

За последние три года мы наблюдали взрывной рост мультимодальных решений — от экспериментов в лабораториях до промышленного внедрения. Главный вывод: интеграция текста, изображений, аудио и видео в единую систему не просто улучшает качество ответов, а открывает принципиально новые возможности для бизнеса — от автоматизации документооборота до поддержки клиентов в реальном времени.
Что такое мультимодальный ИИ
Мультимодальный ИИ — класс моделей и систем, способных одновременно понимать и генерировать информацию в разных форматах: тексте, изображениях, аудио, видео и речи. В отличие от традиционных систем ИИ, работающих с одним типом данных, мультимодальные модели объединяют сигналы из нескольких источников. Это позволяет улавливать контекст глубже и давать проверяемые, полезные ответы.
Представьте: вы загружаете фотографию неисправного устройства и одновременно диктуете голосовой запрос «Что сломалось?». Система анализирует изображение, распознаёт текст на корпусе, сопоставляет с вашим вопросом — и выдаёт диагноз с указанием на конкретные элементы на фото. Для пользователя это единый интерфейс вместо цепочки шагов. Для бизнеса — рост качества решений и сокращение времени на аналитику.
Важно различать мультимодальную модель (обученную нейросеть, например GPT-4o, Gemini 1.5, Claude 3.5 Vision, LLaVA) и мультимодальную ИИ-систему. Система включает модель плюс пайплайны данных, RAG (retrieval-augmented generation), инструменты OCR/ASR/детекторы, оркестрацию, безопасность, мониторинг и сервинг.
Системный взгляд критичен для продакшена: здесь определяются KPI, приватность, стоимость, латентность. Мультимодальный ИИ особенно силён там, где требуется связка описаний и изображений, распознавание объектов и понимание текста — в документообороте, поддержке клиентов, аналитике видео.
Модель vs система: в чём разница
Мультимодальная модель — обученная нейросеть (например, GPT-4o, Gemini 1.5, Claude 3.5 Vision, LLaVA), принимающая и/или генерирующая разные модальности. Модель — это ядро, которое преобразует входы в выходы.
Мультимодальная ИИ-система — программно-аппаратный комплекс, где модель дополнена слоями:
- Данные: сбор и контроль качества мультимодальных источников.
- Энкодеры: специализированные нейросети для текста (трансформеры), изображений (CNN/ViT), аудио (ASR-модели).
- Модель: мультимодальная LLM/VLM, объединяющая представления.
- RAG: поиск релевантной информации во внешних базах знаний.
- Инструменты: OCR для извлечения текста из изображений, ASR для распознавания речи, детекторы объектов/событий.
- Оркестрация: управление потоками данных, синхронизация модальностей.
- Политики и безопасность: контроль доступа, фильтрация контента, аудит.
- Сервинг и мониторинг: развёртывание, логирование, отслеживание производительности.
Системный взгляд критичен для продакшена. Операционные KPI включают стоимость на запрос, латентность (время ответа), приватность обработки данных. Типовые компромиссы: мультимодальные системы обеспечивают более полное понимание, но требуют больших ресурсов, сложной оркестрации и создают риски приватности. Традиционные модели проще и дешевле, но ограничены одной модальностью.
Модальности и типы данных
Мультимодальные модели работают с разнообразными источниками:
- Текст: документы, сообщения, логи.
- Изображения: фото, диаграммы, сканы документов.
- Аудио: звук, музыка, речь.
- Видео: кадры с временной структурой плюс звук.
- Речь: ASR (автоматическое распознавание речи) и TTS (синтез речи).
- 3D/сенсорные данные: LiDAR, карты глубины.
- Экранные данные: UI-элементы, PDF с макетами.
- Табличные и графовые структуры: структурированные данные для анализа связей.
Каждая модальность имеет типичные задачи и характерные ошибки. Например, изображения могут содержать шум сенсора, размытие, плохое освещение. Аудио страдает от фонового шума, эха, искажений микрофона. PDF и сканы часто имеют низкое качество OCR и искажения сканирования.
| Модальность | Примеры источников | Типичные задачи | Частые ошибки/шум |
|---|---|---|---|
| Фото | Камеры, смартфоны | Классификация, детекция объектов, сегментация | Размытие, шум сенсора, низкая освещённость |
| Диаграммы и PDF | Сканеры, документооборот | Извлечение текста, распознавание графиков | Искажения сканирования, низкое качество OCR |
| Аудио/музыка | Микрофоны, записи | Распознавание речи, классификация жанров | Фоновый шум, эхо, искажения микрофона |
| Видео | Камеры, видеонаблюдение | Детекция движения, трекинг, классификация сцен | Размытие движения, артефакты сжатия |
| Речь | Голосовые ассистенты, кол-центры | Распознавание, синтез, анализ эмоций | Фоновые шумы, прерывания, акценты |
| 3D/LiDAR/глубина | Сенсоры автономных систем | Реконструкция сцены, навигация | Пропуски данных, отражения, шумы сенсоров |
| Экранные данные | Скриншоты, тестирование программного обеспечения | Распознавание интерфейсов, анализ взаимодействия | Артефакты скриншотов, низкое разрешение |
| Таблицы/графы | Финансовые отчёты, базы данных | Извлечение структурированных данных, анализ связей | Ошибки парсинга, неполные данные |
Архитектура и принципы обучения мультимодальных моделей ИИ
Мультимодальные архитектуры решают задачу согласования представлений из разных источников, чтобы улучшить качество результатов модели. Базовый путь: энкодеры извлекают признаки из визуальных данных и текста, затем слои внимания соединяют их в общий латентный простор.
Обучение моделей строится на:
- Контрастивных целях: например, выравнивание описаний и изображений (подход CLIP — модель учится связывать текстовые описания с соответствующими изображениями через контрастивное обучение).
- Автодополнении (captioning): модель генерирует текстовые описания по изображению.
- Инструкционном дообучении: модель учится следовать инструкциям пользователя для диалогового поведения (например, InstructBLIP систематически изучает мультимодальное instruction tuning на базе BLIP-2).
- RLHF (Reinforcement Learning from Human Feedback): обучение с подкреплением на основе оценок человека для улучшения качества ответов.
Современные вычислительные системы оптимизируют пропускной поток, ускоряют кросс-аттеншн и уменьшают латентность. В системах также обучают модели работать с инструментами (OCR/ASR/детекторы), чтобы повышать точность на реальных документах и видео.
Принципы масштабирования включают увеличение данных, контекста и параметров, но важнее качество источников и выравнивания сигналов. Для безопасности применяют фильтры данных и постобучение с обратной связью человека.
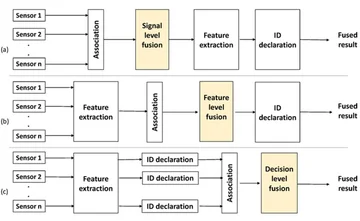
Ключевые паттерны слияния модальностей:
- Раннее слияние (feature-level): объединение сырых данных или признаков на входе, модель обучается сразу на всех модальностях. Преимущество — глубокая интеграция. Недостаток — высокая вычислительная сложность.
- Позднее слияние (decision-level): независимая обработка каждой модальности, затем объединение результатов (например, голосование или усреднение). Преимущество — модульность. Недостаток — может упустить межмодальные связи.
- Гибридное слияние: комбинация раннего и позднего подходов для баланса точности и эффективности.
- Кросс-аттеншн и трансформеры: основной механизм фьюжна в современных моделях — механизмы внимания позволяют модели учитывать взаимосвязи между разными последовательностями и модальностями.
Обучение и дообучение:
- Инструкционное обучение: модель учится следовать инструкциям пользователя (например, "Опиши изображение", "Ответь на вопрос по документу").
- RLHF: обучение с подкреплением на основе оценок человека для улучшения качества ответов и снижения галлюцинаций.
- Мультимодальные промпты и цепочки мыслей: использование структурированных промптов для направления модели к более точным и обоснованным ответам.
- Выравнивание на задачах: VQA (Visual Question Answering), captioning (генерация описаний), retrieval (поиск по запросу), grounding (привязка объектов на изображении к тексту).
Примеры моделей и сравнение
Закрытые модели
GPT-4o (OpenAI, май 2024): мультимодальный (текст, изображения, аудио, видео), контекст 128K токенов, доступен через API и ChatGPT. В 2 раза быстрее и в 2 раза дешевле GPT-4 Turbo, поддерживает более 50 языков, обработка аудио с сохранением эмоций и тона. Сильные стороны: разговорная мультимодальность, хороший контекст, tool-use (вызов внешних инструментов).
Gemini 1.5 Pro (Google, февраль 2024): мультимодальный (текст, изображения, аудио, видео), контекст до 1 млн токенов (2 млн по запросу), доступен через API. Длинный контекст, мультимодальная память. Цена $7 за 1 млн токенов.
Claude 3.5 Vision (Anthropic): качественные ответы, осторожные политики безопасности, акцент на этичности и предотвращении вредоносного контента.
Открытые модели
CLIP (OpenAI): связывает текстовые описания с изображениями через контрастивное обучение. Открытая модель, широко используется для задач retrieval и zero-shot классификации изображений.
BLIP-2: эффективная архитектура для выравнивания визуальных и текстовых представлений с языковыми моделями.
Flamingo: модель для few-shot обучения на мультимодальных задачах.
LLaVA (Large Language and Vision Assistant): открытая мультимодальная LLM, достигает 92.5% точности на ScienceQA (21 000+ вопросов), выполняет OCR, генерацию описаний и визуальное рассуждение.
Qwen-VL, InternVL, PaliGemma, IDEFICS, Fuyu, MiniGPT-4: разнообразные открытые модели с разными архитектурами и специализацией на конкретных задачах.
Таблица сравнения моделей
| Модель | Тип | Модальности | Макс контекст | Лицензия | Ресурсоёмкость | Типовые задачи | Особенности | Доступность (API/локально) |
|---|---|---|---|---|---|---|---|---|
| GPT-4o | Закрытая LLM | Текст, изображение, аудио, видео | 128K токенов | Проприетарная | Высокая | Мультимодальный чат, перевод, анализ контента | Реальное время, 50+ языков | API, ChatGPT |
| Gemini 1.5 Pro | Закрытая LLM | Текст, изображение, аудио, видео | До 1 млн токенов | Проприетарная | Очень высокая | Длинный контекст, мультимодальные приложения | Мультимодальная память | API |
| Claude 3.5 Vision | Закрытая LLM | Текст, изображение | Не раскрыт | Проприетарная | Средняя | Безопасный чат, RLHF | Фокус на этичности | API |
| LLaVA | Открытая VLM | Текст, изображение | Не указано | Open source | Средняя | VQA, OCR, captioning | 92.5% на ScienceQA | Локально, API |
| CLIP | Открытая | Текст, изображение | – | Open source | Низкая–средняя | Retrieval, zero-shot классификация | Контрастивное обучение | Локально, API |
| BLIP-2 | Открытая VLM | Текст, изображение | – | Open source | Средняя | VQA, captioning, выравнивание к LLM | Эффективная архитектура | Локально, API |
| Flamingo | Открытая VLM | Текст, изображение, видео | – | Исследовательская | Высокая | Few-shot обучение | Гибридная архитектура | Исследовательский доступ |
Задачи и бенчмарки
Типовые задачи
VQA (Visual Question Answering): ответы на вопросы по изображению. Пример: "Сколько людей на фото?"
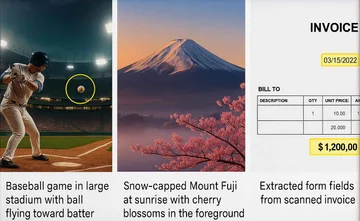
Captioning: генерация текстовых описаний к изображениям или видео. Пример: модель генерирует подпись "Baseball game in large stadium with ball flying toward batter" к фото бейсбольного матча.
Retrieval: поиск релевантных изображений или текстов по запросу. Метрика: Recall@K.
Grounding: привязка объектов на изображении к тексту. Оценивается через mAP и IoU accuracy.
DocVQA: вопросно-ответный анализ документов. Модель отвечает на вопросы по содержимому PDF или скана. Основная метрика: ANLS (Average Normalized Levenshtein Similarity), также используются accuracy и F1.
ChartQA: вопросно-ответный анализ диаграмм и графиков. Применяется точное совпадение с нормализацией, при вариациях символов — ANLS-подобное мягкое совпадение.
Instruction Following: выполнение многошаговых инструкций на основе мультимодальных данных.
Video QA: ответы на вопросы по видео. ViteVQA включает 7,620 видео и 25,123 QA, метрики включают accuracy с учётом временного и мультимодального анализа.
Бенчмарки и метрики
MMBench: систематический бенчмарк для оценки мультимодальных моделей, 2974 multiple-choice вопросов, 20 измерений способностей, двуязычный (англ/кит) формат. Оценка через CircularEval.
MMMU: мультимодальный бенчмарк для оценки моделей на задачах, требующих глубокого понимания и рассуждений.
MME: комплексный бенчмарк для оценки точности и устойчивости мультимодальных моделей.
VQAv2: классический бенчмарк визуальных вопросов и ответов, базовый стандарт. Метрика: точность ответов на визуальные вопросы.
Метрики:
- Accuracy: доля правильных ответов.
- BLEU/CIDEr/ROUGE: метрики для оценки качества генерации текста (captioning).
- Recall@K: доля релевантных результатов в топ-K (для retrieval).
- mAP: средняя точность для задач grounding и детекции.
Как корректно сравнивать результаты: использовать одинаковые версии датасетов, чётко фиксировать параметры предобработки (например, размер патчей в DocVQA влияет на ANLS и accuracy), учитывать специфику задачи (например, в ChartQA допускается мягкое совпадение).
| Бенчмарк | Модальности | Навыки | Тип метрик | Пример значения (диапазон) |
|---|---|---|---|---|
| VQAv2 | Текст + изображение | Понимание визуального контекста | Accuracy | 70–85% |
| DocVQA | Текст + изображение (документы) | Понимание текста и структуры документов | ANLS, Accuracy, F1 | 70–85% (ANLS) |
| ChartQA | Текст + изображение (графики) | Извлечение данных из визуализаций | Exact match, ANLS | 60–75% |
| MMBench | Мультимодальность (текст + изображение) | Комплексное понимание, 20 способностей | Accuracy (multiple-choice) | 65–80% |
| ViteVQA | Видео + текст | Временной и мультимодальный анализ | Accuracy | 50–70% |
| MME | Мультимодальность | Точность и устойчивость | Accuracy, robustness score | 60–75% |
Возможности мультимодального ИИ: от анализа до генерации
Анализ и описание изображений
Мультимодальные модели расширяют спектр возможностей ИИ в обработке изображений: они распознают объекты, отношения и текст на кадре, связывая это с вопросом пользователя. Такой анализ изображений помогает в документообороте, техподдержке и контроле качества.
Система может отвечать на вопросы к изображениям (VQA), подсвечивать элементы (grounding) и генерировать описание контента (captioning) для людей и поисковых роботов. Например, LLaVA выполняет OCR, генерацию описаний и визуальное рассуждение с точностью 92.5% на ScienceQA.
В продакшене это позволяет автоматизировать проверку документов, извлекать данные из сканов, помогать клиентам "на картинке" и проверять соответствие нормам.
Генерация изображений по текстовому запросу
Генеративный ИИ позволяет преобразовывать идеи в визуальные решения: от концептов продукта до маркетинговых макетов. Генерацию изображений управляют через промпты, негативные подсказки и референсы.
Модели типа DALL-E 3 создают изображения по текстовому описанию. Например, промпт "Snow-capped Mount Fuji at sunrise with cherry blossoms in the foreground" генерирует соответствующее изображение.
В продакшене важны безопасность, лицензии на данные и контроль стиля, чтобы обеспечить соответствие бренду и юридическим требованиям. Применяют фильтры контента, водяные знаки и аудит генерируемых материалов.
Взаимодействие с визуальными данными в продуктах
Бизнес-сценарии включают поиск по каталогам, извлечение данных из сканов, помощь пользователю "на картинке" и проверку соответствия нормам. Визуальные данные сочетают с текстовыми документами и диалогом, что повышает точность ответов и снижает время решения.
Это ядро современных ассистентов и аналитических панелей, где текст и изображение работают вместе. Например, система поддержки анализирует скриншот ошибки и текстовое сообщение пользователя, выдавая комплексную инструкцию за 3 минуты вместо 10 минут ручной обработки.
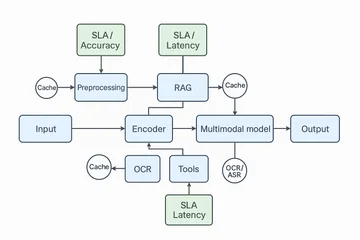
Как устроена мультимодальная система
Пайплайн
Мультимодальная система 2025 строится как последовательный pipeline:
- Ingestion данных: сбор и интеграция данных из разных источников (текст, изображение, аудио, видео) с контролем качества и выравниванием по контексту. Включает HITL (human-in-the-loop) для аннотаций и калибровки.
- Предобработка: нормализация, очистка, токенизация, специализированные преобразования для каждого типа данных (например, аудио в спектрограммы, изображения в тензоры).
- Энкодеры: отдельные нейросети для каждого модального типа (NLP-модели для текста, CNN/ViT для изображений, ASR-модели для аудио), преобразующие данные в векторные представления.
- Мультимодальная модель: крупные мультимодальные модели (например, GPT-4o, Gemini) обрабатывают объединённые представления для генерации ответов или действий.
- RAG (Retrieval-Augmented Generation) / векторные базы: поиск релевантной информации во внешних источниках, интегрированной с моделью для повышения точности. Используются векторные базы данных (например, FAISS) для семантического поиска.
- Инструменты OCR/ASR/детекторы: специализированные инструменты для извлечения текста из изображений (OCR), распознавания речи (ASR) и детекции объектов/событий, интегрируемые в pipeline.
- Оркестрация и политики: управление потоками данных, контроль качества, этические и операционные политики, автоматизация и масштабирование с помощью систем LLMOps и HITL.
- Сервинг и логи: развёртывание моделей с мониторингом производительности, сбором логов для аудита и улучшения, поддержка real-time inference.
Производительность
Типичные бюджеты латентности для моделей в 2025: быстрые модели — около 50 мс, точные — до 200 мс, премиум — до 1000 мс.
Масштабирование обеспечивается автоскейлингом Kubernetes с динамическим распределением ресурсов, поддержкой canary и A/B тестирований для безопасного и контролируемого развертывания.
A/B тестирование сравнивает версии моделей по бизнес-метрикам (например, CTR). Canary deployment постепенно увеличивает трафик на новую версию для минимизации рисков.
Edge vs cloud выбор: edge предпочтителен для низкой латентности и локальной обработки данных с высокими требованиями к конфиденциальности (PII), cloud — для масштабируемости и централизованного управления. Выбор зависит от требований к SLA.
Снижение стоимости достигается:
- Квантованием: уменьшение точности весов модели с сохранением качества, сокращает вычислительные ресурсы до 70–90%.
- Дистилляцией: перенос знаний из больших моделей в компактные, что позволяет сократить вычислительные ресурсы до 90%.
- Батчингом: обработка данных пакетами для увеличения пропускной способности.
- Кэшированием: хранение промежуточных результатов для снижения задержек.
Мониторинг ключевых метрик: latency, error rate, queue depth, success ratio — обязательны для оценки производительности и принятия решений о масштабировании и откате.
Приватность и безопасность
PII-маскирование: автоматическая замена персональных данных перед обработкой.
Контент-фильтры: автоматические системы для блокировки вредоносного, дискриминационного или неэтичного контента.
Аудит: регулярная проверка логов и решений модели для выявления предвзятости и ошибок.
Ретеншн-стратегии: политики хранения и удаления данных в соответствии с регуляциями (GDPR, HIPAA).
Guardrails: политика инструментов, ограничения на генерацию (например, запрет на создание дипфейков), водяные знаки для отслеживания генерируемого контента.
Применение и бизнес-кейсы
Отрасли и сценарии
Ассистенты и поддержка клиентов: анализ вложений, скриншотов, голосовых сообщений. Система обрабатывает текстовые сообщения, скриншоты ошибок и аудиозаписи пользователей, выдавая комплексные инструкции. Время ответа снижается с 10 до 3 минут.
Документооборот: DocVQA, распознавание форм, договоров. Система анализирует сканы документов, распознаёт текст и изображения, автоматически заполняет реестры и ищет несоответствия. Это сокращает ручной ввод на 40%.
Аналитика видео: безопасность, производство, ритейл. Модель распознает объекты, действия, речь и субтитры в ролике, формируя сводки для маркетинга или безопасности. Точность детекции событий растёт на 20% против одноканальных систем.
Медицина: анализ медицинских снимков и истории болезни, интеграция данных для диагностики. AI-система для прогноза пропусков МРТ-обследований снизила долю no-show с 19,3% до 15,9% за 6 месяцев (использовалась модель XGBoost). AI-алгоритм прогноза госпитализаций при сердечной недостаточности достиг 93% recall и 90% precision. AI-платформа для анализа радиологических отчётов повысила продуктивность онкологов на 20%.
Образование и доступность: интерактивные учебные материалы, анализ ответов учеников по нескольким модальностям, генерация описаний и субтитров для людей с ограниченными возможностями.
Автономный транспорт и робототехника: обработка видео, данных сенсоров, аудио для восприятия окружения и принятия решений в реальном времени.
KPI и бизнес-метрики
Ключевые показатели эффективности мультимодальных решений:
- Точность/покрытие кейсов: доля задач, решённых системой без эскалации.
- Время ответа: латентность от запроса до выдачи результата.
- Стоимость/запрос: операционные затраты на обработку одного запроса.
- NPS (Net Promoter Score): удовлетворённость пользователей.
- Доля автоматизации: процент задач, выполненных без участия человека.
- Количество эскалаций: доля случаев, требующих вмешательства специалиста.
| Кейс | Метрика | Базовый уровень | Целевой уровень | Метод улучшения |
|---|---|---|---|---|
| Поддержка клиентов | Время ответа | 10 мин | 3 мин | Мультимодальный анализ (текст + скриншоты + аудио) |
| Документооборот | Доля ручного ввода | 100% | 60% | OCR + RAG + тонкая настройка модели |
| Аналитика видео | Точность детекции | 70% | 85–90% | Мультимодальная модель (видео + аудио + текст) |
| Медицина (прогноз госпитализаций) | Recall | 70% | 93% | Интеграция данных снимков и истории болезни |
FAQ по мультимодальным ИИ
Чем мультимодальный ИИ отличается от обычного чат-бота типа ChatGPT?
ChatGPT (унимодальный) работает только с текстом. Мультимодальный ИИ объединяет несколько каналов восприятия (визуальный, аудио, физиологический), тогда как чат-боты обычно работают с текстом или голосом.
Мультимодальный ИИ способен комплексно анализировать эмоции и контекст, повышая качество взаимодействия. Например, система может одновременно анализировать текстовое сообщение, скриншот ошибки и голосовую запись, выдавая комплексную инструкцию.
Может ли мультимодальный ИИ понимать эмоции?
Да. Мультимодальное распознавание эмоций использует данные с лица, голоса, речи, а также физиологические показатели (ЭЭГ, вариабельность сердечного ритма, электропроводность кожи) для создания точного эмоционального профиля. ИИ не «чувствует» эмоции, а адекватно реагирует на их признаки. Анализируя сразу голос, выражение лица, текстовый контекст, мультимодальные модели лучше распознают эмоции, чем унимодальные.
Какие навыки нужны для работы с мультимодальными моделями?
Разработка мультимодальных ИИ требует знаний в области глубокого обучения, обработки аудиовизуальных данных, нейросетевых архитектур (например, трансформеров). Также необходимо понимание этических аспектов и защиты персональных данных. Для интеграции — знание API, data engineering, machine learning, understanding фреймворков (PyTorch, JAX), векторных баз данных.
Безопасно ли использовать мультимодальный ИИ для личных данных?
Риски те же, что и для обычного ИИ: утечки, предвзятость, некорректная интерпретация. Современные системы применяют локальную обработку данных, фильтрацию кадров, предобученные модели для снижения объема передаваемой информации и защиты приватности. Требуется прозрачная политика обработки персональных данных и аудит сервисов. Для критичных сценариев — использовать edge-развёртывание и PII-маскирование.
Комментарии (0)
Новый комментарий
Новый комментарий отправлен на модерацию