

Частый вопрос разработчиков — LlamaIndex что это? Простыми словами, LlamaIndex это фреймворк и платформа для работы с данными, которая помогает создавать приложения на базе больших языковых моделей (LLM), способные использовать ваши частные данные. Фреймворк для LLM-разработчиков решает ключевую проблему языковых моделей — их ограниченную «память». Он подключает внешние источники знаний, такие как PDF-документы, базы данных или API, и делает их доступными для модели в момент ответа.
Главная проблема LLM, которую решает LlamaIndex
Ограниченный "контекст" и "устаревшие" знания LLM
Стандартные большие языковые модели, будь то ChatGPT или Gemini, имеют фундаментальное ограничение: их знания зафиксированы на дату последнего обучения. Они не знают о событиях, произошедших после этой даты, и не имеют доступа к внутренней документации компании, личным файлам или базам данных. Если модель обучалась на данных до 2024 года, она не сможет ответить на вопрос о результатах конференции, прошедшей в 2025 году.
Это ограничение мешает использовать стандартные LLM для решения задач, требующих актуальной или частной информации.
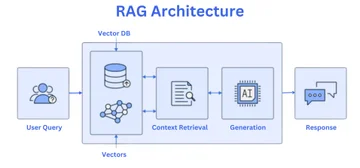
Ключевая концепция: Retrieval-Augmented Generation (RAG)
Для решения этой проблемы применяют подход Retrieval-Augmented Generation (RAG). Это процесс из двух шагов:
- Поиск (Retrieval). Прежде чем сгенерировать ответ, система ищет нужную информацию во внешних, подключенных источниках данных, например, в корпоративной базе знаний или PDF-отчете.
- Генерация с дополнением (Augmented Generation). Найденная информация вместе с исходным запросом пользователя передается языковой модели. LLM использует этот дополнительный контекст для создания точного и фактологически верного ответа.
Согласно официальной документации LlamaIndex Python Documentation (2025), RAG — это ключевая техника для построения LLM-приложений с опорой на данные. Она позволяет моделям отвечать на вопросы о частных данных, предоставляя их во время запроса, а не обучая модель на них заново. LlamaIndex является ведущим фреймворком для построения RAG-систем.
Как работает LlamaIndex: архитектура и основные этапы
Весь рабочий процесс в LlamaIndex можно разбить на пять последовательных этапов, которые превращают сырые данные в осмысленные ответы.
Этап 1 и 2: Загрузка (Loading) и Индексация (Indexing)
Коннекторы данных (Data Connectors) и LlamaHub
Начальный этап — загрузка данных. LlamaIndex через репозиторий LlamaHub предоставляет сотни готовых коннекторов для подключения к разным источникам. Это могут быть как неструктурированные данные (PDF, DOCX-файлы), так и структурированные (базы данных SQL), а также данные из сервисов вроде Notion, Slack или Google Sheets.
Индексация: превращение данных в "мозг" для LLM
После загрузки сырые данные непригодны для быстрого поиска. На этапе индексации LlamaIndex разбивает их на небольшие фрагменты (чанки), а затем каждый чанк преобразует в числовое представление — вектор (эмбеддинг). Этот процесс похож на создание детального конспекта для огромной библиотеки, где у каждой идеи есть свой уникальный числовой код. Векторы позволяют машине понимать семантическую близость фрагментов текста.
Этап 3 и 4: Хранение (Storing) и Запрос (Querying)
Индексы (Indexes) и Векторные базы данных
Созданные числовые векторы и их исходные текстовые фрагменты хранят в индексах, которые часто размещают в специализированных векторных базах данных. Популярные решения на 2025 год включают Pinecone, Weaviate и ChromaDB. Эти хранилища оптимизированы для сверхбыстрого поиска векторов по семантической близости, что является основой для этапа запроса.
Движки запросов (Query Engines) и Агенты (Data Agents)
Когда пользователь задает вопрос, в дело вступает движок запросов (Query Engine). Он преобразует вопрос пользователя в такой же вектор, находит в базе наиболее близкие по смыслу векторы данных (чанки) и передает их вместе с вопросом в LLM.
Агент (Data Agent) — более сложная сущность. Он не просто ищет информацию, но и может взаимодействовать с внешними инструментами: вызывать API, обращаться к базам данных, выполнять код. Если движок запросов — это библиотекарь, который находит нужную книгу, то агент — это ассистент, который может не только найти книгу, но и прочитать ее, сделать выводы и на ее основе заказать билет в театр.
Этап 5: Синтез ответа (Response Synthesis)
На финальном этапе языковая модель получает от движка запросов исходный вопрос и релевантные фрагменты данных, найденные в индексе. Используя этот контекст, LLM генерирует окончательный, полный и точный ответ для пользователя. Ответ основывается на фактах из подключенных данных, а не на собственной устаревшей «памяти» модели.
Что предлагает LlamaIndex: основные возможности и сферы применения
LlamaIndex предлагает готовое решение для быстрого создания интеллектуальных приложений, решающих ваши задачи с данными. Его модули позволяют:
- Создание продвинутых RAG-приложений. Построение чат-ботов и Q&A-систем, которые отвечают на основе документации, базы знаний или других кастомных данных.
- Разработка автономных агентов. Создание интеллектуальных агентов, которые могут взаимодействовать с API, базами данных и другими инструментами для решения сложных задач.
- Автоматизация обработки неструктурированных данных. Структурированное извлечение информации из PDF-отчетов, юридических контрактов и других сложных документов.
- Генерация аналитических отчетов и саммари. Автоматическое суммирование больших объемов текста и генерация отчетов на основе множества источников.
LlamaIndex vs LangChain: сравнение двух фреймворков
Выбор между LlamaIndex и LangChain — один из главных вопросов для начинающих LLM-разработчиков. Оба фреймворка мощные, но у них разная философия и сильные стороны. LlamaIndex исторически сфокусирован на данных и RAG, в то время как LangChain — на гибком создании цепочек (chains) и агентов.
| Параметр | LlamaIndex | LangChain |
|---|---|---|
| Основная специализация | Индексация, поиск и извлечение данных для RAG. | Сложные пайплайны, интеграции, агенты, диалоги. |
| Простота для RAG | Высокая — есть готовые и оптимизированные решения. | Средняя — требует больше ручной настройки. |
| Гибкость и кастомизация | Более сфокусирован на задачах с данными. | Высокая — модульность для построения любых цепочек. |
| Работа с данными и индексация | Продвинутая — главное преимущество фреймворка. | Базовая — реализуется через общие инструменты. |
| Экосистема и инструменты | Акцент на коннекторах и хранилищах данных. | Широкая экосистема плагинов и интеграций с API. |
Когда выбрать LlamaIndex, а когда — LangChain
Выбор зависит от основной цели:
- Выбирайте LlamaIndex, если: главная задача — RAG (чат с документами, Q&A по базе знаний) и вам нужно быстрое, оптимизированное решение именно для этого.
- Выбирайте LangChain, если: нужна гибкость, вы строите сложных агентов с множеством инструментов или нестандартные цепочки вызовов LLM.
- Использование вместе: да, они отлично дополняют друг друга. Часто LlamaIndex используют внутри LangChain как мощный инструмент для индексации и поиска данных, а LangChain отвечает за оркестрацию и логику агента.
Практика: создаем Q&A-бота на Python за 5 минут
Шаг 1: Установка и настройка окружения
Для начала установим необходимые библиотеки. Вам понадобится Python и менеджер пакетов pip.
pip install llama-index openaiТакже убедитесь, что у вас есть API-ключ от OpenAI, и сохраните его как переменную окружения.
Шаг 2: Подготовка данных и создание скрипта
Создайте в проекте папку data. Внутрь этой папки поместите любой PDF-документ, по которому вы хотите задавать вопросы, например, report.pdf. Рядом создайте Python-файл app.py.
Шаг 3: Пишем код для индексации и запроса
Теперь откройте файл app.py и добавьте следующий код. Он загрузит PDF-документ, создаст индекс в оперативной памяти и позволит задать вопрос.
Импортируем необходимые модули из LlamaIndex
from llama_index.core import VectorStoreIndex, SimpleDirectoryReaderimport osУбедитесь, что ваш OpenAI API ключ установлен как переменная окружения
# os.environ["OPENAI_API_KEY"] = "ваш_ключ"1. Загружаем документы из папки data
print("Загрузка документов...")documents = SimpleDirectoryReader("data").load_data()2. Создаем векторный индекс из загруженных документов
Этот процесс происходит в памяти и не требует настройки баз данныхprint("Создание индекса...")index = VectorStoreIndex.from_documents(documents)3. Создаем движок запросов на основе индекса
query_engine = index.as_query_engine()4. Задаем вопрос по содержимому вашего PDF-файла
question = "Какая основная тема документа?"print(f"Запрос: {question}")response = query_engine.query(question)5. Выводим ответ, сгенерированный LLM на основе найденных данных
print("Ответ:")print(response)Запустите скрипт, и через несколько секунд вы получите ответ на свой вопрос, основанный на содержании вашего PDF-файла.
Экосистема LlamaIndex: больше, чем просто RAG
LlamaParse: интеллектуальный парсинг сложных PDF
LlamaParse — это продвинутый сервис для извлечения информации из PDF-файлов со сложной версткой. В отличие от простых парсеров, он использует генеративный ИИ для понимания структуры документа, корректного извлечения таблиц, текста и диаграмм, сохраняя их логическую связь. Это незаменимый инструмент для работы с научными статьями, финансовыми отчетами и отсканированными документами.
LlamaExtract: структурированное извлечение данных (JSON)
LlamaExtract решает задачу извлечения неструктурированных данных в строго заданный формат JSON. Вы определяете нужную структуру с помощью Pydantic-схемы в Python, а LlamaExtract заставляет LLM вернуть информацию из текста точно в этом формате. Это позволяет легко превращать сырой текст, например, описание продукта или резюме, в готовые для использования в коде и базах данных объекты.
Частые ошибки новичков
Неправильный выбор типа индекса
Для задач вопросов и ответов (Q&A) почти всегда следует использовать VectorStoreIndex, так как он обеспечивает семантический поиск по смыслу. Новички иногда по ошибке используют ListIndex, который просто перебирает все документы по порядку. Это неэффективно для больших объемов данных и не позволяет находить информацию по смысловой близости.
Игнорирование размера чанков (chunk size) и пересечения (overlap)
Качество поиска напрямую зависит от того, как вы разбиваете исходные документы. Слишком большие чанки (фрагменты) могут "размывать" конкретную мысль, а слишком маленькие — терять важный контекст. Важно экспериментировать с параметрами chunk_size (размер чанка) и chunk_overlap (пересечение между соседними чанками), чтобы найти баланс для ваших данных.
Отсутствие предварительной обработки данных
Принцип "мусор на входе — мусор на выходе" здесь работает безотказно. Если загружать в LlamaIndex неотформатированные, "грязные" данные с артефактами верстки или дубликатами, качество ответов будет низким. Очистка и структурирование данных перед индексацией — критически важный шаг для получения точных результатов.
Часто задаваемые вопросы (FAQ)
Можно ли использовать LlamaIndex бесплатно?
Да, сам фреймворк LlamaIndex является проектом с открытым исходным кодом и распространяется бесплатно. Однако его работа требует использования больших языковых моделей (например, через API OpenAI) и, возможно, хостинга для векторных баз данных, что является платными услугами.
Поддерживает ли LlamaIndex русский язык?
Да. LlamaIndex не зависит от языка и работает с текстом. Качество поддержки русского языка определяется двумя компонентами: моделью для создания эмбеддингов (векторов) и самой LLM. Современные популярные модели от OpenAI или Google отлично понимают и обрабатывают запросы на русском языке.
Нужно ли мне мощное GPU для работы с LlamaIndex?
Нет, если вы используете LLM через API, например, от OpenAI, Anthropic или Google. В этом случае все вычисления происходят на серверах провайдера. Собственное мощное GPU потребуется только в том случае, если вы решите развернуть большую языковую модель локально на своем компьютере.
Какие LLM можно использовать с LlamaIndex?
LlamaIndex поддерживает интеграцию с большинством популярных LLM: модели от OpenAI (GPT-4, GPT-3.5), Anthropic (Claude), Google (Gemini). Он также легко интегрируется с open-source моделями, которые запускают локально через инструменты вроде Ollama или Hugging Face. Это дает разработчикам гибкость в выборе инструментов.
Комментарии (0)
Новый комментарий
Новый комментарий отправлен на модерацию