


Что такое программно определяемое хранилище (SDS) и определяемые системы хранения данных
Программно определяемое хранилище, или SDS хранилище, это система, где все функции управления хранением реализует программный слой, а серверы и диски остаются универсальными ресурсами. Иначе говоря, программно определяемое хранилище управляет массивом разнородных дисков как единым пулом, не опираясь на специальные аппаратные контроллеры и проприетарное шасси.
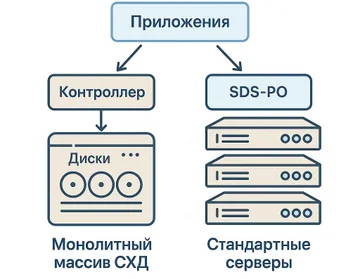
В классических системах хранения данных логика работы жестко зашита в контроллеры массива. Производитель поставляет монолитный блок: шасси, контроллеры, диски, прошивки. Программно определяемое хранилище отделяет логику хранения от железа. SDS устанавливается поверх стандартных серверов, виртуализует ресурсы хранения, создает абстрактные тома, шары и объекты и раздает их приложениям через привычные протоколы.
Ключевая идея программно определяемого хранилища в том, что все ресурсы хранения, доступные в дата-центре, превращаются в общий пул. В этот пул входят локальные HDD, SSD и NVMe в серверах, иногда внешние массивы и облачные хранилища. В SDS этот пул становится основой архитектуры: программный слой включает политики, которые определяют, какие данные хранить на быстрых носителях, какие на емких, как часто реплицировать блоки и какие уровни отказоустойчивости обеспечивать.
Отличие SDS от традиционных аппаратных систем хранения хорошо видно по роли контроллера. В классическом массиве контроллер привязан к конкретной модели, масштабирование ограничено его возможностями и количеством портов. В программно определяемом хранилище контроллер заменен программным уровнем, который масштабируется горизонтально. По формулировке NetApp, SDS это программный слой, который виртуализует и управляет физическим хранилищем и отвязывает сервис хранения от оборудования, становясь фундаментом гибридной облачной архитектуры и программно определяемого дата-центра.
SDS используют в разных сценариях. Типичные задачи: хранение виртуальных машин и дисков гипервизоров, размещение баз данных и журналов транзакций, долгосрочное хранение резервных копий, объектное хранилище для аналитики и Big Data, VDI, кластеры Kubernetes. В каждом таком случае программно определяемое хранилище предоставляет блочные, файловые или объектные сервисы для хранения, а администратор управляет ими из единой консоли.
Важно различать термин «программно определяемые системы хранения данных» как обобщающий класс и конкретные SDS-платформы. Определяемые системы хранения данных описывают общий принцип: логика и сервисы хранения живут в программном обеспечении, а ресурсы данных предоставляют обычные серверы. Программно определяемое SDS как класс решений это практическая реализация этого принципа в виде конкретных продуктов вроде Ceph, VMware vSAN или Nutanix, а также отечественных платформ.
Практическое следствие: архитектура хранилища строится вокруг пулов ресурсов хранения. Локальные диски на серверах объединяются в логические пулы, поверх них создаются тома, файловые системы и бакеты. Политики размещения данных задают, где поддерживать реплики, как распределять нагрузку, какие уровни QoS применять для разных классов сервисов. В SDS это стандартный подход: ресурсы хранения абстрагируются, а сервисы хранилища настраиваются на уровне политик.
Быстрая схема принятия решения: когда вам действительно нужен SDS
SDS нужен не каждой инфраструктуре. Программно определяемое хранилище раскрывает потенциал, когда классические системы хранения уже упираются в ограничения: данные растут быстрее, чем планировалось, расширение массива обходится дорого, зависимость от одного вендора сдерживает развитие, а совокупная стоимость владения становится заметной строкой расходов.
Косвенные признаки того, что существующие системы хранения исчерпывают себя: сложные и длительные закупки аппаратных СХД, отсутствие прозрачного пути масштабирования, регулярные проблемы с производительностью в пиковые периоды, трудно прогнозируемые расходы на расширение и поддержку, зависимость от одного производителя при обновлениях и миграциях, отсутствие единого взгляда на ландшафт хранилищ.
SDS подходит, если:
- объем данных превышает десятки терабайт и стабильно растет;
- планируется гибридная или мультиоблачная архитектура, где удобно управлять хранилищем как единой системой;
- важно избежать жесткой привязки к одному производителю оборудования и закупать серверы и диски по экономическим и технологическим соображениям;
- инфраструктура включена в процессы DevOps и нужна автоматизация операций хранения через API;
- требуется быстрое масштабирование ресурсов хранения без крупных разовых инвестиций в новые массивы;
- бизнес готов инвестировать в экспертизу по распределенным системам, Linux и виртуализации.
Можно остаться на классических СХД, если:
- нагрузки предсказуемые, объемы данных растут умеренно и помещаются в один или два массива;
- требуются сертифицированные решения под жесткие отраслевые и регуляторные требования;
- доступность на уровне «пятью девятками» и ниже обеспечивается существующими массивами без сложных интеграций;
- нет плана перехода к гибридному или мультиоблачному сценарию, инфраструктура сконцентрирована в одном ЦОД;
- команда не готова к освоению SDS и распределенных систем хранения.
Разным ролям в ИТ-команде полезно фокусироваться на своих разделах. CIO и ИТ-директору критичны блоки о преимуществах, рисках, экономике и сценариях применения. Системному архитектору важны разделы про архитектуру SDS, выбор платформы, инфраструктуру и интеграцию. Администраторам и инженерам стоит в первую очередь читать практическое руководство по развертыванию SDS, инфраструктурные требования и типичные ошибки внедрения.
«Компания обычно приходит к SDS в тот момент, когда очередной апгрейд массива не решает проблему. Нагрузки растут, а закупки становятся все тяжелее. На этом этапе переход к программно определяемому хранению перестает быть экспериментом и превращается в стратегическое решение», — такой вывод регулярно встречается в выступлениях архитекторов крупных интеграторов и подтверждается практикой внедрений.
Архитектура SDS: что лежит в основе программно определяемого хранилища и какие ресурсы хранения используются
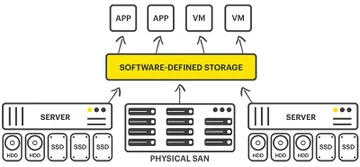
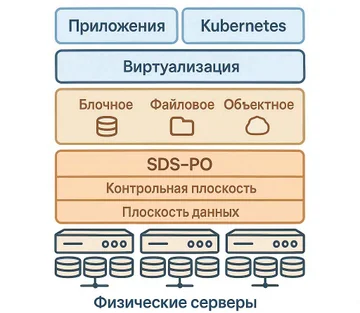
В основе SDS лежит программный слой, который управляет ресурсами стандартных серверов и сетевой инфраструктуры. Архитектура SDS разделяется на логический уровень, где описываются данные и политики, и физический уровень, где находятся серверы, диски, память и сетевые ресурсы. В SDS такой разрез архитектуры помогает отдельно проектировать сервисы хранения и «железную» часть.
Логическая архитектура SDS (плоскость данных и плоскость управления)
Логическая архитектура SDS обычно описывается через две плоскости. Плоскость данных отвечает за чтение и запись данных. Здесь находятся процессы, которые принимают блоки, файлы или объекты, раскладывают их по дискам, поддерживают репликацию и erasure coding, кэшируют запросы и балансируют нагрузку.
Плоскость управления управляет политиками хранения, распределением ресурсов и конфигурацией кластера. В этой плоскости работают контроллеры SDS, API, интерфейсы администрирования, службы оркестрации и автоматизации. Через них задаются пулы, уровни отказоустойчивости, классы хранения, квоты и QoS. Архитектура SDS в этом смысле следует общему принципу программно определяемых систем: управление и политики отделены от плоскости данных.
Отдельный блок логической архитектуры занимают метаданные, мониторинг и телеметрия. Метаданные описывают, где размещен каждый блок или объект, какие версии существуют, какое состояние у реплик и в каких пулах они находятся. Система мониторинга и телеметрии собирает метрики нагрузки, задержек, ошибок, хранит историю и поддерживает предиктивный анализ. В современных SDS сюда же добавляются AIOps-подходы, которые помогают автоматически выявлять аномалии и оптимизировать размещение данных. Эту модель детально разбирают Lightbits и Scale Computing в открытых технических материалах по SDS.
Физические ресурсы хранения в SDS: серверы, диски, память, сеть
Физический уровень SDS опирается на стандартные серверы хранения. Это могут быть стоечные серверы с большим количеством слотов под диски, иногда специализированные узлы высокой плотности. Внутри таких серверов размещаются HDD для холодных данных, SSD для горячих и кэш-слоев, NVMe для задач с критичными требованиями к задержкам. В SDS эти элементы рассматриваются как ресурсы хранилища, которые объединяются в единый пул.
Память в серверах используется не только для работы ОС и сервисов, но и как кэш данных и метаданных. Многие SDS-решения умеют использовать свободную оперативную память узлов для ускорения операций чтения и записи, что увеличивает производительность в разы по сравнению с дисковыми конфигурациями без кэширования.
Сетевые ресурсы составляют еще один базовый элемент архитектуры SDS. Узлы объединяются в кластер через сеть с высокой пропускной способностью. В типичных реализациях применяются 10, 25 или 40 Гбит/с, а для крупных инсталляций и NVMe-oF встречаются и более высокие скорости. В SDS эта сеть обслуживает клиентский трафик, репликацию, ребалансировку и операции восстановления, поэтому просчет сетевой части напрямую влияет на поведение всей системы хранения.
Физические ресурсы хранения объединяются в единый пул. SDS не различает, на каком конкретном диске или на каком сервере хранится объект. Важен пул, его класс и политика. Именно такой подход, по формулировке Scale Computing, обеспечивает линейный рост емкости и пропускной способности без редизайна системы. В основе SDS-подхода лежит именно это объединение серверов хранения, сетевых ресурсов и дисков в общий пул.
Ключевые компоненты: контроллер SDS, пулы и политики данных
Контроллер SDS, или управляющий слой, это программный компонент, который реализует функции, которые в классических СХД выполняли аппаратные контроллеры. Он создает и управляет пулами ресурсов, обеспечивает репликацию, erasure coding, снапшоты, дедупликацию, шифрование и QoS. В Ceph роль такого управляющего слоя выполняют мониторы, менеджеры и службы управления RADOS.
Пулы ресурсов представляют собой логические группы дискового пространства. Для разных задач создаются отдельные пулы: быстрый пул на NVMe под базы данных, емкий пул на HDD под бэкапы, сбалансированный пул на SSD под виртуальные машины. Каждому пулу соответствуют свои политики размещения и уровни отказоустойчивости, а в SDS-решениях это настраивается на уровне конфигурации, а не «железа».
Политики данных и QoS описывают, сколько копий данных хранить, какой профиль erasure coding применять, как ограничивать IOPS и пропускную способность для отдельных томов и клиентов, как планировать снапшоты и репликацию. Именно политики превращают абстрактный пул ресурсов в конкретную сервисную модель под бизнес-задачи и определяют поведение программно определяемого хранилища в пиковых режимах.
Тем, кто планирует архитектуру, полезно обращаться к техническим руководствам Ceph, VMware vSAN или Nutanix. В документации Ceph подробно разобраны роли OSD, MON, MDS, пулы, группы размещения и алгоритм CRUSH, который распределяет объекты по кластеру без центральной таблицы. Обзорная информация по SDS-архитектурам и их ролям в инфраструктуре собрана и в глоссарии WEKA по программно определяемым хранилищам.
Преимущества SDS: почему программно определяемое хранилище выгоднее классических систем хранения
Преимущества SDS по сравнению с классическими аппаратными СХД сводятся к экономике, гибкости, масштабируемости и автоматизации. DataCore в обзоре своих SDS-решений прямо указывает на снижение совокупной стоимости владения за счет отвязки программного обеспечения от дорогого проприетарного оборудования и эффективного использования стандартных серверов.
- Экономия и снижение затрат. Программно определяемое хранилище использует стандартные серверы и диски. Капитальные затраты сокращаются за счет отсутствия специализированных контроллеров, а расширение происходит постепенно добавлением узлов. Операционные расходы падают за счет автоматизации, дедупликации, сжатия и более эффективного использования ресурсов.
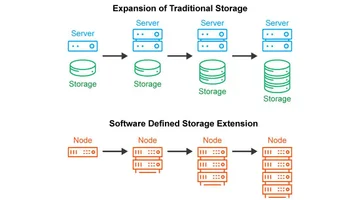
- Масштабируемое хранилище и гибкое масштабирование. SDS использует scale-out-подход. При росте нагрузки и данных достаточно добавить новые серверы хранения и включить их в пул. Вендоры, такие как Scale Computing, подчеркивают, что такая модель дает линейный рост емкости и пропускной способности без сложных миграций и замен массивов.
- Гибкость хранения и поддержка разных типов носителей и протоколов. SDS работает с HDD, SSD, NVMe, NVMe-oF и поддерживает блочные, файловые и объектные протоколы. Это дает возможность выбирать экономичные комбинации носителей под разные классы данных и подключать приложения привычными способами.
- Высокая отказоустойчивость. Репликация, erasure coding, самовосстановление и геораспределение узлов обеспечивают устойчивость к сбоям отдельных дисков, серверов и даже площадок. DataCore и другие вендоры показывают уровни сохранности, которые сравнимы или превосходят классические массивы, но без их аппаратных ограничений.
- Повышение производительности за счет интеллектуальных алгоритмов. SDS анализирует шаблоны доступа, выносит горячие данные на быстрые носители, использует кэш в памяти и оптимизирует параллельные операции. WEKA и NetApp отмечают, что такие механизмы дают кратный прирост производительности по сравнению с прямым доступом к дискам.
- Автоматизация и интеграция. Современные SDS играют важную роль в DevOps-процессах. Через API и интеграции с системами оркестрации возможна автоматизация выделения томов, снапшотов, политики резервного копирования и миграций. Red Hat в своих материалах по программно определяемому хранению связывает программируемость хранилища с ускорением бизнес-изменений и поддержкой CI/CD-процессов.
- Независимость от вендора. Отвязка софта от железа снижает риски vendor lock-in. Появляется возможность сочетать серверы и диски разных производителей и выбирать оборудование по совокупным характеристикам, а не по совместимости с конкретным массивом. Для долгосрочных проектов это одно из ключевых преимуществ SDS.
Ограничения и риски SDS: о чем важно помнить перед внедрением
Наряду с преимуществами программно определяемое хранилище несет и набор рисков. Внедрение SDS имеет смысл только при осознанном отношении к этим ограничениям.
Организационные риски связаны с требованиями к квалификации команды. SDS это распределенная система с собственными паттернами отказов, зависимостью от сети и сложной моделью хранения. Нужны компетенции в Linux, кластеризации, виртуализации, сетевых технологиях, а также понимание того, как планировать RPO и RTO в такой архитектуре. Red Hat и другие вендоры подчеркивают, что недостаток компетенций часто делает open source SDS дороже коммерческих решений по факту владения.
Технические риски касаются производительности, сети и дисковой подсистемы. SDS создает значительные объемы межузлового трафика через репликацию, ребалансировку и восстановление. Сеть с недостаточной пропускной способностью или высокой задержкой превращается в узкое место. Дисковая подсистема при неправильном подборе типов и количества носителей становится причиной латентности и нестабильного отклика. В SDS-кластер это особенно остро проявляется, потому что задержки в сети и на дисках влияют на все пулы.
Финансовые риски связаны с лицензированием и расчетом TCO. Модели лицензирования SDS различаются: оплата за терабайты, за узлы, за функциональные модули. При неполном учете расходов на обучение, поддержку, сеть, резервное копирование и миграции совокупная стоимость владения выходит выше ожидаемой. DataCore и NetApp в своих материалах по SDS акцентируют внимание на полном цикле расходов, включая поддержку и обновления, а не только на покупке ПО.
Отдельной строкой стоят вопросы безопасности и соответствия нормативным требованиям. В распределенных системах хранения каждая нода потенциальный вектор атаки. Нужно предусматривать шифрование, сегментацию сети, аудит операций и проверку соответствия отраслевым требованиям к защите данных. В SDS средах защита данных должна охватывать и плоскость управления, и плоскость данных.
Разумная стратегия снижения рисков это пилотный проект и поэтапное внедрение. Пилот в ограниченной среде позволяет проверить производительность, особенности интеграции, удобство администрирования и реалистичный профиль нагрузки. Далее конфигурация дорабатывается по результатам, и только после этого SDS выходит в продакшен.
| Риск | Проявление | Как снизить |
|---|---|---|
| Недостаток компетенций | Ошибочные настройки, падение производительности | Обучение, привлечение экспертов, документация |
| Узкая сеть | Высокие задержки, тайм-ауты, сбои ребалансировки | Планирование сети 10–25 Гбит/с, изоляция трафика |
| Слабая дисковая подсистема | Нехватка IOPS, нестабильный отклик | Подбор NVMe/SSD для горячих данных, мониторинг |
| Сложное лицензирование | Непредсказуемый TCO | Анализ моделей лицензий, учет всех затрат |
| Безопасность | Повышенный риск атак и утечек | Шифрование, сегментация, аудит |
| Отсутствие пилота | Непредсказуемое поведение в продакшене | PoC, нагрузочное тестирование |
Развертывание и использование SDS-решения для серверов и СХД
Развертывание SDS-решения для серверов и СХД логично проводить по понятному плану. Вендоры и интеграторы, включая Lightbits и NetApp, сходятся в том, что подготовка инфраструктуры и пилотный этап критичны для успеха развертывания SDS в продакшене.

Шаг 1. Оценка текущей инфраструктуры и целей проекта
Сначала проводится инвентаризация серверов и СХД, сети и нагрузок. Нужны данные по CPU, памяти, текущей дисковой подсистеме, показателям IOPS и задержкам, пропускной способности сети. Параллельно формулируются требования по SLA, RPO и RTO для сервисов, которые будут использовать SDS инфраструктуру.
На этом шаге определяется, где именно используется SDS решение для серверов. Это может быть кластер виртуализации, хранилище резервных копий, платформа аналитики или VDI. Одни задачи требуют минимальной задержки и высокой плотности IOPS, другие делают акцент на емкости и стоимости за терабайт. В SDS-среде эти требования напрямую влияют на выбор архитектуры и типов пулов.
Шаг 2. Выбор SDS-решения и архитектурного подхода
После оценки нагрузки и целей формируется короткий список SDS-платформ. В качестве критериев рассматриваются поддерживаемые гипервизоры, протоколы (iSCSI, NFS, SMB, S3), типы носителей, интеграция с оркестрацией (Kubernetes, Ansible, OpenStack), модели лицензирования и наличие поддержки.
Выбирается архитектурный подход. Для задач виртуализации и VDI применяют гиперконвергентную инфраструктуру, где SDS работает на тех же серверах, что и гипервизор. Для крупных систем хранения и аналитики используют выделенные кластеры хранения. Отдельно оцениваются open source и коммерческие решения, а также отечественные и зарубежные платформы, с учетом требований к импортозамещению и сертификациям.
Шаг 3. Подготовка серверов и СХД для развертывания SDS
Затем подготавливаются серверы. Требуются достаточные ресурсы CPU и памяти: для средних нагрузок это десятки ядер и сотни гигабайт памяти на кластер, для крупных систем значения выше. Серверы должны иметь планируемое количество слотов под локальные диски, поддержку SSD и NVMe, а также сетевые интерфейсы не ниже 10 Гбит/с с возможностью агрегации. Для серверов Dell, HPE (серверов HP Enterprise) и серверов Lenovo это обычно линейки PowerEdge, ProLiant и ThinkSystem с поддержкой NVMe.
Готовится сетевая инфраструктура под кластеры хранения. Обычно выделяются отдельные VLAN или даже физические фабрики сети под трафик SDS, репликацию и клиентские запросы. Переключатели настраиваются под низкую задержку, резервирование и QoS, чтобы в SDS-окружении сетевые ограничения не становились фактором деградации.
Шаг 4. Развертывание SDS: установка и базовая конфигурация
На этом шаге устанавливается SDS-ПО на подготовленные серверы. Узлы объединяются в кластер, назначаются роли. В Ceph, например, выделяются узлы под OSD, MON и MDS. В гиперконвергентных решениях эти роли совмещаются на одних и тех же серверах, и в SDS-кластер входит и вычислительная, и дисковая часть.
Создаются пулы хранения и настраиваются механизмы отказоустойчивости. Выбирается число реплик или профиль erasure coding, рассчитывается требуемый уровень избыточности с учетом SLA. Проводится первичное тестирование работоспособности кластера и мониторинга. Развертывание SDS на этой стадии определяет дальнейшее поведение кластера под нагрузкой.
Шаг 5. Настройка политик, интеграция с виртуализацией и ввод в эксплуатацию
Далее настраиваются политики качества сервиса, снапшотов и резервного копирования. Задаются ограничения IOPS и пропускной способности для разных классов томов, планируются расписания снапшотов и репликаций, настраиваются политики резервного копирования. Политики задаются для пулов и томов так, чтобы разграничить сервисы с разными требованиями.
Происходит интеграция с гипервизорами и системами контейнеризации. Подключаются плагины для VMware, Hyper-V, Kubernetes. Выполняется миграция данных и виртуальных машин на SDS инфраструктуру, проводится нагрузочное тестирование. Только после этого SDS решение для серверов и СХД вводится в промышленную эксплуатацию.
Типовые сценарии использования SDS-решения
Виртуализация хранения для серверов виртуализации один из основных сценариев. SDS предоставляет единый пул хранения для кластеров гипервизора, упрощает управление томами и снапшотами, улучшает отказоустойчивость.
SDS часто используется как репозиторий резервных копий. Возможности дедупликации, сжатия, многослойного хранения и объектных интерфейсов позволяют хранить большие объемы бэкапов экономично и надежно. В SDS это дополняется автоматизацией размещения данных по уровням.
Кластеры хранения для аналитических платформ и систем Big Data еще один типовой сценарий. SDS предоставляет масштабируемое блочное или объектное хранилище, где важно горизонтальное масштабирование и возможность быстро добавлять новые узлы по мере роста данных.
Практические инструкции по каждому шагу подробно разобраны в материалах NetApp и Scale Computing по SDS. Например, NetApp в своем обзоре SDS описывает этапы оценки, пилота и промышленного внедрения решения поверх существующей инфраструктуры.
Классы и типы SDS-решений
Блочное, файловое и объектное SDS-хранилище
Блочное SDS-хранилище предоставляет диски в виде логических блоков. Такие решения обслуживают базы данных, системы виртуализации и транзакционные приложения. Основные интерфейсы: iSCSI, Fibre Channel, NVMe-oF. Ceph RBD и многие коммерческие SDS относятся к этому классу.
Файловое SDS-хранилище организует доступ через протоколы NFS и SMB. Оно подходит для совместной работы, файловых серверов, корпоративных хранилищ документов и профилей пользователей. SDS-платформы вроде GlusterFS и отдельные режимы CephFS предназначены для таких задач.
Объектное SDS-хранилище хранит данные в виде объектов с метаданными и адресует их по ключам. Типичный интерфейс S3, иногда Swift. Именно объектные SDS-решения стали стандартом для озер данных, медиаконтента, архивов и резервных копий. NetApp и Nutanix подчеркивают, что объектное SDS сочетает низкую стоимость за терабайт с горизонтальной масштабируемостью.
Гиперконвергентная инфраструктура (HCI) как развитие идей SDS
Гиперконвергентная инфраструктура это частный случай SDS, где хранилище, вычисления и сеть объединены в единый программно управляемый комплекс. SDS в такой архитектуре обслуживает диски на тех же серверах, что и гипервизор, а масштабирование происходит добавлением новых узлов.
В 2025 году гиперконвергентные решения занимают значительную долю рынка систем виртуализации. Они упрощают эксплуатацию, потому что все ресурсы управляются из одного интерфейса. Nutanix и VMware vSAN позиционируют HCI как основу частных и гибридных облаков, где SDS слит с вычислительными ресурсами.
| Тип SDS | Интерфейсы | Тип данных | Типичные нагрузки |
|---|---|---|---|
| Блочное | iSCSI, FC, NVMe-oF | Блоки фиксированного размера | Базы данных, виртуальные машины |
| Файловое | NFS, SMB | Файлы и каталоги | Файловые серверы, совместная работа |
| Объектное | S3, Swift | Объекты с метаданными | Архивы, мультимедиа, Big Data |
| HCI-SDS | Смешанные, интеграция с гипервизором | Блоки и файлы | Виртуализация, VDI, частные облака |
Как выбрать SDS-платформу и инфраструктуру под свои задачи
Шаг 1. Формулировка требований к хранилищу
Выбор SDS-платформы начинается с формализации требований. Нужны оценки текущих и прогнозных нагрузок, профилей ввода-вывода, объемов данных и скорости их роста. Параллельно задается целевой SLA, значения RPO и RTO, допустимое время простоя и потери данных.
Кроме технических параметров важно зафиксировать бюджет и технологические ограничения. В российской практике часто добавляется требование к импортозамещению и сертификации. Эти рамки сразу сужают список допустимых решений и влияют на то, какие SDS-решения для серверов и СХД окажутся в коротком списке.
Шаг 2. Критерии сравнения SDS-решений
Ключевые критерии:
- архитектура и отказоустойчивость, в том числе механизмы репликации и erasure coding;
- производительность и масштабируемость при росте числа узлов;
- удобство администрирования, качество мониторинга и автоматизации;
- интеграция с текущими гипервизорами, системами резервного копирования, Kubernetes;
- гибкость лицензирования и предсказуемость TCO.
Lightbits, DataCore и другие поставщики SDS в своих материалах обращают внимание на абстракцию от аппаратной платформы и прозрачность мониторинга и управления как на базовые свойства зрелого SDS-решения. Аналитические отчеты Gartner и IDC по SDS и HCI дополняют эти критерии независимыми сравнениями.
Шаг 3. Сравнительная матрица и пилотный проект
Для взвешенного выбора полезно строить сравнительную матрицу. В ней перечисляются кандидаты и параметры: масштабируемость, поддерживаемые протоколы, модели отказоустойчивости, типы носителей, лицензирование, интеграции, результаты независимых бенчмарков. Для СХД и SDS такую роль выполняют тесты Storage Performance Council, SPC-1 и SPC-2, результаты которых публикует организация SPC и вендоры, включая Broadcom.
После предварительного выбора хотя бы двух платформ рекомендуется проводить пилотный проект. Пилот включает нагрузочное тестирование с профилями, близкими к боевым, проверку отказоустойчивости, оценку удобства администрирования и интеграции. Gartner и IDC в отчетах по SDS подчеркивают роль PoC как критического этапа перед промышленным внедрением.
Часто задаваемые вопросы (FAQ)
Что делать с уже существующими СХД при переходе на SDS?
Существующие массивы интегрируют в общий ландшафт. Часть нагрузок переносится на SDS, а классические СХД продолжают работать для критичных или специализированных задач. Миграция данных выполняется поэтапно, с использованием инструментов копирования и репликации, чтобы избежать простоев.
Можно ли построить промышленную SDS-систему только на open source?
Да, многие компании используют open source SDS, такие как Ceph или GlusterFS, в крупных инсталляциях. Однако эксплуатация таких систем требует высокой квалификации, поэтому практический TCO включает затраты на команду и поддержку.
Как посчитать окупаемость проекта SDS?
Окупаемость оценивается через сравнение текущего TCO классических СХД и прогнозного TCO SDS на горизонте нескольких лет. Учитываются затраты на оборудование, лицензии, поддержку, персонал, сети и миграции. Дополнительно сравниваются косвенные эффекты, такие как гибкость и скорость вывода новых сервисов.
Какой минимальный масштаб инфраструктуры оправдывает внедрение SDS?
SDS имеет смысл при объемах данных от десятков терабайт и выше, если наблюдается устойчивый рост и есть задачи автоматизации и гибридных сценариев. При меньших объемах и стабильных нагрузках классические СХД остаются проще и дешевле.
Как организовать поэтапный переход, чтобы не рисковать бизнесом?
Переход распределяют на несколько этапов. Сначала пилот под некритичную нагрузку. Затем миграция второстепенных сервисов и резервных копий. После проверки надежности и производительности на этих сегментах возможно перенести на SDS более важные системы.
Как связать SDS и существующие СХД Dell, HPE, Lenovo и российские решения?
Связка реализуется через стандартные протоколы: iSCSI, NFS, SMB, S3. SDS может использовать тома на классических массивах как часть пула или, наоборот, экспортировать свои тома на серверы, которые ранее работали только с массивами. Важно проверить совместимость контроллеров, драйверов и сетевой инфраструктуры.
Подходит ли SDS для критичных транзакционных систем?
Для систем с экстремальными требованиями к задержкам и строго регламентированным поведением чаще используют классические all-flash-массивы или специализированные решения. SDS способен обслуживать такие нагрузки, но требует особо тщательного проектирования сети и дисковой подсистемы.
Как организовать резервное копирование в SDS-окружении?
Резервное копирование строится так же, как с классическими СХД, но с учетом распределенной природы SDS. Используются снапшоты, репликация на удаленные площадки и интеграция с системами бэкапа, которые понимают SDS-тома и объектные интерфейсы.
Можно ли использовать SDS в мультиоблачной архитектуре?
Да, SDS часто служит связующим звеном между локальными и облачными ресурсами. Через объектные интерфейсы и функционал репликации данные переносятся между площадками, а администратор управляет ими как единой системой.
Как контролировать безопасность в SDS?
Нужны шифрование данных на дисках и в полете, сегментация сети, строгая политика доступа, регулярный аудит и обновления. Важно контролировать каждую ноду, потому что все узлы кластера становятся частью критичной инфраструктуры.
Комментарии (0)
Новый комментарий
Новый комментарий отправлен на модерацию