

Бум генеративного ИИ сделал мощные видеокарты (GPU) из нишевого инструмента обязательным компонентом для любого энтузиаста и исследователя. Этот гайд — не просто перечисление моделей, а система выбора, которая поможет найти оптимальное решение под конкретные задачи и бюджет, с фокусом на актуальность в 2025 году. Для тех, кто спешит: для большинства энтузиастов лучшим выбором по соотношению производительности и объема VRAM остается NVIDIA GeForce RTX 4090, но есть и более сбалансированные варианты, о которых мы поговорим ниже.
Зачем нужна специальная видеокарта для обучения нейросетей: основы для начинающих
Нейросети, особенно в задачах глубокого обучения, требуют огромного количества математических вычислений. Специализированная видеокарта для нейросетей ускоряет обучение моделей в сотни раз по сравнению с обычными процессорами. Её производительность напрямую влияет на то, как быстро вы получите результат, будь то тренировка языковой модели или генерация изображений. Без подходящего GPU многие задачи глубокого обучения становятся практически невыполнимыми из-за долгого времени вычислений.
GPU vs CPU: революция параллельных вычислений
Чтобы понять разницу, представьте двух работников. Центральный процессор (CPU) — это мастер-универсал, который решает сложные и разнотипные задачи последовательно, одну за другой. Графический процессор (GPU) — это армия узких специалистов, которые одновременно выполняют тысячи одинаковых операций. Именно эта способность к массовому параллелизму идеально подходит для матричных вычислений, лежащих в основе работы нейросетей.
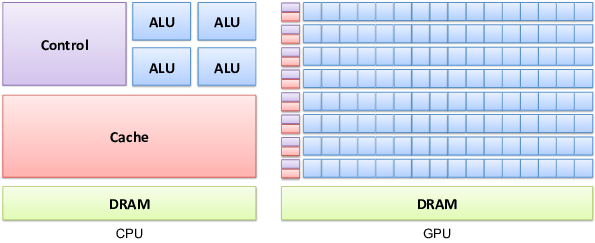
Что такое CUDA-ядра, тензорные ядра и почему это стандарт де-факто
CUDA-ядра — это базовые вычислительные единицы в GPU от NVIDIA, которые выполняют параллельные вычисления. Тензорные ядра — это специализированные блоки внутри GPU, созданные для одной цели: ускорять операции с матрицами. Именно они дают кратный прирост производительности при обучении и использовании нейросетей.
Экосистема NVIDIA CUDA стала индустриальным стандартом не случайно. Практически все основные фреймворки для работы с ИИ, включая TensorFlow и PyTorch, написаны и оптимизированы именно под неё. Как отмечает портал mclouds.ru в статье «GPU для нейросетей: выбор карты для машинного обучения в облаке», «NVIDIA предлагает более мощные GPU, оптимизированные для параллельных вычислений, что критично для задач глубокого обучения. CUDA — стандарт в индустрии, поддерживающий ключевые AI-фреймворки».
Геймерские vs. Профессиональные карты (GeForce vs. RTX Ada): в чем реальная разница для AI
Для экспериментов и работы в одиночку геймерские карты серии GeForce — отличный выбор. Но для критически важных бизнес-задач и научных исследований выбор смещается в сторону профессиональных карт, таких как NVIDIA RTX Ada Generation.
Главные отличия заключаются в надежности и масштабируемости. Профессиональные карты предлагают больший объем памяти и оснащаются технологией ECC (Error-Correcting Code), которая исправляет ошибки «на лету», обеспечивая стабильность вычислений 24/7. Технология NVLink позволяет объединять несколько таких карт в единый вычислительный кластер с общим пулом памяти, что необходимо для обучения гигантских моделей. Вдобавок, профессиональные карты имеют оптимизированные драйверы для стабильной работы в специализированном ПО и расширенную гарантию для круглосуточных нагрузок.
Вывод прост: для личных проектов и фриланса достаточно геймерской карты. Для бизнеса, где стабильность и надежность важнее начальной цены, профессиональные решения незаменимы.
Обучение (Training) vs. Инференс (Inference): как задача влияет на выбор GPU
Выбор видеокарты сильно зависит от того, что вы собираетесь делать: создавать модель с нуля или использовать уже готовую.
- Обучение (Training) — это процесс «тренировки» модели на огромных наборах данных. Он требует максимального объема видеопамяти (VRAM) и высокой производительности для операций с форматами FP16/FP32.
- Инференс (Inference) — это применение уже обученной модели для получения результата. Например, когда вы просите ChatGPT написать текст. Этот процесс обычно менее требователен к VRAM, но важна скорость и низкая задержка, особенно при работе с форматами INT8.
| Параметр | Обучение (Training) | Инференс (Inference) |
|---|---|---|
| Основная задача | Создание, настройка и обновление весов модели на больших датасетах. | Применение готовой модели для получения быстрых предсказаний. |
| Требования к VRAM | Высокие. Нужно вместить модель, данные и градиенты. Часто требуется 24 ГБ и более. | Умеренные. Достаточно, чтобы вместить веса модели. Часто 8-16 ГБ хватает. |
| Требования к вычислениям | Максимальная производительность в FP16/BF16. Важны тензорные ядра. | Важна низкая задержка и высокая производительность в INT8/FP16. |
| Пример задачи | Тренировка языковой модели GPT на корпусе текстов. | Генерация изображения в Stable Diffusion по текстовому запросу. |
Как выбрать видеокарту для нейросетей: главные характеристики
При выборе GPU для ИИ-задач нужно смотреть не на игровые тесты, а на конкретные технические параметры. Важнейшие из них — объём памяти и производительность специализированных ядер. Именно от них зависит, сможете ли вы запустить и обучить нужную модель. Современные видеокарты NVIDIA с архитектурой Ada Lovelace и Hopper предлагают передовые характеристики RTX, включая тензорные ядра нового поколения и поддержку CUDA, что делает их стандартом для ИИ. Не стоит забывать и про пропускную способность памяти, от которой зависит скорость обмена данными. Для большинства задач, связанных с нейросетями, потребуется от 16 ГБ локальной памяти и высокая производительность видеокарты.
Объем видеопамяти (VRAM) — параметр №1 для больших моделей (LLM)
Это самый важный параметр. Вся модель, с которой вы работаете, и обрабатываемые данные (батчи) должны полностью помещаться в локальную память видеокарты. Если объём памяти недостаточен, система начинает использовать медленную оперативную память компьютера, и производительность падает в десятки раз. Для работы с большими языковыми моделями (LLM) этот параметр становится критичным.
- Начальные эксперименты, запуск небольших моделей: 10-12 ГБ (RTX 3060)
- Генерация изображений (Stable Diffusion / Midjourney): 12-16 ГБ (RTX 4060 Ti 16GB)
- Файнтюнинг и запуск средних LLM (7-13B параметров): 24 ГБ (RTX 3090 / 4090)
- Серьезное обучение и запуск больших моделей (>30B): 48 ГБ и более (RTX 6000 Ada)
Производительность: TFLOPS, типы вычислений (FP16/8) и поколение тензорных ядер
Голые цифры TFLOPS в формате FP32, которые часто указывают в игровых обзорах, не так важны для нейросетей. Ключевую роль играет производительность в вычислениях со смешанной точностью (FP16/BF16) и целочисленных форматах (INT8). Именно такие операции ускоряются тензорными ядрами. Каждое новое поколение тензорных ядер приносит значительный прирост эффективности.
Пропускная способность памяти (Memory Bandwidth)
Этот параметр, измеряемый в ГБ/с, можно представить как ширину трубы между вычислительными ядрами GPU и видеопамятью. Чем шире эта «труба», тем быстрее они обмениваются данными. Это критически важно при работе с большими датасетами, когда нужно постоянно подгружать новую информацию для обработки.
Возможность масштабирования: NVLink и тандем из нескольких GPU
Для самых сложных задач по обучению моделей одной карты может быть недостаточно. Профессиональные видеокарты поддерживают технологию NVLink, которая позволяет объединять несколько GPU, создавая общий, гигантский пул видеопамяти. В потребительском сегменте можно объединять карты через шину PCIe, но это менее эффективно, так как память не суммируется, а задачи распределяются на программном уровне.
Экосистема, охлаждение и форм-фактор
При выборе мощной видеокарты убедитесь, что ваш блок питания справится с нагрузкой, а в корпусе достаточно места и хорошая вентиляция. Карты с турбинным типом охлаждения лучше подходят для установки нескольких штук вплотную друг к другу, так как они выбрасывают горячий воздух наружу, а не внутрь корпуса. Если вы собираете сложную систему с несколькими GPU, разумно обратиться к профильным системным интеграторам, которые проверят совместимость всех компонентов и обеспечат правильную сборку.
Топ видеокарт для нейросетей: рейтинг лучших моделей 2025
Этот рейтинг видеокарт для нейросетей составлен на основе баланса производительности, объема памяти и цены на 2025 год. Лидирующие позиции занимают видеокарты NVIDIA, так как их экосистема CUDA остается стандартом для индустрии. В топ видеокарт вошли как флагманские потребительские решения, так и доступные модели прошлых поколений, не потерявшие актуальности благодаря большому объему ГБ памяти. Мы рассмотрим характеристики RTX карт, которые делают их лучшими для обучения моделей и других AI-задач.
1. NVIDIA GeForce RTX 4090 — абсолютный лидер для энтузиастов
24 ГБ быстрой памяти GDDR6X и высокая производительность ядер Ada Lovelace делают эту карту лучшим выбором для локального запуска LLM и их файнтюнинга. На сегодня это оптимальное соотношение цены, производительности и объема VRAM на потребительском рынке. Главные минусы — высокое энергопотребление и цена.
Лучшее применение: запуск и файнтюнинг моделей до 30B параметров, быстрая генерация изображений, MLOps на рабочем месте.

2. NVIDIA RTX 6000 Ada Generation — бескомпромиссный выбор для профессионалов
48 ГБ VRAM с коррекцией ошибок (ECC), поддержка NVLink для объединения нескольких карт, турбинное охлаждение и сертифицированные драйверы. Это стандарт для профессиональных рабочих станций, где требуется максимальная стабильность и возможность обучать действительно большие модели. Цена на порядок выше, чем у игровых карт RTX.
Лучшее применение: R&D в крупных компаниях, обучение коммерческих моделей, работа с моделями 60B+.
3. NVIDIA GeForce RTX 3090 / 3090 Ti — лучший баланс цены и 24 ГБ VRAM
Карта RTX 3090 остается актуальной благодаря своим 24 ГБ VRAM. Ее производительность уступает 4090, но на вторичном рынке эти карты можно найти по привлекательной цене. Это подходящий вариант, если бюджет ограничен, а 24 ГБ памяти — жесткое требование для ваших задач.
Лучшее применение: бюджетный вход в работу с 13-30B моделями, эксперименты с файнтюнингом.
4. NVIDIA GeForce RTX 4080 / SUPER — производительный средний сегмент
16 ГБ VRAM и высокая производительность архитектуры Ada Lovelace. Это отличный выбор для тех, кто в основном занимается генерацией изображений, инференсом и экспериментами с моделями объемом до 13 миллиардов параметров. Однако для серьезного файнтюнинга VRAM может не хватить.
Лучшее применение: Stable Diffusion, инференс, разработка AI-приложений.
5. NVIDIA GeForce RTX 4060 Ti 16GB — бюджетный вход в мир больших моделей
Уникальное предложение на рынке: 16 ГБ VRAM в относительно бюджетном сегменте. Сама по себе карта не самая быстрая из-за узкой шины памяти, но большой объем памяти открывает двери для экспериментов с моделями, которые просто не запустятся на более мощных картах с 8 или 12 ГБ.
Лучшее применение: запуск (инференс) моделей до 13B, обучение с низким размером батча (batch size).
Сравнительная таблица ключевых GPU для нейросетей
| Модель | Объем VRAM (ГБ) | Пропускная способность (ГБ/с) | Производительность (BF16/FP16 TFLOPS) | Энергопотребление (Вт) | Примерная цена ($) | Лучшее применение |
|---|---|---|---|---|---|---|
| RTX 4090 | 24 | 1018 | 82.6 | 450 | ~1600 | AI-энтузиасты, файнтюнинг, генерация |
| RTX 6000 Ada | 48 | 960 | 91.1 | 300 | ~6800 | Профессиональный R&D, обучение больших моделей |
| RTX 3090 | 24 | 936 | ~36 | 350 | ~1000 (б/у) | Бюджетный вход в задачи с 24 ГБ VRAM |
| RTX 4080 SUPER | 16 | 736 | ~52 | 320 | ~1000 | Генерация изображений, инференс, разработка |
| RTX 4060 Ti 16GB | 16 | 288 | ~22 | 165 | ~450 | Бюджетный инференс, эксперименты |
Перспективы 2025: какие видеокарты для нейросетей ожидать в будущем
Рынок GPU не стоит на месте, и уже в 2025 году нас ждут новые видеокарты для нейросетей. Главные ожидания связаны с новым поколением архитектуры Blackwell от NVIDIA. Рост производительности и увеличение объёма памяти позволят решать еще более сложные задачи. Основная интрига — характеристики будущего флагмана RTX 5090.
Ожидания от архитектуры Blackwell (RTX 5090/5080)
Основное ожидание от новой архитектуры — переход на память стандарта GDDR7. Это обеспечит значительный прирост пропускной способности. Главная интрига заключается в том, увеличит ли NVIDIA объём памяти флагмана. Если RTX 5090 получит 32 ГБ VRAM, это станет настоящим прорывом для AI-сообщества и позволит работать с еще более крупными моделями на потребительском железе. По данным аналитического портала Tom's Hardware, архитектура Blackwell может принести существенный прирост производительности за счет новых тензорных ядер и улучшенного производственного процесса.
Останутся ли актуальными карты серии RTX 40
Да, однозначно. После выхода 50-й серии цены на флагманы вроде RTX 4090 и 4080, скорее всего, снизятся. Они останутся отличным выбором по соотношению цены и производительности еще как минимум несколько лет, особенно для тех, кто не гонится за самыми последними технологиями.
Альтернативы NVIDIA: есть ли жизнь без CUDA? (AMD ROCm и Intel Gaudi)
Несмотря на доминирование NVIDIA, конкуренты не спят. AMD активно развивает свою программную платформу ROCm, которая становится все более совместимой с популярными AI-фреймворками. Intel с ускорителями Gaudi нацеливается на корпоративный сегмент. Однако, как отмечается в исследовании mclouds.ru, «AMD уступает NVIDIA по производительности и поддержке экосистемы. ROCm развивается, но не достиг критической массы». Поэтому для энтузиаста и большинства разработчиков в 2025 году экосистема NVIDIA CUDA все еще остается самым простым и надежным выбором.
Аренда GPU в облаке: когда это выгоднее покупки
Покупать собственную мощную видеокарту не всегда целесообразно. Аренда GPU в облаке имеет свои плюсы:
- Доступ к топовому железу: вы можете арендовать самые мощные ускорители (NVIDIA H100,NVIDIA A100), покупка которых обойдется в десятки тысяч долларов.
- Оплата по факту: вы платите только за то время, которое используете.
- Нет проблем с обслуживанием: охлаждение, питание и настройка — забота провайдера.
Минусы тоже есть: в долгосрочной перспективе это может оказаться дороже, а также стоит учитывать задержки сети и вопросы безопасности данных.
Вывод: облачная аренда идеальна для краткосрочных, но сверхтребовательных задач, например, для обучения одной большой модели. Для постоянных экспериментов, разработки и инференса выгоднее иметь собственную карту.
Частые ошибки при выборе GPU: как не потратить деньги зря
Погоня за игровыми TFLOPS без учета реальных задач
Высокая производительность в играх не гарантирует такой же эффективности в AI-задачах. Важнее смотреть на производительность в вычислениях FP16/INT8 и наличие тензорных ядер.
Недооценка важности объема видеопамяти (VRAM)
Это самая частая ошибка. Покупка мощной, но низкообъемной карты приведет к тому, что вы просто не сможете запустить нужную вам модель. Всегда выбирайте максимальный объем VRAM, который позволяет ваш бюджет.
Игнорирование экосистемы, драйверов и поддержки сообщества
Выбрав карту от малоизвестного производителя или без поддержки CUDA, вы рискуете столкнуться с проблемами совместимости, отсутствием нужных библиотек и сложностями в поиске решений.
Покупка карты без учета размеров корпуса и мощности блока питания
Мощные видеокарты большие и прожорливые. Перед покупкой всегда проверяйте, поместится ли карта в ваш корпус и хватит ли мощности блока питания.
FAQ: ответы на популярные вопросы
Сколько видеопамяти нужно для Stable Diffusion в 2025 году?
Для комфортной генерации изображений и использования дополнительных моделей (например, ControlNet) рекомендуется иметь 12-16 ГБ VRAM. На картах с 8 ГБ тоже можно работать, но с некоторыми ограничениями. Для обучения собственных моделей на базе Stable Diffusion лучше ориентироваться на 24 ГБ.
Можно ли использовать две разные видеокарты NVIDIA вместе для AI?
Технически — да, если для обеих карт есть общий драйвер. Фреймворки типа PyTorch позволяют вручную распределять задачи между разными GPU. Однако память (VRAM) при этом не суммируется. Эффективность такой связки сильно зависит от задачи и может быть ниже, чем у одной, но более мощной карты.
Стоит ли покупать б/у видеокарты для нейросетей (Tesla P40, RTX 3090)?
Покупать б/у RTX 3090 — вполне разумная стратегия, если вам нужно 24 ГБ VRAM за минимальные деньги. А вот старые серверные карты вроде Tesla P40 проигрывают по всем статьям: у них нет тензорных ядер, а производительность в вычислениях с плавающей точкой значительно ниже. RTX 3090 будет в разы быстрее.
Что лучше для нейросетей: RTX 4080 SUPER (16GB) или RTX 3090 (24GB)?
Для нейросетей почти всегда лучше RTX 3090 (24GB). Несмотря на то, что RTX 4080 SUPER быстрее в вычислениях, ее 16 ГБ памяти станут узким местом для многих современных моделей. Дополнительные 8 ГБ у RTX 3090 дают гораздо больше гибкости и позволяют работать с более крупными и сложными нейросетями.
Заключение
Выбор видеокарты для нейросетей сводится к простому правилу: определите свой основной сценарий работы, установите бюджет и выберите карту с максимальным объемом VRAM, который можете себе позволить. Производительность важна, но лимит по памяти — это стена, которую не обойти. Для серьезных корпоративных задач, где требуется гарантия и масштабируемость, стоит рассмотреть профессиональные решения и обратиться к системным интеграторам, которые специализируются на поставке и настройке серверного и сетевого оборудования.
Комментарии (0)
Новый комментарий
Новый комментарий отправлен на модерацию