

Что такое технология NVIDIA MIG (Multi-Instance GPU) и для чего она нужна
NVIDIA Multi-Instance GPU (MIG) — это аппаратная технология от NVIDIA, позволяющая безопасно и эффективно разделять один физический GPU на несколько (до семи) полностью изолированных GPU-инстансов. Каждый такой инстанс получает собственные выделенные ресурсы: потоковые мультипроцессоры (SM), кэш L2 и видеопамять, что делает его видимым для операционной системы и приложений как отдельный, независимый GPU. У NVIDIA есть и другие решения, но MIG выделяется аппаратной изоляцией.
Основная цель технологии MIG — максимизировать утилизацию дорогих ускорителей, позволяя одновременно запускать разнородные рабочие нагрузки на одной карте без взаимного влияния. Это могут быть и обучение моделей, и инференс, и научные вычисления (GPU compute). Решение подходит для дата-центров, облачных провайдеров и команд, которым необходимо предоставить гарантированные GPU-ресурсы для множества пользователей или задач. Как показывают кейсы от AWS, это позволяет запускать на одном GPU до 7 раз больше контейнеров, повышая эффективность и рентабельность.
Ключевые преимущества MIG над другими методами разделения
Чтобы понять место MIG, полезно сравнить эту технологию с другими подходами к разделению GPU.
| Параметр | NVIDIA MIG | NVIDIA vGPU (Virtual GPU) | Time-Slicing (Временное разделение) |
|---|---|---|---|
| Уровень изоляции | Аппаратный, полная изоляция ресурсов (память, SM, кэш). | Программный, изоляция на уровне гипервизора между виртуальными машинами. | Отсутствует. Процессы конкурируют за общие ресурсы. |
| Гарантия производительности (QoS) | Высокая. Предсказуемая производительность благодаря выделенным ресурсам. | Средняя. Производительность зависит от расписания гипервизора и нагрузки "соседей". | Низкая и непредсказуемая. Зависит от количества и характера одновременных задач. |
| Поддерживаемые нагрузки | Вычислительные задачи (CUDA), ИИ, HPC. Идеально для контейнеров и bare-metal. | Виртуальные рабочие столы (VDI), графика, смешанные нагрузки в ВМ. | Легкие, нетребовательные задачи. Legacy-сценарии. |
| Основной сценарий | Облачные провайдеры, Kubernetes-кластеры, Data Science команды. | Средства виртуализации (VMware, Citrix), корпоративные VDI-решения. | Простое совместное использование GPU на старых архитектурах. |
Режимы использования: Single GPU, Full GPU и разделение с помощью MIG
При работе с GPU от NVIDIA, которые поддерживают MIG, доступны разные режимы работы.
- Single GPU — это классический режим, где один процесс монопольно использует все ресурсы видеокарты. Этот подход оправдан для тяжелых вычислений, способных загрузить ускоритель полностью. Если же задача задействует лишь малую часть мощности, ресурсы простаивают.
- Full GPU в контексте MIG означает, что весь GPU работает как один, но уже аппаратно изолированный инстанс.
- Разделение с помощью MIG — основной сценарий использования технологии. Физические ресурсы GPU делятся на независимые инстансы, что позволяет достичь лучшей производительности на ватт и на вложенный рубль. Такой подход обеспечивает параллельное выполнение множества задач с гарантированным качеством сервиса (QoS), в отличие от простого временного разделения, где производительность непредсказуема.
Сценарии использования: кому и зачем нужен MIG?
Технология MIG находит применение в сферах, где требуется эффективное управление дорогими GPU-ресурсами.
Для DevOps и IT-администраторов
Основная задача — повысить утилизацию серверов в дата-центре. MIG позволяет предоставлять изолированные GPU-среды командам разработки и QA без необходимости покупать дополнительные физические карты. Это упрощает управление инфраструктурой и снижает операционные расходы.
Для Data Science и ML-команд
MIG решает проблему "очереди" к GPU. Можно выделить персональный GPU-инстанс каждому аналитику для интерактивных сессий в Jupyter. Это также позволяет одновременно запускать несколько экспериментов по обучению или инференсу разных моделей на одной физической карте, что ускоряет цикл разработки.
Для облачных провайдеров
Технология дает возможность создавать более гранулярные и доступные GPU-сервисы. Клиенты, которым не нужен целый A100 или H100 для своих задач, могут арендовать небольшой инстанс, что снижает порог входа и расширяет клиентскую базу.
Основные понятия MIG: GPU Instance и MIG Profile
Для работы с технологией важно понимать два ключевых термина: GPU Instance (GI) и MIG Profile.
GPU Instance (GI) — это логический раздел физического GPU. Он обладает собственным набором вычислительных ресурсов (потоковых мультипроцессоров) и выделенным объемом видеопамяти (GPU memory). По сути, это аппаратный "срез" видеокарты, который операционная система видит как отдельное устройство. Каждый такой mig instance полностью изолирован.
MIG Profile (Профиль MIG) — это предопределенная конфигурация или "шаблон" для создания GPU Instance. Набор доступных профилей MIG зависит от модели GPU. Профиль описывает, сколько вычислительных ресурсов, какой объем памяти и какие дополнительные движки (например, декодеры видео) получит создаваемый инстанс. Название профиля отражает его характеристики: например, 1g.10gb создаст инстанс с 1/7 вычислительной мощности и 10 ГБ памяти.
Из одного GPU Instance можно создать один или несколько Compute Instances (CI). Это уже программный интерфейс, который видят и используют приложения. Иерархия выглядит так: один физический GPU делится на несколько GPU-инстансов, а каждый GI, в свою очередь, может содержать один или несколько Compute-инстансов. Выбор правильных профилей — ключевой шаг при настройке системы с MIG.
Совместимость: какие GPU и конфигурации поддерживают MIG
Технология MIG доступна не на всех видеокартах NVIDIA. Она реализована на аппаратном уровне в профессиональных ускорителях для дата-центров.
Поддерживаемые архитектуры GPU
| Архитектура | Модели GPU | Макс. инстансов |
|---|---|---|
| A100, A30 | 7 | |
| H100, H200 | 7 | |
| B100, B200 | 7 |
Обзор доступных MIG-профилей
Названия профилей стандартизированы. Например, mig profile 1g.10gb означает:
1g— 1 срез вычислительных ресурсов (Compute Slice).10gb— 10 гигабайт выделенной видеопамяти.
Количество доступных срезов и объем памяти зависят от конкретной модели GPU. Например, на ускорителе A100 80GB можно создать до семи инстансов с профилем 1g.10gb или два инстанса 3g.40gb и один 1g.10gb.
Практическое руководство: как управлять MIG с помощью nvidia-smi
Управление режимом MIG осуществляется через утилиту командной строки nvidia-smi. Для выполнения большинства команд требуются права суперпользователя (sudo nvidia).
Шаг 1: Включение режима MIG
Сначала необходимо перевести GPU в режим MIG. Для карт на архитектуре Ampere это можно сделать "на лету", тогда как для Hopper и новее может потребоваться перезагрузка GPU. Команда выполняется для конкретного GPU по его индексу (в примере — 0).
Команда:
sudo nvidia-smi -i 0 -mig 1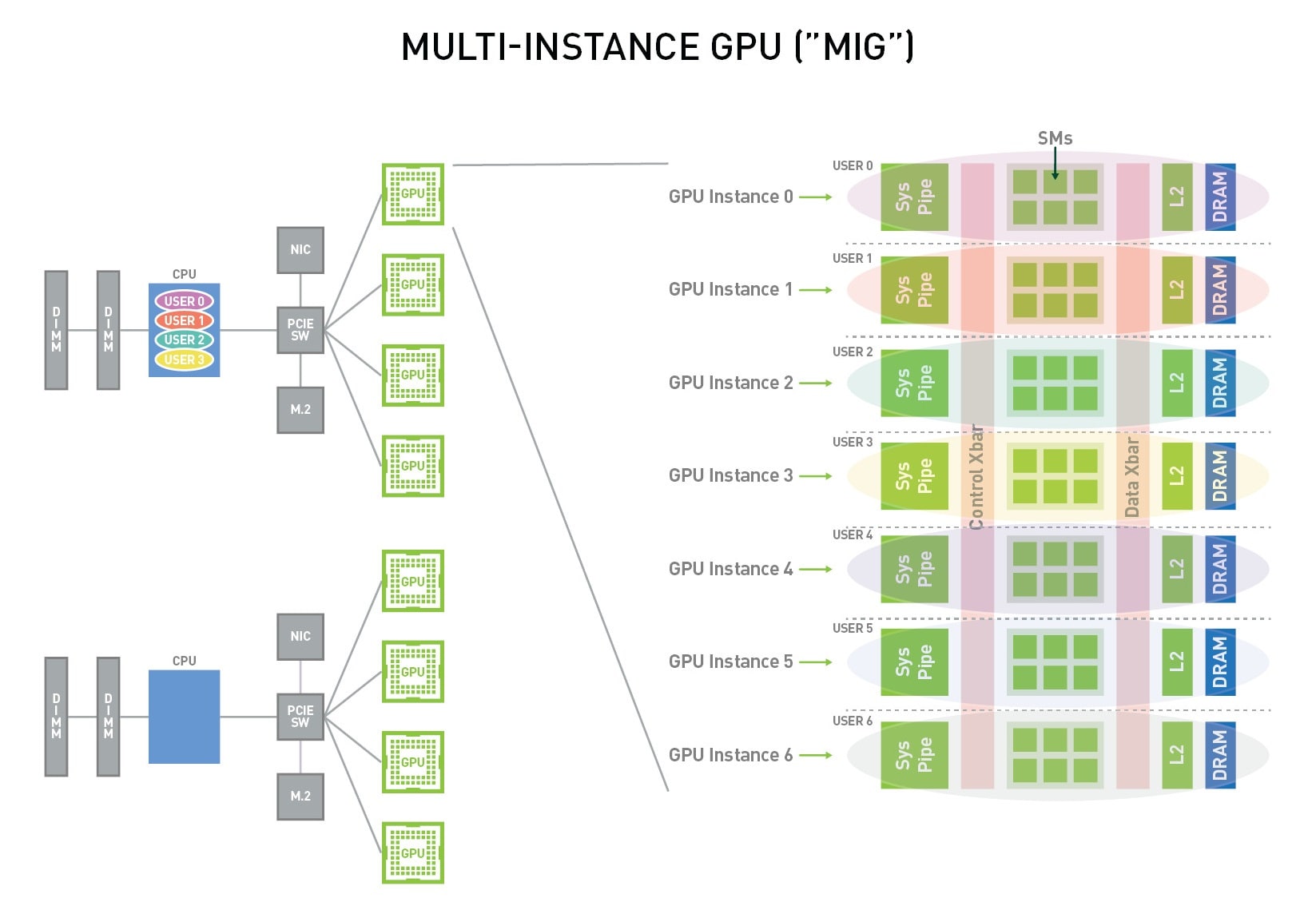
Шаг 2: Просмотр доступных профилей
После включения MIG Mode нужно изучить, какие профили для создания инстансов доступны на вашем GPU.
Команда:
nvidia-smi mig -lgipЭта команда выведет список доступных профилей GPU Instance (GI) и их идентификаторы.
Шаг 3: Создание GPU-инстансов (GI)
Используя ID профиля из предыдущего шага, можно создать один или несколько GPU-инстансов. Флаг -C применяет конфигурацию. Для работы с nvidia smi mig требуются соответствующие права.
Пример создания инстансов по списку профилей:
# Создаем два инстанса с профилем 1g.10gb (ID 19) и один с 3g.20gb (ID 9)
sudo nvidia-smi mig -i 0 -cgi 19,19,9 -CШаг 4: Запуск приложений и мониторинг
Созданные MIG-устройства появятся в системе как отдельные устройства со своими UUID, которые можно посмотреть командой nvidia-smi -L. Чтобы запустить приложение на конкретном инстансе, используется переменная окружения CUDA_VISIBLE_DEVICES. Развертывание и на GPU, и на MIG-инстансах требует внимания к деталям.
Пример:
CUDA_VISIBLE_DEVICES=MIG-xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx python my_app.pyМониторинг использования ресурсов каждого инстанса выполняется стандартной командой nvidia-smi, которая покажет загрузку и использование памяти для каждого MIG-устройства отдельно.
Как отключить режим MIG (MIG Mode)
Для отключения MIG Mode и возврата GPU в обычный режим используется команда nvidia-smi с параметром 0. Некоторые системы интерпретируют этот параметр как false, поэтому в документации встречается термин false mig mode. Эта операция удалит все созданные инстансы, поэтому перед ее выполнением нужно убедиться, что на них не выполняются рабочие нагрузки.
Команда:
sudo nvidia-smi -i 0 -mig 0Интеграция с Kubernetes: NVIDIA GPU Operator и MIG
В контейнерных средах, таких как Kubernetes, управление MIG автоматизируется с помощью NVIDIA GPU Operator. Этот оператор — ключевой компонент для работы с GPU в кластере. Он обнаруживает ускорители на узлах, устанавливает необходимые драйверы и плагины, а также управляет ресурсами.
Когда на узле включен MIG, GPU Operator автоматически распознает созданные инстансы и представляет их как доступные ресурсы в Kubernetes. Это позволяет запрашивать конкретный тип MIG-профиля прямо в YAML-манифесте пода. Разработчикам не нужно думать о UUID-устройств, достаточно указать нужный профиль.
Пример запроса ресурса в YAML-манифесте Pod'а:
spec:
containers:
- name: my-container
image: my-gpu-app
resources:
limits:
nvidia.com/gpu: 1 # Запрашиваем один GPU ресурс
annotations:
nvidia.com/mig-profile: '1g.10gb' # Уточняем, что нам нужен инстанс этого профиляТакой подход делает разделение GPU прозрачным и легко встраиваемым в CI/CD процессы.
Лучшие практики и частые ошибки
Как правильно выбрать размер MIG-инстанса?
Выбор зависит от требований приложений:
- Для задач инференса с небольшими моделями часто достаточно профилей
1g.Xgbили2g.Xgb. Главный критерий — чтобы модель помещалась в память инстанса. - Для разработки и экспериментов могут потребоваться более крупные инстансы, чтобы обеспечить комфортную интерактивную работу.
Рекомендация: начните с минимально возможного профиля и отслеживайте реальное потребление ресурсов. Масштабируйте инстанс, если приложение сталкивается с нехваткой памяти или вычислительной мощности.
Ограничения, о которых нужно знать
- Отсутствие NVLink между инстансами. MIG-инстансы, даже находясь на одной физической карте, не могут обмениваться данными через высокоскоростную шину NVLink. Вся коммуникация идет через системную шину PCIe, что медленнее. Это снижает эффективность MIG для задач распределенного обучения одной большой модели.
- Фиксированные ресурсы. Ресурсы инстанса (память, SM) выделяются статически. Изменить профиль инстанса "на лету" без его пересоздания невозможно.
Часто задаваемые вопросы (FAQ)
В чем ключевое отличие MIG от виртуализации NVIDIA vGPU?
MIG — это аппаратное разделение с гарантированной производительностью (QoS), предназначенное для bare-metal и контейнерных сред (Docker, Kubernetes). vGPU — это технология для сред виртуализации, таких как VMware и Citrix, где ресурсы GPU разделяются между несколькими виртуальными машинами с помощью гипервизора. MIG идеален для вычислительных задач, vGPU — для виртуализации рабочих столов (VDI) с графикой.
Можно ли изменять MIG-конфигурацию "на лету"?
Да, для GPU на архитектуре Ampere и новее. Можно удалять и создавать MIG-инстансы без перезагрузки сервера. Однако активные процессы на удаляемом инстансе будут прерваны. На архитектурах Hopper и Blackwell гибкость еще выше, но для некоторых изменений все еще может потребоваться сброс GPU.
Как MIG влияет на доступность движков кодирования/декодирования видео (NVENC/NVDEC)?
Ресурсы аппаратных движков NVENC/NVDEC также разделяются между MIG-инстансами. Как отмечает NVIDIA в своих руководствах, в архитектурах Blackwell и Hopper каждому инстансу могут быть выделены собственные движки. MIG-профиль определяет, какая доля этих ресурсов будет доступна инстансу, что важно для задач видеоаналитики и стриминга.
Комментарии (0)
Новый комментарий
Новый комментарий отправлен на модерацию