

Вы наверняка уже слышали про ChatGPT, GPT-4 или «нейросети, которые пишут тексты». Всё это — примеры LLM, или больших языковых моделей. Они умеют читать, понимать и генерировать тексты так, как раньше умели только люди. Но что именно скрывается за этим названием?
LLM расшифровывается как Large Language Model, то есть большая языковая модель. Это разновидность искусственного интеллекта, которая обучена работать с языком: писать письма, подбирать идеи, отвечать на вопросы, помогать с кодом. LLM — это не просто нейросеть, а система, которая «натренировалась» на терабайтах текстов, чтобы предсказывать, какое слово должно быть следующим.
Такие модели уже изменили подход к работе в IT, маркетинге, продажах и даже медицине. Они стали не просто модным инструментом, а рабочей частью бизнес-процессов. Компании интегрируют LLM в поддержку клиентов, автоматизируют обработку документов и улучшают поиск по базам знаний.

Если вы продаёте серверы, строите ИТ-инфраструктуру или консультируете заказчиков, вам стоит понимать, как работают LLM, зачем они нужны и какие задачи могут решать. Эта статья поможет в этом разобраться — без технического занудства, но с конкретикой и пользой.
LLM это: расшифровка, определение и место среди ИИ
LLM — это аббревиатура от Large Language Model, что переводится как большая языковая модель. Это разновидность искусственного интеллекта, которая обучена понимать и генерировать текст. Причём текст любого типа: от технической инструкции до шутки в стиле стендапа.
Важно понимать: LLM — это не «искусственный интеллект» в полном смысле этого слова, а его узкая, но мощная часть. Она не умеет видеть, слышать, чувствовать. Зато отлично справляется с тем, что связано с языком: письмами, чатами, статьями, кодом, переводами, резюме, таблицами.
Чем отличается LLM от обычной нейросети? Размером, задачами и подходом к обучению. Языковая модель работает не с числами или картинками, а с текстами. Она «читает» миллионы страниц и учится замечать закономерности — какие слова часто идут друг за другом, какие фразы связаны, какие смыслы передаются между строк.
Если раньше алгоритмы обрабатывали язык через жёсткие правила и словари, то LLM делает это гибко и «человечески». Она не запоминает всё подряд, а выстраивает вероятностную модель языка — что сказать дальше, чтобы это звучало логично.
Так что LLM — это не просто нейросеть, а особый вид ИИ, заточенный под работу с текстами и речью. И она уже изменила подход к разработке продуктов, особенно в тех сферах, где важна коммуникация.
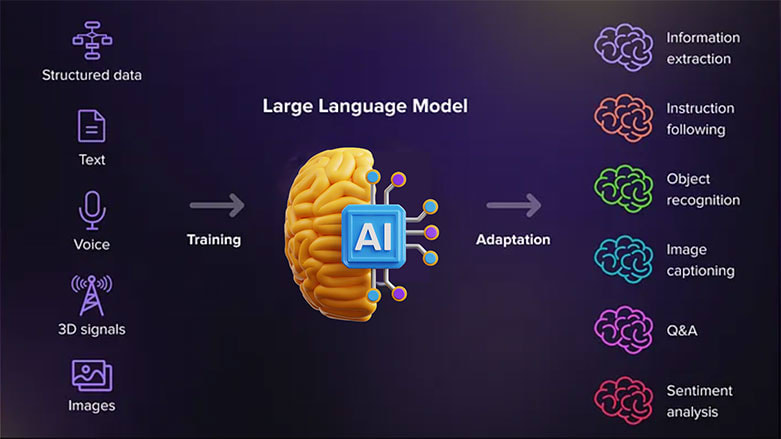
Как устроена LLM: принцип работы и обучение моделей
Большая языковая модель (LLM) — это не волшебная кнопка, а результат серьёзной инженерной работы. В основе — нейросеть, которая обучается на огромных массивах текста. Её цель — научиться предсказывать, какое слово логично поставить следующим, если знать контекст. Именно это делает её способной «разговаривать», «думать» и даже «анализировать».
Внутри LLM нет знаний как у человека. Она не запоминает учебники и не понимает текст в обычном смысле. Зато она умеет находить закономерности: если в текстах слово «контракт» часто идёт рядом со словами «подписан» и «документ», модель это запомнит — и сможет использовать в похожих ситуациях.
Вся работа строится на статистике. LLM считывает, какие слова и фразы встречаются вместе, в каком порядке, в каком контексте. На основе этого она создаёт внутреннюю модель языка. Чем больше примеров она «прочитала» во время обучения, тем точнее её прогноз.
Процесс можно представить как многослойную систему фильтров. Каждый слой нейросети обрабатывает текст, замечая всё более сложные связи — сначала между словами, потом между фразами, потом между смыслами. А на выходе модель выдаёт текст, который кажется осмысленным, логичным и даже «интеллектуальным».
Но чтобы LLM заработала, нужно пройти несколько этапов: собрать и очистить данные, выбрать архитектуру, обучить модель, а затем — адаптировать под конкретные задачи. Каждый из этих шагов — важный и непростой. Ниже разберём их по порядку.
Сбор и очистка данных для обучения
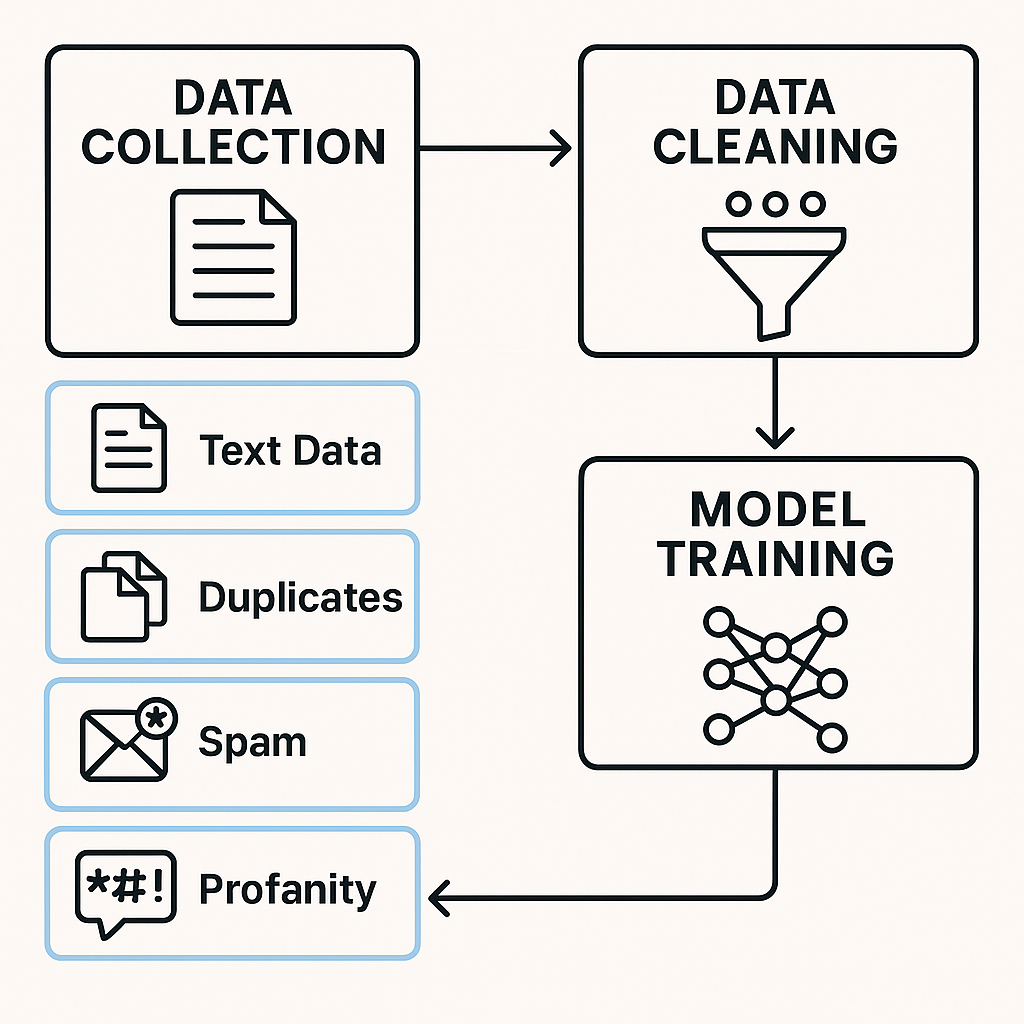
Чтобы LLM могла «говорить» с человеком на одном языке, её сначала нужно этому языку научить. И всё начинается с данных — текстов, на которых модель будет учиться. Это могут быть книги, статьи, диалоги, сайты, форумы, документация, код — всё, что когда-либо писал человек.
Однако собрать много текста — не значит сразу получить хороший результат. Без подготовки данные бесполезны. Например, в интернете полно дубликатов, спама, нецензурной лексики, искажённой информации. Если скормить это модели как есть, она начнёт повторять всё подряд — включая ошибки и грубости.
Поэтому данные сначала очищают. Это один из самых трудоёмких этапов. Из корпуса удаляют мусор, вырезают повторы, убирают нерелевантные или токсичные фразы. Некоторые разработчики используют фильтры на основе словарей, другие — создают отдельные модели, которые помогают оценить качество текста.
Важно и то, на каком языке собраны данные. Например, большинство LLM хорошо справляются с английским, потому что именно на нём собрана основная часть обучающего корпуса. А вот чтобы модель хорошо писала и понимала по-русски, ей нужно скормить качественный и разнообразный русскоязычный корпус.
И ещё один нюанс — юридический. Не весь текст в интернете можно использовать для обучения. Контент под лицензиями, личные данные, платные материалы — всё это требует либо разрешения, либо замены на открытые аналоги. Компании, которые игнорируют этот момент, рискуют столкнуться с судебными исками.
Итог: модель учится ровно на том, что вы ей дали. Плохие данные — плохая модель. Поэтому к сбору и очистке подходят с особым вниманием, особенно если речь идёт о задачах, где важны точность, безопасность и репутация.
Архитектура языковых моделей
Архитектура LLM — это то, как устроена модель внутри. Каким образом она «читает» текст, обрабатывает информацию и принимает решения, какое слово сказать следующим. Это фундамент, на котором строится вся её работа.
Сегодня почти все современные LLM основаны на архитектуре трансформеров (transformers). Этот подход был предложен в 2017 году в исследовании Google под названием "Attention Is All You Need". И с тех пор трансформеры стали стандартом де-факто в языковом ИИ.
Главная идея трансформера — внимание к контексту. Модель анализирует не только соседние слова, но и весь фрагмент текста сразу. Это значит, что при генерации ответа она может учесть, что говорилось в начале абзаца, в середине, и даже в другом абзаце. Она не идёт от слова к слову, как раньше, а работает с текстом целиком — как будто держит в голове весь разговор.
Архитектура трансформера состоит из слоёв. Каждый слой — это набор операций, которые находят связи между словами. Чем больше слоёв — тем глубже модель может понимать структуру языка. У самых мощных моделей вроде GPT-4 — сотни миллиардов параметров и десятки слоёв.
Есть и более лёгкие архитектуры, которые используют те же принципы, но работают быстрее или требуют меньше памяти. Например, Mistral или LLaMA от Meta — они предназначены для задач, где важна производительность на локальных серверах.
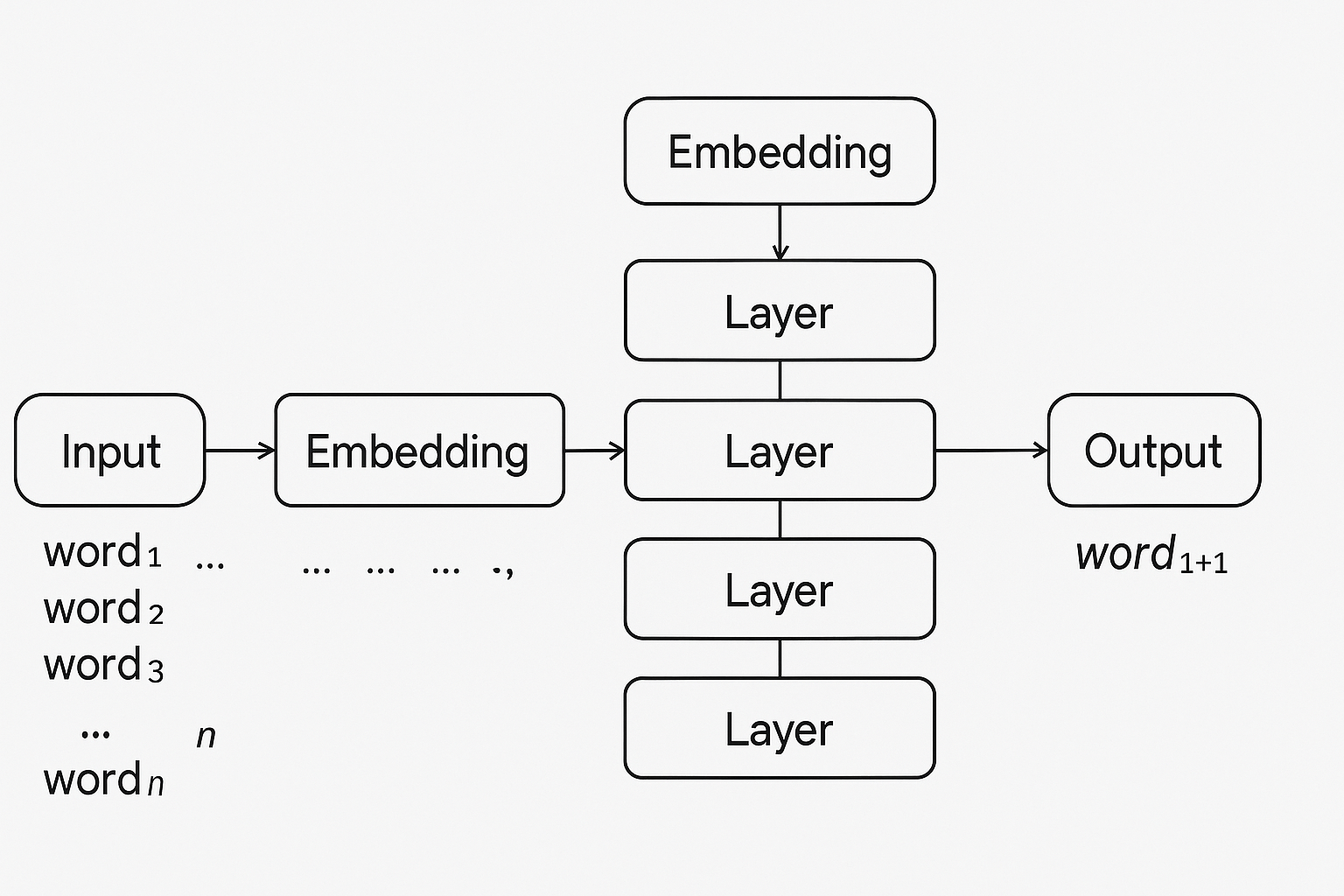
Разные модели могут иметь разную специализацию: одни лучше пишут художественный текст, другие — технический. Всё зависит от того, как устроена архитектура, какие функции в неё заложены, и как она взаимодействует с контекстом.
В двух словах: архитектура — это интеллект модели на уровне инженерии. Чем он гибче и точнее, тем выше шанс, что модель будет отвечать по делу, а не «в сторону».
Обучение моделей: с учителем и без
После того как архитектура модели выбрана, а данные подготовлены, начинается самое затратное по времени и ресурсам — обучение. Это процесс, в котором модель «читает» текст за текстом и учится предсказывать следующее слово, опираясь на предыдущие. Механика — простая, но в масштабах LLM это колоссальная вычислительная работа.
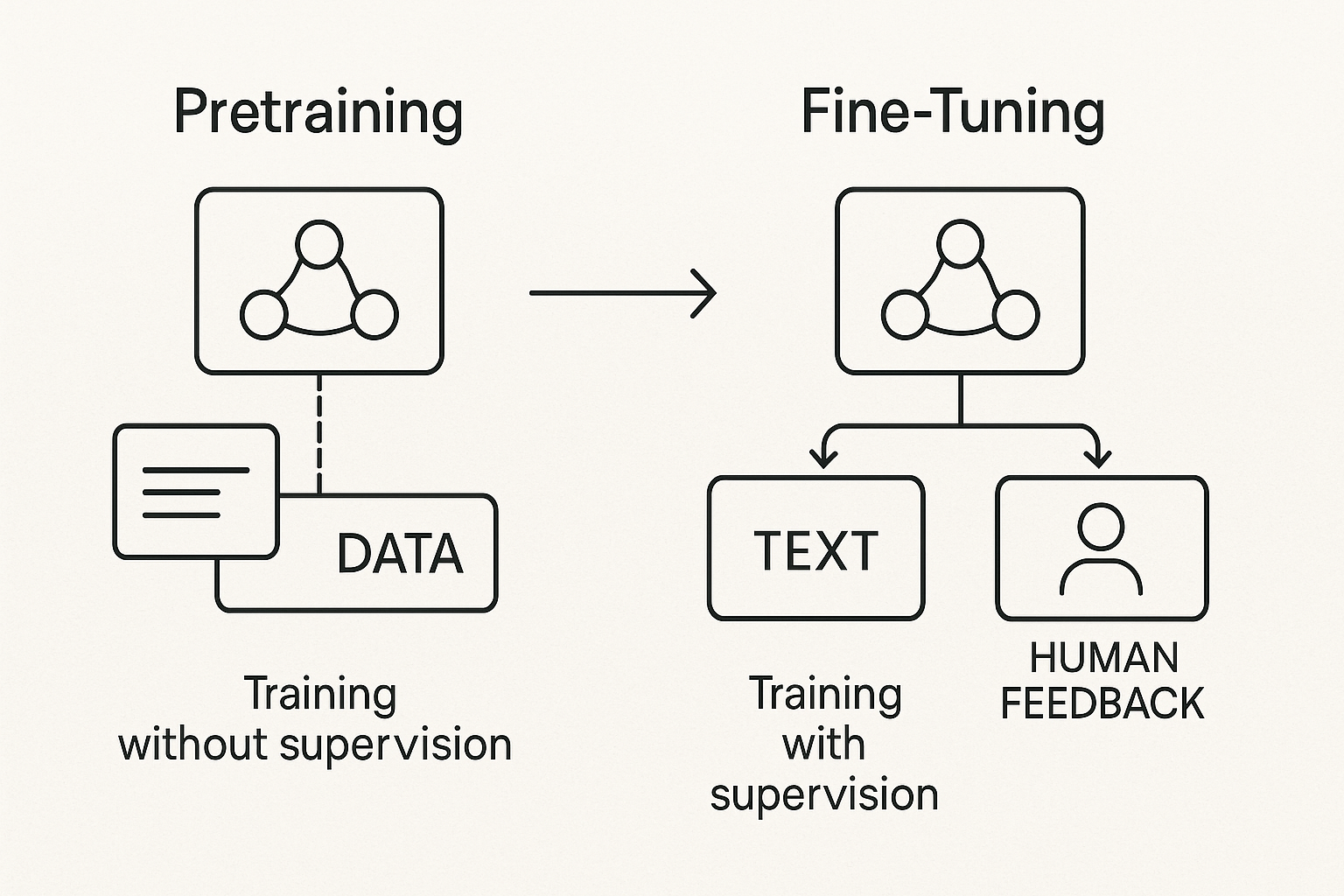
Обучение проходит в два этапа: предварительное обучение (pretraining) и дообучение с учителем (fine-tuning или supervised learning).
В первом этапе модель обрабатывает огромные объёмы текста — от википедий до форумов. Ей не говорят, что правильно, а что нет. Она просто получает текст, в котором случайно убраны отдельные слова или фразы, и должна угадать, что было на их месте. Это называется обучение без учителя — потому что модель обучается самостоятельно, без прямых подсказок.
На этом этапе формируется база: модель начинает понимать синтаксис, стиль, общие закономерности языка. Она знает, что «солнце светит», а «чай пьют», но пока не понимает, что такое «логично» или «уместно».
Дальше — обучение с учителем. Здесь человек вмешивается и помогает модели улучшать ответы. Например, если LLM выдала три версии ответа, специалисты выбирают лучший. Модель анализирует выбор и корректирует своё поведение. Этот этап называется reinforcement learning with human feedback (RLHF).
Такой подход позволяет не только повысить точность, но и обучить модель «этичному» поведению — избегать оскорблений, не выдавать вредных советов, быть вежливой. Именно на этом этапе модель становится «пригодной для пользователей».
Важно: даже после обучения LLM не становится умной в привычном смысле. Она не знает, что делает. Она просто стала лучше угадывать, что люди считают правильным и уместным. Вся её сила — в огромной базе знаний и тонкой настройке на вероятности.
Дообучение и настройка под задачи
Даже после основного обучения LLM остаётся универсальной — она знает многое, но не всё. Например, она может неплохо разбираться в языке, но ничего не знать про ваш бизнес, специфику отрасли или внутренние регламенты. Чтобы модель действительно начала помогать, её дообучают под конкретные задачи.
Этот процесс называется fine-tuning, и по сути он похож на адаптацию сотрудника на рабочем месте. Модель уже умеет «читать и писать», но теперь ей дают инструкции, примеры, термины, шаблоны. Её учат говорить именно так, как нужно в вашей компании — кратко, вежливо, по делу. Или наоборот — творчески, креативно, если речь идёт о маркетинге.
Часто для дообучения используют внутренние данные компании: переписки с клиентами, справки, инструкции, статьи, техподдержку. Всё это подаётся в виде пар «вопрос — правильный ответ», чтобы модель могла увидеть, как именно вы решаете типовые задачи.
Также применяют инструкционное обучение (instruction tuning). Здесь модели дают команды вроде «напиши письмо клиенту, который недоволен задержкой доставки» и показывают примеры хороших ответов. Модель учится понимать, что от неё хотят — и выдавать результат в нужной форме.
Кроме того, для бизнес-применения используют инференс-настройку — когда модель не дообучается, а получает «контекст» прямо в момент работы. Например, вы передаёте ей правила компании или формат отчёта в самом запросе. Это удобно, когда нет времени или ресурсов на полноценное дообучение.
Главное: настроенная LLM — это уже не просто «модель из интернета». Это ваш цифровой помощник, говорящий на вашем языке, с учётом ваших данных. И именно здесь LLM раскрывает себя как часть команды, а не просто как демонстрация технологий.
Что умеют LLM: примеры применения в бизнесе и жизни
LLM — это универсальный инструмент, который уже помогает компаниям сокращать издержки, ускорять рутинные процессы и повышать качество обслуживания клиентов. Главное — они хорошо работают с текстами: читают, понимают, пишут, обобщают и даже переводят.
В отделах поддержки LLM берут на себя общение с клиентами — формируют ответы на часто задаваемые вопросы, помогают операторам быстрее находить нужную информацию и корректно формулировать решения. В юридических департаментах они читают длинные договоры, находят ошибки, делают сводки. А в маркетинге превращают идеи в тексты — для писем, постов, лендингов.
В IT-отделах языковые модели помогают программистам: подсказывают синтаксис, генерируют фрагменты кода, описывают работу функций. А внутри команды такие модели могут заменить внутренние базы знаний — отвечая на вопросы сотрудников и помогая в обучении новичков.
То, что раньше требовало часов работы специалистов, теперь можно автоматизировать с помощью одной модели. И речь не про будущее, а про сегодняшние кейсы — компании по всему миру уже внедряют LLM в самые разные процессы, от документооборота до клиентского сервиса.
Где применяются LLM в реальности
Большие языковые модели сегодня находят применение во множестве отраслей — не только в IT и технологиях, но и там, где раньше про нейросети даже не задумывались. Главное, что объединяет эти сферы — наличие больших объёмов текста, общения, документов и повторяющихся операций, связанных с языком.
В медицине LLM помогают врачам обрабатывать электронные карты пациентов, подбирать формулировки диагнозов, составлять выписки и расшифровки обследований. Для пациентов — это возможность получить предварительную консультацию или ответ на типовой вопрос без очереди.
В юридической практике модели читают договоры, ищут спорные фразы, составляют шаблонные документы, сравнивают версии и подсказывают формулировки. Это экономит часы работы юристов и снижает риски ошибок.
В маркетинге LLM используются для генерации текстов: заголовков, описаний, рекламных слоганов, писем. Модели адаптируют один и тот же месседж под разные каналы: сайт, email, соцсети, мессенджеры. Кроме того, они помогают в генерации идей и креативных концепций.
В финансах модели читают отчёты, выделяют ключевые показатели, анализируют клиентские обращения, генерируют аналитические обзоры и резюме на основе цифр. Также они используются для составления справок, внутренних документов и обработки заявок.
В IT и разработке LLM стали частью повседневной работы. Они помогают писать код, находить ошибки, комментировать функции, переводить техническую документацию, ускорять онбординг новых сотрудников. Также их используют в внутренних чатах и базах знаний.

Каждая из этих отраслей сталкивается с задачами, где важна скорость, точность и повторяемость. Именно тут LLM и становятся незаменимым помощником, который не устаёт и не ошибается из-за «человеческого фактора».
Задачи, которые решают языковые модели
Чтобы понять реальную пользу LLM, важно не просто знать, где они применяются, а какие конкретные задачи они могут решать. Потому что LLM — это не волшебный «ИИ», а инструмент, у которого есть чёткая зона ответственности: работа с языком. А внутри неё — десятки прикладных задач, которые раньше решали вручную.
Одна из главных — генерация текста. Это может быть письмо, пост, заголовок, сценарий звонка, описание товара, новость или даже технический отчёт. Модель создаёт текст по заданию, в нужном стиле, с учётом темы и целевой аудитории. И делает это быстро, без выгорания и перерывов на обед.
Другая важная задача — обобщение информации. Модель умеет читать длинный текст и пересказывать его коротко, по сути. Например, вы загружаете 10 страниц отчёта — а на выходе получаете три абзаца с главными выводами. Это особенно полезно в аналитике, юриспруденции, управлении проектами.
Ещё одно направление — перевод и адаптация. LLM легко переводит тексты с английского на русский и наоборот, при этом сохраняет стиль, тон и смысл. Она может адаптировать один и тот же текст под разные каналы: для email, для лендинга, для мессенджера.
В коммуникациях модель решает задачу автоматического ответа. На письма, в чатах, на внутренние запросы. Она понимает суть обращения, классифицирует его, подбирает подходящий ответ. Это снижает нагрузку на службы поддержки, ускоряет реакцию и улучшает клиентский опыт.
Внутри компаний LLM решает задачи поиска и структурирования информации. Когда сотрудники ищут, как оформить заявку, где найти нужный регламент или как работает тот или иной процесс, модель может ответить быстрее и точнее, чем человек. Особенно если её обучили на внутренних документах.
Ещё одна сильная сторона — анализ данных на естественном языке. Например, вы можете загрузить 500 отзывов клиентов, и модель сама найдёт повторяющиеся темы, негатив, похвалы, жалобы. Раньше для этого нужен был аналитик и неделя времени. Сейчас — одна команда в интерфейсе.
И всё это — без программирования. LLM отвечает на обычные вопросы, как если бы вы писали их коллеге: «Сделай резюме по этой статье», «Напиши шаблон договора», «Сравни два отчёта». Чем точнее вы формулируете задачу — тем лучше модель выдаёт результат.
Популярные LLM: модели, продукты и решения
Сегодня на рынке представлены десятки языковых моделей, но лишь несколько из них действительно задают направление. Среди них — как коммерческие гиганты, так и опенсорсные альтернативы, которые активно внедряются в корпоративные решения.
Лидером остаётся OpenAI с линейкой GPT. Модель GPT-4, лежащая в основе ChatGPT, сегодня считается эталоном по качеству генерации текста. Она обучена на огромных массивах данных, поддерживает множество языков и умеет не только писать тексты, но и объяснять, анализировать, упрощать сложные идеи.
Второй сильный игрок — Google с моделью Gemini (бывшая Bard). Её особенность — тесная интеграция с поиском и корпоративными сервисами Google, что делает её удобной для анализа информации в реальном времени.
Anthropic развивает Claude — модель с акцентом на безопасность и этику. Её выбирают компании, которым важна предсказуемость поведения модели в критически важных задачах.
Кроме коммерческих решений, стремительно развиваются и опенсорсные LLM. Модели LLaMA от Meta, Mistral, BLOOM, YaLM от Сбера позволяют компаниям строить решения «на месте», без отправки данных в облако. Это особенно важно для бизнеса, где данные — коммерческая тайна.
Каждая модель имеет свои плюсы: кто-то быстрее работает на небольших серверах, кто-то лучше справляется с русским языком, а кто-то — с креативными задачами. Поэтому важно не просто выбрать известное имя, а понимать, какую задачу вы хотите решить и какие ресурсы у вас есть.
Коммерческие LLM-модели
Самые известные и продвинутые языковые модели сегодня — коммерческие. Это продукты крупных компаний, которые вложили миллиарды в разработку, инфраструктуру и масштабирование. Они стали стандартом качества и ориентиром для других — не только из-за маркетинга, но и благодаря реальным возможностям.

OpenAI — лидер сегмента. Её модель GPT-4 используется в ChatGPT, Copilot от Microsoft, многих CRM и поддержке клиентов. Она умеет писать тексты, объяснять сложные вещи, генерировать код, обобщать данные, вести диалог — и делает это стабильно. У неё большая база знаний, хорошая языковая адаптация, включая русский, и высокий уровень «понимания» контекста.
Google развивает серию моделей Gemini (бывший Bard). Их преимущество — тесная интеграция с поиском, Gmail, Google Docs, аналитикой. Gemini можно использовать прямо в офисных инструментах Google, и это удобно для тех, кто уже в экосистеме.
Anthropic предлагает модель Claude, которая сделана с упором на безопасность, прозрачность и предсказуемость. Её выбирают компании, которым важно соблюдение этики, соблюдение инструкций и стабильное поведение в сложных ситуациях.
Microsoft развивает модели через Azure OpenAI и интеграции в продукты 365. Это делает LLM доступными прямо из Excel, Word, Power BI. Такая модель особенно удобна для бизнеса, который работает в экосистеме Microsoft и хочет не просто «чат», а умного помощника внутри привычных программ.
Коммерческие LLM хороши тем, что они стабильны, поддерживаются, постоянно улучшаются. У них есть API, документация, SLA и техподдержка. Это особенно важно, если модель используется в продукте, где сбои недопустимы.
Но есть и минусы. Главный — данные уходят в облако. Вы не контролируете, где и как они обрабатываются. Есть риски утечки, а лицензии не всегда позволяют дообучать модель под свои задачи. Кроме того, стоимость может быстро расти при масштабировании.
Коммерческая LLM — как арендованный суперкар: быстро, удобно, эффектно. Но не ваша. Для многих бизнесов это — оптимальное решение. Но если вы хотите большего контроля, стоит рассмотреть альтернативы.
Опенсорсные большие языковые модели
Опенсорсные LLM — это модели с открытым исходным кодом, которые можно скачать, настроить под себя и запускать на своих серверах. Для бизнеса это значит одно: вы получаете полный контроль над моделью, данными и процессами. Без зависимости от облака, без риска утечки, без лицензий на каждое действие.
Одна из самых известных серий — LLaMA от Meta. С выходом LLaMA 2 компания сделала мощную модель доступной для некоммерческого и коммерческого использования. Она показывает отличные результаты, особенно в задачах генерации текста и диалога. Модель активно дорабатывают энтузиасты и компании, выпуская дообученные версии под разные языки, стили и задачи.
Mistral — новая, но стремительно набирающая популярность модель. Её особенность — высокая эффективность при небольшом размере. Она способна выполнять сложные задачи, при этом работает быстрее и требует меньше ресурсов. Отличный выбор для локального развёртывания в компаниях, где нет доступа к дорогим GPU.
BLOOM — модель от международного сообщества Hugging Face. Она поддерживает множество языков, включая русский, и специально создавалась как альтернатива закрытым системам. BLOOM ориентирована на научное сообщество, но активно используется и в прикладных проектах.
В России развивается модель YaLM от Сбера. Она обучена на русскоязычных текстах, неплохо справляется с диалогами и подходит для задач, где важна работа с русским языком. Также существуют модели от AI21, Cohere, EleutherAI и других открытых инициатив.
Главное преимущество open-source LLM — гибкость и независимость. Вы можете дообучить модель на своих данных, ограничить её поведение, встроить в локальную систему, обернуть в API — и всё это без обращения к внешним сервисам.
Но есть и сложности. Такие модели требуют инфраструктуры, компетенций и времени. Их нельзя просто «включить» — придётся собирать пайплайн: обучение, тестирование, развертывание, обновление. Без команды инженеров и MLOps-специалистов здесь не обойтись.

Опенсорсная LLM — как собственный станок. Зато свой. И если вы умеете с ним работать, то получите решение, идеально заточенное под вашу компанию — без лишнего, без навязанных ограничений, с полной безопасностью.
Как выбрать LLM для бизнеса
Поставить LLM в работу — это не просто «подключить чат-бота». Чтобы модель реально приносила пользу, нужно выбрать ту, что подходит именно под вашу задачу и возможности. Иначе вы рискуете потратить деньги, ресурсы и время впустую.
Начать стоит с цели. Зачем вам языковая модель? Хотите, чтобы она общалась с клиентами? Автоматизировала документы? Помогала маркетингу? Для каждого сценария подойдут разные модели. Где-то важна скорость, где-то — точность, а где-то — стоимость внедрения и поддержки.
Второй шаг — это ресурсы. Большие модели требуют больших серверов. Если у вас нет мощного железа, лучше выбрать более лёгкую модель или воспользоваться облачным сервисом. Например, коммерческие LLM вроде GPT-4 требуют подключения к внешним API, а опенсорсные модели можно разворачивать на своих серверах — но только если у вас есть соответствующая инфраструктура.
Критерии выбора модели
Выбор LLM — это не просто вопрос «какая лучше». Всё зависит от того, что именно вы хотите от модели, в какой инфраструктуре она будет работать и насколько критичны для вас данные и контроль над ними. Ниже — ключевые критерии, которые нужно учитывать перед внедрением.
Размер модели
Размер влияет на многое: точность, глубину понимания, скорость работы и требования к «железу». GPT-4 — огромная модель с выдающимся качеством, но она работает только через облако. LLaMA 2, Mistral и другие опенсорсные модели бывают в версиях 7B, 13B, 70B параметров. Чем больше модель — тем умнее, но и тем тяжелее её развернуть локально.
Если у вас нет мощной инфраструктуры, лучше выбрать компактную модель или использовать облачные решения. Большую модель без нужных ресурсов не получится использовать эффективно: она будет медленной, дорогой и нестабильной.
Качество генерации
Уровень ответов зависит от того, как модель обучалась, на каких данных, и насколько хорошо она понимает задачи бизнеса. GPT-4 и Claude справляются лучше всех, но у них закрытый исходный код. Опенсорсные модели — более гибкие, но их надо настраивать и дообучать. Чтобы проверить качество, лучше сразу тестировать: на своих задачах, реальных текстах, промптах от команды.
Лицензия
У каждой модели есть своя лицензия: коммерческая, условно-бесплатная, исследовательская. Некоторые опенсорсные модели (например, LLaMA 2) требуют, чтобы вы прошли регистрацию и соблюдали условия использования. Другие — полностью свободные. Перед внедрением обязательно проверьте: можно ли использовать модель в коммерческих целях, можно ли дообучать, нужно ли платить.
Открытость
Открытый исходный код — это контроль, прозрачность и возможность адаптации. Опенсорсные LLM можно настроить под свой домен, дообучить, встроить в любые внутренние системы. Закрытые — работают только как есть, и любые изменения — только через API. Но взамен вы получаете стабильность, поддержку, готовые интеграции.
Стоимость
Самый важный и часто недооценённый параметр. Облачные модели стоят за токены, и при масштабировании сумма может быть неожиданной. Например, если вы обрабатываете тысячи обращений в день — даже дешёвый тариф превращается в ощутимую статью расходов. Локальная модель требует вложений в инфраструктуру и поддержку. Важно сразу посчитать TCO — полную стоимость владения.
Вычислительные ресурсы для LLM
Большая языковая модель — это не просто алгоритм. Это сложная система, которая требует мощного железа для обучения, дообучения и даже просто для запуска. И если вы планируете использовать LLM не через облако, а у себя, вопрос инфраструктуры выходит на первый план.
Что именно нужно модели?
Во-первых, видеокарта (GPU). Обычный сервер или ноутбук с CPU не справится. Даже средняя по размеру модель (например, 7B параметров) требует десятки гигабайт видеопамяти. Без GPU она будет работать медленно или не запустится вовсе. Для малых моделей подойдут карты уровня A100, H100, L40 или RTX 6000. Чем мощнее — тем быстрее обрабатываются запросы.
Во-вторых, оперативная память (RAM). LLM активно использует память при генерации. Для запуска модели в inference-режиме (то есть просто для выдачи ответа) нужно минимум 64–128 ГБ RAM. А если вы планируете дообучать модель, объём должен быть ещё больше.
Третье — система хранения (диски). Модели весят десятки гигабайт, а данные для дообучения могут занимать терабайты. Нужны быстрые SSD, желательно NVMe, особенно если обучение происходит локально.
Четвёртое — процессор (CPU). Хотя основная нагрузка ложится на GPU, при развёртывании модели важен и CPU — он обрабатывает все запросы, управляет задачами, связывает модель с веб-интерфейсом или API. Хороший серверный процессор (например, AMD EPYC или Intel Xeon последнего поколения) сильно ускоряет работу всей системы.
Нужно ли обязательно покупать сервер?
Не обязательно. Если задачи не критичны по времени, можно использовать аренду серверов с GPU — в российских или зарубежных дата-центрах. Есть готовые облачные решения (например, VK Cloud, Yandex Cloud, Selectel, AWS, Azure), где модель разворачивается за пару часов, а платить нужно только за использование.
Если у вас чувствительные данные, и модель должна работать внутри — разумнее купить или собрать сервер с поддержкой нужных карт. Это потребует инвестиций, но обеспечит полный контроль и предсказуемую нагрузку на бюджет.
Резюме
Нельзя просто скачать LLM и запустить её «на обычном компьютере». Это требует подготовки, расчётов и понимания технических ограничений. Хорошая новость — сегодня всё чаще появляются оптимизированные модели, которые работают быстрее и требуют меньше ресурсов. Но даже для них нужен чёткий план: где разворачиваем, на чём, с каким SLA и кто поддерживает.
Как работать с LLM: промпты и инструменты
LLM не читают мысли. Чтобы они работали эффективно, им нужно правильно ставить задачи. Это называется prompt engineering — искусство писать запросы к модели так, чтобы она выдавала нужный и полезный результат.
Именно запрос определяет, что и как скажет языковая модель. Один и тот же LLM может ответить по-разному — в зависимости от того, как вы сформулируете вопрос. Поэтому важно понимать не только техническую сторону, но и логику общения с моделью.
Что такое промпт и как его писать
Промпт — это инструкция для модели. Это текст, который вы ей пишете, чтобы получить нужный результат. От простого «напиши письмо клиенту» до сложных: «представь, что ты финансовый аналитик, оцени показатели и составь краткий отчёт на 200 слов для руководства, без воды и терминов».
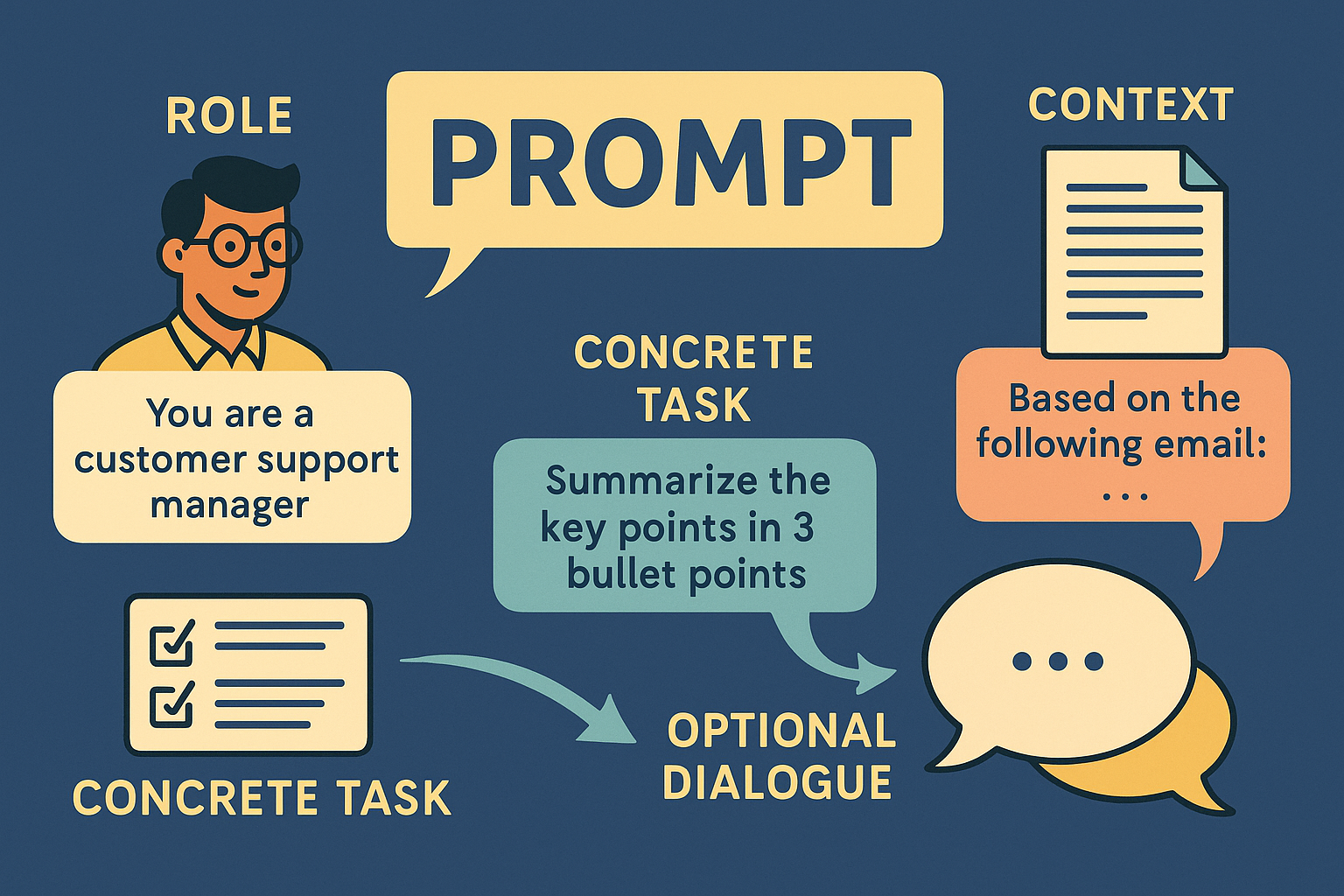
По сути, промпт — это ваша мысль, переведённая в конкретную задачу. Чем она чётче, тем выше шанс, что модель выдаст не абстрактный текст, а действительно полезный.
Есть несколько принципов, которые делают промпт эффективным:
Роль модели
Объясните, в каком качестве она сейчас работает. Например:
-
«Ты — менеджер техподдержки»
-
«Ты — редактор деловых писем»
-
«Ты — врач-флеболог, пишешь памятку для пациента»
Это задаёт тон, стиль и контекст.
Конкретная задача
Что именно нужно сделать: ответить, объяснить, написать, сжать, перевести, подытожить, найти ошибки.
Плохо:
«Расскажи о нейросетях»
Хорошо:
«Сделай краткое сравнение GPT-4 и Claude для HR-отдела, в таблице, с акцентом на стоимость и поддержку русского языка»
Ограничения
Укажите, как именно должен выглядеть результат: объём, формат, стиль, целевая аудитория.
Например:
-
«Не больше 200 слов»
- «Результат — список из 5 пунктов, без нумерации»
-
«Для лендинга на B2B-аудиторию»
Контекст
Если нужно, добавьте данные, на которых должна основываться модель: фрагмент письма, выдержка из документа, условия задачи. Чем больше у модели информации — тем меньше она «фантазирует».
Интерактив
Хороший промпт может быть диалогом: если результат не устроил, можно уточнить запрос, сократить, переформулировать. Работа с LLM — это живой процесс, а не кнопка «выполнить».
Модель — это как умный помощник, который выполняет ваши поручения. Если вы говорите нечётко, он может вас не понять. Но если задачу поставить грамотно, он не только справится, но и сделает это быстрее и лучше, чем большинство людей.
Примеры готовых промптов для задач
Один из самых частых вопросов, который возникает после внедрения LLM: "А что ей писать?". Команда открывает интерфейс, видит поле ввода — и замирает. Потому что без продуманного запроса модель или выдаёт бессмысленный текст, или просто перефразирует очевидное.
Чтобы этого избежать, компании создают библиотеку промптов — заранее подготовленных шаблонов запросов под типовые задачи. Ниже — практические примеры, которые можно адаптировать под свой бизнес.
Поддержка клиентов
Промпт:
«Ты — оператор клиентской поддержки. Клиент жалуется на задержку доставки. Напиши вежливый и честный ответ, признай проблему и предложи компенсацию. Без шаблонов и извинений “по копипасте”.»
Что делает модель:
Формирует человеческий, уважительный ответ, без канцелярита. Можно сразу вставлять в CRM или использовать как основу.
Маркетинг и контент
Промпт:
«Ты — контент-маркетолог. Напиши три варианта заголовка для рассылки, в которой мы предлагаем скидку 20% на серверы Lenovo. Тон — дружелюбный, но без шуток. Максимум 50 символов.»
Что делает модель:
Предлагает готовые заголовки с учётом длины, УТП и тона. Не просто синонимы, а разные подходы: срочность, выгода, редкость.
HR и рекрутинг
Промпт:
«Ты — HR в IT-компании. Составь вакансию для фронтенд-разработчика на React с опытом от 3 лет. Включи требования, условия и формат удалённой работы. Стиль — деловой, без “дружной команды” и “карьерного роста”.»
Что делает модель:
Генерирует текст, готовый для публикации, без воды и банальных фраз. Можно доработать детали и сразу размещать.
Юридический отдел
Промпт:
«Прочитай договор ниже и выдели абзацы, в которых может быть риск для клиента. Укажи, почему это может быть проблемой, но не переписывай договор целиком.»
Что делает модель:
Проводит первичный аудит текста, как ассистент юриста. Быстро находит спорные места: штрафы, сроки, неравные условия.
Аналитика и отчёты
Промпт:
«Вот 50 отзывов клиентов. Обобщи, что чаще всего их беспокоит, и какие сильные стороны они отмечают. Сгруппируй по смыслу и сделай сводку для руководства. Не пиши всё подряд, выдели главное.»
Что делает модель:
Превращает “сырой” текст в структурированное понимание обратной связи. Это ускоряет принятие решений и помогает улучшить продукт.
Эти шаблоны можно встроить в интерфейс: кнопка «написать письмо», «проверить договор», «создать вакансию». Сотруднику не нужно изобретать запрос каждый раз — он просто выбирает нужный сценарий и подставляет данные.
Так LLM становится не сложным ИИ, а простым и понятным инструментом в повседневной работе.
Ограничения LLM: риски, ошибки и этика
Большие языковые модели впечатляют своими возможностями, но не стоит воспринимать их как безошибочных помощников. У LLM есть ограничения, о которых важно знать заранее — особенно если вы планируете использовать их в бизнесе или передавать им чувствительные задачи.
Первое и главное — LLM не понимают текст так, как человек. Они не осознают смысла, не делают выводов, не разбираются в контексте «по-настоящему». Модель лишь предсказывает, какое слово или фраза с наибольшей вероятностью должна быть следующей. Поэтому она может звучать уверенно — но при этом ошибаться.
Модель может выдумывать факты, искажать информацию или отвечать двусмысленно. Это особенно опасно в медицине, праве, финансах и других областях, где ошибки стоят дорого.
Есть и этические риски. LLM может непреднамеренно воспроизвести предвзятости из обучающих данных: сексизм, расизм, стереотипы. Поэтому важно контролировать то, что она говорит, и регулярно проверять её поведение в реальных сценариях.
Наконец, модели не обучаются в моменте. Если вы ей что-то сказали, она это не запомнит в следующий раз. У неё нет памяти как у человека — если только вы сами не настроите такую функцию.
Поэтому внедрение LLM — это не просто установка софта, а постоянная работа с качеством, безопасностью и здравым смыслом. Нужно понимать, что модель — это инструмент, а не сотрудник. И именно от вас зависит, будет ли она помогать или вредить.

Безопасность и защита данных при использовании LLM
Когда компания начинает использовать LLM, особенно в облаке, встает логичный и важный вопрос: насколько это безопасно? Можно ли доверить модели конфиденциальную информацию, клиентские данные, внутренние документы?
Короткий ответ — осторожность необходима.
Большинство коммерческих LLM работают через облачные API, то есть данные, которые вы отправляете, уходят за пределы вашей инфраструктуры. Даже если провайдер заявляет о защите данных, это всё равно внешний сервис. А значит, любые утечки, сбои или ошибки интеграции могут привести к реальным рискам.
Поэтому для обработки чувствительных данных чаще используют опенсорсные модели, развёрнутые на собственных серверах. Это даёт контроль — вы знаете, куда уходят данные и что с ними происходит. Но за этот контроль приходится платить: инфраструктура, настройка, поддержка и безопасность — всё на вашей стороне.
Также важно ограничивать модель в правах. Не давайте ей доступ ко всем внутренним системам без фильтров. Настраивайте контроль: что можно обрабатывать, а что нет. И, конечно, не стоит передавать модели пароли, личные данные клиентов или другую информацию, которую вы бы не хотели «потерять».
LLM — это мощный инструмент, но его нужно использовать ответственно. Особенно если вы работаете в B2B, в госструктурах или просто дорожите своей репутацией. Безопасность — не дополнительная опция, а обязательная часть любого внедрения.
Будущее LLM: развитие технологий и рынка
Развитие больших языковых моделей — это уже не хайп, а устойчивый тренд. Компании, которые год назад только пробовали LLM, сегодня интегрируют их в ключевые процессы. И судя по темпам, это только начало.
Модели становятся быстрее, дешевле и компактнее. Если раньше запуск LLM требовал дорогостоящих серверов и месяцев настройки, то сейчас появляются облегчённые версии, которые работают даже на обычных рабочих станциях. Это делает технологию доступной для малого и среднего бизнеса.
При этом растёт и глубина задач, которые решают LLM. Речь уже не только о генерации текста — но и о сложных вычислениях, анализе документов, автоматизации процессов. Модели учатся «читать между строк», запоминать контекст, взаимодействовать с другими системами. Всё это — шаги к полноценному ИИ-ассистенту.
Рынок тоже быстро меняется. Появляются новые игроки, старые пересобирают свои продукты. Опенсорсные модели догоняют (а иногда и обгоняют) коммерческие аналоги. И в будущем, скорее всего, компании будут всё чаще выбирать гибридный путь: часть задач — в облаке, часть — на своих серверах, с полным контролем над данными.
Главное — помнить: LLM — это не волшебная кнопка, а инструмент. Как он себя покажет — зависит от того, как вы его внедрите. Но если подойти к этому с умом, языковая модель может дать вашему бизнесу серьёзное конкурентное преимущество.
Заключение: что важно помнить про большие языковые модели
LLM — это не мода и не игрушка. Это рабочий инструмент, который меняет правила игры в IT, бизнесе, маркетинге и даже в повседневной коммуникации. Но, как и любой инструмент, он требует понимания, зачем и как его использовать.
Если вы просто подключите LLM «для галочки» — результата не будет. Но если подойти осознанно: выбрать подходящую модель, обучить её на своих данных, встроить в реальные процессы и защитить — она может стать частью команды. Быстрой, надёжной и масштабируемой.
Важно помнить: языковая модель не мыслит, не чувствует, не принимает решений. Она опирается на шаблоны, статистику и контекст. Именно вы задаёте ей направление, контролируете, проверяете и обучаете.
LLM — это шанс. Возможность упростить сложное, ускорить рутинное и усилить главное. И чем раньше вы начнёте разбираться в этих моделях, тем легче будет использовать их с умом и на пользу своему делу.
Комментарии (0)
Новый комментарий
Новый комментарий отправлен на модерацию