

Оптимизация энергопотребления серверов в 2025 году опирается на три опоры: энергоэффективное оборудование, продуманную архитектуру и постоянный мониторинг. Практика крупных ЦОД показывает: совокупный эффект от модернизации серверов, оптимизации охлаждения и настройки программного обеспечения достигает 30–50% экономии электроэнергии без потери надежности и производительности. Исследование 174PowerGlobal за 2024 год фиксирует, что наиболее эффективные серверы дают тот же вычислительный результат при на 30–40% меньшем потреблении энергии по сравнению с устаревшими моделями.
Главные технические тенденции:
- переход на серверы высокой плотности (Dell, HPE, Lenovo, IBM) с процессорами Intel Xeon и AMD EPYC 5–7 нм и блоками питания уровня 80 PLUS Platinum/Titanium
- замена HDD на NVMe-SSD, что снижает энергопотребление дисковой подсистемы на 50–70%.
- внедрение жидкостного охлаждения (direct-to-chip, иммерсионное) и free cooling, что уменьшает энергопотребление на охлаждение датацентра на 20–40 % и более.
- использование виртуализации, контейнеризации и динамического управления питанием (DPM, CPU throttling, core parking) с добавочной экономией 10–15 %.
- внедрение DCIM и AI/ML для прогнозирования нагрузки и настройки энергополитик, что дает еще 10–20% экономии.
Ключевая метрика для ЦОД — PUE (Power Usage Effectiveness), отношение общей потребляемой мощности к мощности ИТ-оборудования. Uptime Institute в ежегодном обзоре за 2024 год фиксирует средний PUE на уровне 1,58 и считает диапазон 1,2–1,5 хорошим результатом для современных объектов.

Оптимизация и снижение энергопотребления сервера и ИТ-систем: практические шаги
Оптимизация энергопотребления серверов и ИТ-систем начинается с измерений и приоритизации: сначала фиксируется энергопотребление сервера и основных компонентов, затем вводится набор технических мер, который дает быстрый и прогнозируемый эффект. Важно сразу связать меры по снижению энергопотребления с надежностью, доступностью и рисками для бизнес-сервисов.
В отраслевых исследованиях выделяется типичный порядок действий. Сначала проводится аудит и инвентаризация: оценивается энергопотребление систем, уровень загрузки CPU, RAM, дисков и сети, фиксируется исходный уровень расходов. Затем настраиваются энергопрофили, отключается лишнее оборудование и корректируются режимы работы систем охлаждения. Далее нагрузки консолидируются через виртуализацию и контейнеризацию, что снижает общее энергопотребление серверов на 30–40% за счет сокращения числа физических серверов и доли энергопотребления систем охлаждения. Завершающий шаг — постоянный мониторинг и автоматизация, которые устраняют «паразитное» энергопотребление и удерживают эффект от оптимизации энергопотребления в долгую.
Краткий чек-лист: как быстро снизить энергопотребление на 20–40%
- Включить энергосберегающие профили в BIOS/UEFI и ОС, активировать встроенные режимы управления питанием процессора и памяти для серверов и СХД.
- Отключить «пустые» физические серверы и тестовые стенды, перенести их нагрузки на существующие хосты через виртуализацию и контейнерные кластеры.
- Оптимизировать температурный режим и воздушные потоки, организовать холодные и горячие коридоры, исключить рециркуляцию горячего воздуха в зоны забора.
- Заменить HDD на SSD там, где важна производительность, и сгруппировать старые HDD в отдельные полки с оборудованием, выделив для них отдельный профиль охлаждения.
- Ограничить энергопотребление через power capping, отключить неиспользуемые порты, контроллеры и карты расширения, особенно в резервных и DR-средах.
- Настроить мониторинг энергопотребления на уровне стоек и розеток через «умные» PDU и BMC/IPMI, фиксируя энергопотребление систем в разрезе стоек и приложений.
- Ввести регламент регулярного пересмотра конфигураций и нагрузки раз в квартал, анализировать высокое энергопотребление и обновлять базовую линию.
Энергопотребление ИТ-инфраструктуры: как учитывать серверы, системы и сопутствующее оборудование
Учет энергопотребления ИТ-инфраструктуры ведется на трех уровнях: отдельный сервер, система или бизнес-сервис и вся ИТ-инфраструктура с инженерными системами. Такой подход позволяет связать энергопотребление систем с их ценностью для бизнеса и оценить, какие меры приносят наибольший эффект.
Энергопотребление на уровне отдельного сервера
Энергопотребление сервера оценивается по паспортной мощности и по реальным показаниям. Паспортная мощность показывает верхнюю границу при максимальной нагрузке, но реальное потребление зависит от текущей утилизации CPU, RAM и дисков. Реальные значения снимаются через BMC/IPMI, «умные» PDU или программные датчики гипервизора и ОС.
Для перевода мощности в стоимость применяется расчет по кВт·ч и тарифу. Например, сервер с фактическим потреблением 480 Вт при 730 часах работы в месяц и тарифе 5 руб./кВт·ч потребляет около 2100 руб. в месяц. При расчете добавляется коэффициент, учитывающий пики нагрузки и влияние PUE, если требуется оценить вклад в общее энергопотребление ЦОД.
Энергопотребление на уровне систем и сервисов
Энергопотребление систем и бизнес-сервисов рассчитывается через суммирование мощности серверов в кластере или стеке приложений и распределение этой мощности по сервисам. Для виртуализованных сред используются удельные показатели: W на виртуальную машину, контейнер или транзакцию. Такой подход позволяет сравнить энергопотребление систем по принципу «энергия на единицу полезной работы» и выбирать более энергоэффективные архитектуры.
Исследования Uptime Institute подчеркивают важность показателя W на транзакцию или запрос, поскольку именно он показывает энергоэффективность бизнес-функции, а не только железа.
Энергопотребление всей IT-инфраструктуры с сопутствующим оборудованием
Энергопотребление всей ИТ-инфраструктуры включает сервера, СХД, сетевое оборудование, системы безопасности и инженерные системы: охлаждение, ИБП, трансформаторы, освещение. Ключевой показатель в этом контексте — PUE. При PUE 1,6 общее энергопотребление превышает энергопотребление ИТ-оборудования на 60%. Поэтому учет на этом уровне строится через измерение общей мощности на вводе и мощности, потребляемой ИТ-нагрузкой.
Uptime Institute и ENERGY STAR публикуют методики измерения и рекомендации по периодичности учета и набору метрик для ЦОД и серверных. Эти подходы помогают выстроить учет энергопотребления ИТ-инфраструктуры с оборудованием и инженерными системами в единую модель.
| Уровень | Что учитывается | Как измеряется | Частота учета | Типовые метрики |
|---|---|---|---|---|
| Отдельный сервер | Мощность, потребляемая сервером, загрузка CPU/RAM/диски | Датчики BMC/IPMI, «умные» PDU, счетчики в стойке | Непрерывно или ежечасно | W/сервер, W/ядро, температура, утилизация CPU |
| Система или кластер | Суммарная мощность группы серверов и СХД | Агрегация данных мониторинга по тегам или кластерам | Ежечасно или ежедневно | W/ВМ, W/контейнер, W/транзакцию, W на бизнес-сервис |
| Вся IT-инфраструктура | Общая мощность ИТ-оборудования и инженерных систем | Счетчики на вводе, подсчет мощности по группам потребителей | Ежедневно или еженедельно | PUE, DCiE, kW/стойка, доля ИТ-нагрузки в общем потреблении |
Uptime Institute и ENERGY STAR рекомендуют фиксировать не только PUE, но и удельные показатели энергопотребления на стойку и сервер, что облегчает планирование мощности и модернизацию.
Метрики и показатели энергоэффективности серверов и ЦОД
Основные метрики: PUE, DCiE и удельное энергопотребление
Главные метрики энергоэффективности ЦОД — PUE и DCiE. PUE (Power Usage Effectiveness) показывает отношение полного энергопотребления объекта к энергопотреблению ИТ-оборудования. Чем ближе показатель к единице, тем эффективнее инфраструктура. DCiE (Data Center Infrastructure Efficiency) является обратной метрикой, выраженной в процентах.
The Green Grid в документе «PUE: A Comprehensive Examination of the Metric» описывает методологию расчета PUE на разных уровнях детализации и рекомендует использовать эту метрику для сравнения ЦОД в сопоставимых климатических условиях. Uptime Institute в обзорах отмечает, что PUE ниже 1,3 соответствует высокому уровню энергоэффективности для современных площадок.
Дополнительно используются удельные показатели: kW на стойку, W на сервер, W на ядро. Они помогают спланировать электропитание и охлаждение при росте плотности оборудования и оценивать, какие физические серверы дают лучший баланс «производительность на ватт».
Потребление на единицу полезной нагрузки
Показатели вида W на транзакцию, запрос или виртуальную машину показывают, сколько энергии требуется на реальную бизнес-операцию. Uptime Institute и отраслевые обзоры подчеркивают, что такие метрики особенно полезны при сравнении архитектур и приложений, а не только оборудования.
Например, при миграции приложения на новую платформу сравниваются две конфигурации: одна выполняет 1000 транзакций в секунду при 5 кВт, другая при 3 кВт. Показатель W/транзакцию у второй платформы ниже, следовательно, она энергоэффективнее и даёт меньшее общее энергопотребление на ту же полезную нагрузку.
Как выбрать набор метрик под инфраструктуру
Небольшим серверным обычно достаточно базового набора: PUE, kW на стойку и W на сервер. Для корпоративных ЦОД и площадок colocation список дополняется pPUE (partial PUE) для отдельных зон, а также метриками водопотребления (WUE) и углеродного следа (CUE) в контексте ESG.
На старте оптимизации достаточно регулярно измерять PUE и потребление по стойкам. В дальнейшем к набору показателей добавляются удельные метрики на транзакцию, бизнес-сервис и виртуальную машину, что позволяет связывать энергопотребление систем с бизнес-ценностью и точнее обосновывать инвестиции в снижение энергопотребления.
| Метрика | Что измеряет | Как считать | Где применять |
|---|---|---|---|
| PUE | Энергоэффективность датацентра | Общая мощность ЦОД / Мощность ИТ-оборудования | Сравнение ЦОД, целевые показатели для модернизации |
| DCiE | Эффективность инфраструктуры ЦОД (обратная PUE) | (Мощность ИТ-оборудования / Общая мощность ЦОД) × 100% | Оценка доли энергии, идущей на ИТ-нагрузку |
| kW/стойка | Энергопотребление стойки | Общая мощность всех стоек / количество стоек | Планирование мощности и охлаждения |
| W/сервер | Энергопотребление отдельного сервера | Измеренная мощность сервера | Сравнение энергоэффективности моделей серверов |
| W/ядро | Энергопотребление на одно ядро CPU | Мощность сервера / количество активных ядер | Анализ энергоэффективности CPU-архитектур |
| W/транзакцию | Энергоэффективность вычислений на уровне приложений | Общая мощность кластера / число транзакций за интервал | Сравнение архитектур приложений и бизнес-сервисов |
Спецификация PUE поддерживается консорциумом The Green Grid, а рекомендации по температурным режимам и классам среды для серверов и ЦОД публикует ASHRAE в Thermal Guidelines. Эти документы служат базой для отраслевых стандартов и целевых показателей энергоэффективности.
Анализ, аудит и мониторинг энергопотребления серверов и систем
Первичный аудит инфраструктуры и инвентаризация
Аудит энергопотребления начинается с инвентаризации оборудования: серверов, СХД, сетевых устройств и стоек. Фиксируются модели, год выпуска, конфигурации CPU, память, диски, наличие функций энергосбережения и поддержки IPMI. Параллельно строится карта соответствия оборудования бизнес-сервисам и уровням SLA.
Такая карта показывает, какие сервера поддерживают критичные сервисы, а какие обслуживают тестовые и вспомогательные нагрузки. Это важно для приоритизации консолидации и модернизации, чтобы снижение энергопотребления не увеличило риски отказов и не ухудшило показатели SLA.
Инструменты мониторинга мощности и нагрузки
Для мониторинга мощности и нагрузки используются несколько классов инструментов:
- BMC/IPMI и фирменные интерфейсы вендоров (Dell iDRAC, HPE iLO) для снятия показаний энергопотребления сервера и температуры
- средства операционной системы (PowerTOP, perf в Linux, Performance Monitor в Windows Server) и гипервизоров (esxtop, vCenter, Hyper-V Manager)
- «умные» PDU с учетом по розеткам и стойкам
- DCIM-системы (Schneider EcoStruxure, Nlyte и отечественные аналоги), собирающие данные с разных источников
Apollo Technical и 174PowerGlobal подчеркивают роль «умных» PDU, которые дают видимость энергопотребления на уровне каждой розетки и помогают выявлять энергоемкие устройства, которые незаметны в агрегированных графиках.
Анализ профиля нагрузки и выявление паразитного потребления
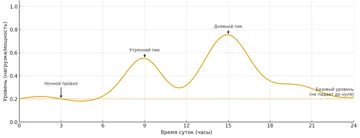
Профиль нагрузки по времени суток и дням недели показывает пики и провалы, периоды простоя и резерв по мощности. В типичном офисном сценарии серверы большую часть ночи и выходных работают с низкой утилизацией, но при этом продолжают потреблять значительную долю своей максимальной мощности. При PUE выше 1,5 это приводит к росту энергопотребления систем охлаждения и электропитания без пользы для бизнес-сервисов.
Анализ профиля позволяет выявить сервера, которые в простое потребляют близко к уровню под нагрузкой, а также системы бэкапа и аналитики, которые создают кратковременные пики и требуют специального планирования. На основе этих данных корректируются расписания задач, графики включения серверов и режимы работы систем охлаждения.
Базовая линия энергопотребления (baseline)
Baseline энергопотребления — это зафиксированный набор значений мощности для текущей инфраструктуры в типичный период. Microsoft и Uptime Institute рекомендуют использовать недельный или месячный период, который включает рабочие и выходные дни, а также типичные бизнес-циклы.
Baseline включает:
- среднюю и пиковую мощность на уровне сервера, стойки и всего ЦОД
- профиль нагрузки по часам суток
- текущий PUE и kW/стойка
По сравнению с baseline оценивается эффект любых мер по оптимизации энергопотребления. Без такой базовой линии сложно отличить реальное снижение энергопотребления от сезонных колебаний нагрузки.
Причины высокого общего энергопотребления серверов и ИТ-систем
Высокое общее энергопотребление серверов и ИТ-систем формируется из сочетания старого оборудования, низкой утилизации и неэффективного охлаждения. Даже при низкой нагрузке энергопотребление сервера редко опускается ниже 40% от максимума, а при устаревших блоках питания потери усиливаются. При этом каждый лишний ватт на уровне сервера увеличивает энергопотребление систем охлаждения и электропитания.
Основные причины высокого энергопотребления:
- старые серверы и блоки питания с низким КПД
- низкая утилизация CPU и памяти при круглосуточном режиме работы
- избыточные конфигурации с невостребованными CPU, RAM и дисками
- неэффективные системы охлаждения и отсутствие разделения холодных и горячих потоков
- отсутствие автоматического управления нагрузкой и питанием, «забытые» сервера и стенды
Ключевые риски:
- перегрев оборудования и ускоренное старение компонентов
- снижение надежности, рост числа сбоев и нарушений SLA
- рост затрат на инфраструктуру и потребность в дополнительных мощностях
- ухудшение показателей ESG и репутационные потери для компаний, ориентированных на устойчивое развитие
Аппаратные методы оптимизации энергопотребления
Выбор и модернизация энергоэффективного оборудования
Аппаратные методы оптимизации энергопотребления начинаются с выбора энергоэффективных компонентов. Современные серверные платформы с процессорами Intel Xeon и AMD EPYC 5–7 нм обеспечивают существенное снижение энергопотребления при той же или более высокой производительности. Исследования показывают, что такие серверы потребляют на 30–40% меньше энергии по сравнению с поколениями пятилетней давности.
Блоки питания с сертификацией 80 PLUS Platinum или Titanium имеют КПД 94–96% и выше, что сокращает потери при преобразовании. Переход на SSD и NVMe-накопители снижает энергопотребление дисковой подсистемы на 50–70% и одновременно уменьшает тепловыделение, что снижает нагрузку на системы охлаждения серверов.
Оптимизация конфигурации серверов
Оптимальная конфигурация сервера учитывает реальную нагрузку. Избыточное количество CPU и модулей памяти без необходимости увеличивает энергопотребление и затраты на охлаждение. В проектах энергоаудита часто выявляются сервера с минимальной утилизацией CPU и RAM, но полной конфигурацией по числу ядер и объемам памяти.
Правильная стратегия — подбирать количество ядер, частоту CPU, объем памяти и типы дисков под характер задач (CPU-интенсивные, память-интенсивные, I/O-интенсивные), а не по принципу «максимальной» конфигурации. Для систем резервного копирования или архивных СХД достаточно энергоэффективных серверов с оборудованием средней мощности, а для ИИ-нагрузок оправданы мощные конфигурации с оптимизированной системой охлаждения.
Управление питанием компонентов
Управление питанием компонентов включает настройку P-states и C-states, динамическое снижение частоты CPU в простое, ограничение мощности через power capping и управление питанием периферии. ENERGY STAR в рекомендациях по управлению питанием серверов отмечает, что комбинация CPU throttling и core parking дает 10–15% экономии без заметного влияния на производительность при правильно подобранных профилях.
Отдельное направление — использование технологий Intel Speed Select и аналогичных функций AMD для настройки приоритетов ядер и профилей мощности по ролям серверов. Такие механизмы позволяют выровнять энергопотребление систем по кластерам и удерживать пиковую мощность в пределах доступной инфраструктуры.
Отключение и консервация лишнего оборудования
Отключение лишних серверов и консолидация в более плотные кластеры — один из самых заметных источников экономии. Исследования по виртуализации показывают, что средний сервер до консолидации загружен на 10–20%. После миграции на небольшой пул мощных хостов и вывода части оборудования из эксплуатации суммарное энергопотребление снижается на 30–40%.
Консервация включает физическое отключение оборудования, демонтаж устаревших серверов и перекомпоновку стоек для выравнивания тепловых нагрузок. Это снижает энергопотребление серверов и позволяет эффективнее использовать существующие системы охлаждения и электропитания.
Энергопотребление серверов Dell и систем HPE: особенности оборудования
Энергопотребление сервера Dell и систем HPE управляется через специализированные инструменты, встроенные в оборудование. Эти платформы предоставляют режимы энергосбережения, мониторинг мощности и функции ограничения потребления на уровне отдельных серверов и групп.
Серверы Dell: функции для снижения энергопотребления
Сервер Dell платформы PowerEdge комплектуется контроллером iDRAC, который поддерживает настройку профилей питания и мониторинг энергопотребления в реальном времени. Профили вроде «Performance per Watt» и «Power Savings» регулируют частоту CPU, работу вентиляторов и напряжение на компонентах. В результате энергопотребление сервера снижается на 12–18% без ощутимой потери производительности при типовых нагрузках.
Средства Dell OpenManage Power Center позволяют агрегировать данные по нескольким серверам Dell, задавать лимиты мощности для стоек и сценарии отключения или снижения мощности при пиковых нагрузках. Планирование включения и выключения ресурсов по расписанию снижает энергопотребление сервера в периоды минимальной нагрузки и помогает удерживать общее энергопотребление ЦОД в рамках договорных лимитов.
Системы HPE: инструменты контроля энергопотребления
Системы HPE используют контроллер iLO и платформу HPE OneView для мониторинга и управления энергопотреблением систем. iLO предоставляет подробные отчеты по мощности и температуре, а функция power capping ограничивает максимальное энергопотребление сервера, что полезно для удержания нагрузки в пределах возможностей электропитания и охлаждения.
HPE OneView интегрирует данные с нескольких iLO и других источников, формируя общую картину энергопотребления систем hpe и других компонентов кластера. На базе этих данных задаются лимиты мощности для групп серверов и реализуются сценарии динамического снижения мощности некритичных виртуальных машин в периоды пиковых тарифов или ограничений по вводу мощности.
| Вендор | Инструмент | Функции | Уровень управления |
|---|---|---|---|
| Dell | iDRAC, OpenManage Power Center | Профили питания, мониторинг мощности, power capping, расписания включения/выключения | Отдельный сервер и группы серверов |
| HPE | iLO, HPE OneView | Детальные отчеты по мощности, power caps, централизованное управление группами | Кластер, группы серверов и стоек |
Официальные руководства по управлению энергопотреблением и настройке power profiles публикуются на сайтах поддержки Dell и HPE и обновляются по мере выхода новых поколений оборудования. Для глубокой настройки используются соответствующие разделы документации по iDRAC, iLO, OpenManage и OneView.
Программные и архитектурные методы снижения энергопотребления
Энергополитики в операционных системах и гипервизорах
Программные методы снижения энергопотребления опираются на энергополитики в ОС и гипервизорах. В Linux энергосбережение реализуется через CPU governors (powersave, balanced, performance и другие), которые управляют частотой процессора в зависимости от нагрузки. В Windows Server используются преднастроенные power profiles, объединяющие набор параметров в удобные режимы.
ENERGY STAR и Microsoft отмечают, что правильно настроенные профили питания и использование встроенных функций управления энергопотреблением дают 5–15 % экономии энергии без заметного влияния на производительность в большинстве сценариев. В гипервизорах VMware, Hyper-V и KVM настройки DPM и аналогичных механизмов позволяют автоматически переводить хосты в пониженное энергопотребление при снижении нагрузки.
Оптимизация ПО, сервисов и фоновых процессов
Снижение энергопотребления систем достигается за счет удаления неиспользуемых сервисов, оптимизации фоновых задач и пересмотра расписаний. Часто в инфраструктуре присутствуют программы мониторинга, агентов и вспомогательных служб, которые создают постоянную нагрузку на CPU и диск без реальной пользы.
Оптимизация включает:
- отключение ненужных служб и агентов
- настройку планировщиков задач и cron на выполнение ресурсоемких операций в периоды низкой нагрузки
- снижение частоты опросов, обновлений и логирования до разумного уровня
Ynvolve и другие поставщики решений по оптимизации ЦОД отмечают, что упорядочивание фоновой активности и отказ от избыточных сервисов снижает энергопотребление на 5–10 % за счет уменьшения «шума» на CPU и дисках.
Работа с СУБД и middleware
Базы данных и middleware создают значительную нагрузку на CPU и диски через фоновые операции: индексацию, сбор статистики, дефрагментацию, резервное копирование. Перенос таких операций на ночное время, снижение частоты ненужных задач и оптимизация политик логирования снижают энергопотребление систем без ущерба для надежности.
Особое внимание уделяется политике бэкапа. Неконтролируемый рост объема резервных копий и частоты задач приводит к нагрузкам на СХД и сети, которые увеличивают энергопотребление без прямой бизнес-выгоды. Правильное распределение этих операций по окнам низкой нагрузки уменьшает пики мощности и снижает требования к системам охлаждения.
Контейнеризация и легковесные среды
Контейнеризация через Docker и Kubernetes снижает overhead по сравнению с традиционной виртуализацией. Контейнеры используют общее ядро операционной системы, что уменьшает количество дублирующих процессов и снижает нагрузку на память и CPU.
Отраслевые исследования фиксируют снижение накладных расходов на 10–20 % при миграции с тяжелых виртуальных машин на контейнеры в сценариях микросервисной архитектуры. Управление ресурсами через cgroups и лимиты в Kubernetes помогает удерживать CPU и память в заданных пределах, что облегчает планирование энергопотребления и позволяет точнее управлять энергопотреблением систем на уровне отдельных сервисов и пространств имен.

Охлаждение серверов: системы охлаждения и доля энергопотребления на охлаждение
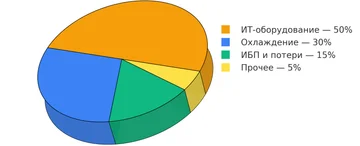
Охлаждение серверов занимает значительную долю в энергобалансе датацентра. Для типичного ЦОД эта доля находится в диапазоне 30–40% от общего энергопотребления, хотя в неэффективных системах охлаждение потребляет до половины энергии. Поэтому оптимизация систем охлаждения дает крупный эффект и напрямую влияет на общее энергопотребление ИТ-инфраструктуры.
Типы систем охлаждения и их особенности
Системы охлаждения делятся на воздушные и жидкостные. Воздушные схемы включают классические CRAC/CRAH-блоки, межрядные кондиционеры и организацию холодных и горячих коридоров. При грамотной организации коридоров и управлении скоростью вентиляторов доля энергопотребления на охлаждение снижается на 10–20%.
Жидкостное охлаждение и иммерсионные системы отводят тепло напрямую от CPU и GPU, что позволяет повышать температуру теплоносителя и использовать free cooling большую часть года. Исследования показывают, что иммерсионное охлаждение снижает энергопотребление на охлаждение до 30–40% по сравнению с традиционными воздушными схемами.
Для высокоплотных стоек с мощными серверами часто применяются гибридные системы охлаждения: жидкостное охлаждение для горячих компонентов и воздушное для остального оборудования. Это помогает выровнять энергопотребление систем охлаждения и удерживать PUE в целевом диапазоне.
Доля энергопотребления на охлаждение в датацентре
При PUE 1,5 на каждый киловатт ИТ-нагрузки приходится 0,5 кВт энергопотребления инженерных систем, основную часть которых составляют системы охлаждения. Поднятие температуры воздуха в зале на 1°C снижает энергопотребление систем охлаждения на 2–4%, если соблюдены рекомендации ASHRAE по температурным диапазонам.
ASHRAE в Thermal Guidelines рекомендует для большинства серверов диапазон температур 18–27°C и описывает классы оборудования с разными диапазонами влажности и температуры. Соблюдение этих рекомендаций позволяет увеличивать уставку температуры без ущерба для надежности и уменьшать энергопотребление на охлаждение даже для ИТ-инфраструктуры с высокой плотностью.
Автоматизация, DCIM и AI/ML для управления энергопотреблением
Системы DCIM и платформы анализа энергопотребления
DCIM (Data Center Infrastructure Management) объединяет данные об ИТ-оборудовании, электропитании и охлаждении в единую систему. Такие платформы обеспечивают инвентаризацию активов, мониторинг параметров в реальном времени, построение тепловых карт и графиков PUE и помогают планировать мощности.
DCIM-системы, описанные в отраслевых обзорах, позволяют выявлять недоиспользуемое пространство в стойках, резервы по мощности и охлаждению и высвобождать до 10% емкости ЦОД без строительства новых площадей. RackSolutions отмечает, что использование DCIM и автоматизированного анализа энергопотребления уменьшает суммарные энергозатраты на 10–20%.
Использование ML/AI для прогнозирования нагрузки и энергосбережения
ML и AI все активнее применяются для прогнозирования нагрузки и управления энергопотреблением. Алгоритмы анализируют исторические данные по мощности, температуре, утилизации CPU и внешним факторам, чтобы предсказывать пики и провалы. На основе прогноза системы заблаговременно включают или выключают часть оборудования, изменяют температурные уставки и корректируют профили питания.
Исследования показывают, что применение ML/AI совместно с DCIM дает дополнительные 10–20% экономии энергии за счет более точного управления ресурсами и уменьшения эксплуатационного резерва. Это особенно заметно в ЦОД с высокой долей ИИ-нагрузок и мощных серверов, где ошибки в оценке пиков быстро приводят к дефициту мощности и росту затрат на охлаждение.
Функции энергосбережения в экосистемах виртуализации и облаках
Гипервизоры и облачные платформы включают собственные функции энергосбережения. VMware реализует DRS и DPM для оптимизации распределения нагрузки и отключения хостов при простоях. Публичные облака используют автоматическое масштабирование, которое подстраивает количество виртуальных ресурсов под текущую нагрузку, уменьшая потребление при спаде активности.
Практический опыт системных интеграторов уровня Kvantech показывает, что внедрение DCIM в сочетании с модернизацией оборудования и оптимизацией охлаждения упрощает управление ЦОД и повышает прозрачность затрат на энергопотребление, что облегчает обоснование инвестиций для финансовых директоров и владельцев бизнеса.
Комментарии (0)
Новый комментарий
Новый комментарий отправлен на модерацию