps объединяет события, поднимает вероятный первичный узел отказа и даёт основу для RCA.
«AIOps обеспечивает переход от реактивного firefighting к проактивному управлению через корреляцию данных и предиктивную аналитику, автоматизируя root cause analysis». — Forrester, "The Forrester Wave: AIOps Platforms", 2021.
Логика применения AIOps в инцидент-менеджменте подтверждена определениями ведущих аналитических агентств: переход от ручного реагирования к автоматизации анализа первопричин.
Преимущества AIOps для бизнеса и IT-эксплуатации
Преимущества AIOps — это не только автоматизация операций. Главное — повышение эффективности IT-эксплуатации, снижение шума, более быстрое реагирование на инциденты и лучшая стабильность сервисов в условиях сложной цифровой среды.
| Плюсы AIOps | Ограничения и минусы внедрения |
|---|---|
| Проактивное управление вместо чисто реактивного подхода | Высокие требования к качеству IT-данных |
| Снижение информационного шума через корреляцию событий | Нужны интеграции с существующими системами мониторинга |
| Поддержка RCA и ускорение реакции на инциденты | Требуется настройка моделей машинного обучения |
| Автоматизация рутинных операций | Возможны завышенные ожидания от "универсального инструмента" |
| Улучшение видимости сложной IT-инфраструктуры | Без контекста бизнес-сервисов эффект ограничен |
AIOps даёт наибольшую пользу не там, где «хотят внедрить AI», а там, где уже больно от объёма данных, количества изменений и ручной эксплуатации.
Что получает бизнес помимо автоматизации операций
Бизнес получает не только автоматизацию рутинных задач. Он получает более устойчивые цифровые сервисы, лучшее качество пользовательского опыта и более обоснованные решения о развитии инфраструктуры.
Если упростить, AIOps полезен бизнесу тогда, когда стабильность IT-сервисов критически важна для процессов цифровой трансформации. Сбой в платёжном сервисе, деградация личного кабинета, рост времени ответа в пиковую нагрузку — это уже не «техническая мелочь», а прямое влияние на пользователей, выручку и доверие к сервису.
Причинно-следственная цепочка понятна: стабильные IT-сервисы → меньше инцидентов → лучше пользовательский опыт → выше удержание клиентов → устойчивее бизнес-процессы.
Как внедрять AIOps: требования, этапы и частые сложности
Внедрение AIOps нужно начинать не с покупки платформы, а с аудита данных, источников мониторинга и процессов эксплуатации. Если телеметрия грязная, контекст отсутствует, а команды разработки и эксплуатации живут отдельно, внедрение AIOps не даст ожидаемого эффекта.
Что нужно подготовить до запуска AIOps-платформы
До запуска AIOps-платформы нужно подготовить три вещи: качественные источники мониторинга, контекст инфраструктуры и рабочие процессы, в которые платформа встроится. Без этого AIOps-платформа остаётся ещё одним экраном с графиками.
Базовый чек-лист такой:
| Что подготовить | Зачем это нужно |
|---|---|
| Источники мониторинга: логи, метрики, трассировки, события | Чтобы AIOps видел полную картину, а не обрывки сигналов |
| Контекст по компонентам инфраструктуры и сервисам | Чтобы корреляция учитывала реальные зависимости |
| Интеграции с ITSM и каналами оповещений | Чтобы анализ превращался в действие |
| Нормализованные и пригодные данные | Чтобы обучению моделей было на чём стоять |
| Общий рабочий процесс команд эксплуатации и разработки | Чтобы решения платформы не выпадали из реальной работы |
Какие ошибки мешают получить эффект от AIOps
Главная ошибка — считать AIOps универсальным инструментом, который сам решит проблемы зрелости. Не решит. Он зависит от качества телеметрии, контекста и процессов сильнее, чем многие ожидают.
Чаще всего эффект ломают такие вещи:
- В систему подают огромные объёмы данных без фильтрации и приоритизации.
- Нет связи между техническими сигналами и бизнес-сервисами.
- Команда сохраняет реактивный подход и не меняет рабочие процессы.
- AIOps внедряют поверх разрозненных систем мониторинга без единого интерфейса и общей модели инфраструктуры.
- От платформы ждут полной автоматизации там, где сначала нужна нормальная наблюдаемость (observability).
И это, честно говоря, нормальная история. Часто компания покупает продвинутую аналитику, а потом выясняется, что алерты кричат одинаково громко и на падение продакшена, и на незначительное отклонение dev-стенда. AIOps тут не виноват.
Как связаны AIOps, DevOps, MLOps и observability
Эти подходы не заменяют друг друга. Observability даёт телеметрию, DevOps меняет процессы разработки и эксплуатации, MLOps управляет жизненным циклом ML-моделей, а AIOps использует всё это для анализа и автоматизации IT-операций.
Тогда как observability отвечает за видимость состояния систем, AIOps фокусируется на том, чтобы из этих данных делать выводы и действия. Тогда как DevOps ускоряет доставку изменений и совместную ответственность, AIOps помогает справляться с последствиями сложности этой скорости.
А MLOps нужен там, где сама AIOps-система использует и развивает ML-модели как рабочий компонент.
Когда достаточно observability, а когда нужен AIOps
Observability достаточно, когда команде хватает телеметрии и ручного анализа для принятия решений. AIOps нужен, когда объём сигналов, скорость изменений и сложность IT-ландшафта начинают превышать человеческую пропускную способность.
Есть практические признаки:
- команда тонет в алертах;
- RCA занимает слишком много ручного времени;
- зависимости между сервисами трудно восстановить быстро;
- релизы и изменения происходят настолько часто, что статические правила не успевают адаптироваться;
- observability уже есть, а управляемости всё ещё нет.
Вот в этот момент AIOps дополняет существующие практики, а не заменяет их.
Как выбрать AIOps-платформу под свои задачи
Выбирать AIOps-платформы нужно не по слову AI в презентации, а по тому, как они работают с вашими данными, инцидентами и инфраструктурой. Критичны источники данных, глубина корреляции событий, возможности RCA, автоматизация операций, интеграции и работа в гибридных средах.
| Критерий выбора | Что проверять на практике |
|---|---|
| Источники данных | Логи, метрики, трассировки, события изменений, внешние системы |
| Корреляция событий | Умеет ли платформа объединять алерты в инциденты |
| RCA | Даёт ли объяснимую гипотезу по первопричине |
| Автоматизация операций | Есть ли сценарии auto-remediation и оркестрация |
| Интеграции | ServiceNow, Jira, Slack, CMDB, решения мониторинга |
| Архитектура | Поддержка cloud, on-premise, гибридных и мультиоблачных сред |
| Управление | Единый интерфейс, RBAC, аудит, контроль доступа |
Под таблицей критерии стоит читать так: если платформа слабо работает с вашими источниками мониторинга, вся продвинутая аналитика бессмысленна. Если нет автоматизации и интеграций, платформа останется советчиком, а не рабочим инструментом.
Какие функции критичны для enterprise-среды
Для enterprise-среды критичны функции, которые учитывают реальную сложность: поддержка гибридных и мультиоблачных сред, интеграция с легаси и современной IT-инфраструктурой, единый интерфейс, безопасность данных, контроль доступа и работа под высокой нагрузкой.
Я бы смотрел на такие вещи:
- работа с разнородными компонентами инфраструктуры;
- масштабирование под большие объёмы телеметрии;
- поддержка автоматического устранения типовых инцидентов;
- объяснимость рекомендаций;
- изоляция данных и ролевой доступ;
- устойчивость самой платформы как критически важного элемента IT-операций.
Потому что enterprise не покупает просто инструмент. Enterprise покупает управляемость.