

S3 — это способ хранить файлы в облаке, где каждый файл — это объект. У него есть имя (ключ), содержимое (данные) и ярлыки (метаданные). Простыми словами, это как ящик с файлами, только в интернете. Закинул туда фото, видео или бэкап — и можешь доставать откуда угодно.
Этот формат хранения придумали ребята из Amazon, и с тех пор весь рынок подтянулся: Яндекс, Selectel, VK Cloud — у всех уже есть S3-совместимое хранилище. Почему так? Потому что это удобно, гибко и не разваливается, когда твой проект внезапно выстреливает.
Я сам впервые столкнулся с S3, когда бэкапы на сервере начали отжирать половину диска. Перенёс на S3 — и не вспоминаю. Всё стабильно, доступно, не требует уборки вручную. А главное — можно подключить хоть через веб, хоть из командной строки, хоть из скрипта.

В этой статье расскажу, как устроено S3, как с ним работать, какие бывают варианты и на что обратить внимание, чтобы не напороться. Будет и для новичков, и для тех, кто уже «щупал» AWS или Yandex Cloud, но хочет разобраться глубже.
Краткий обзор: S3-хранилище простыми словами
Представь себе склад. У каждого ящика есть номер, описание и содержимое. Ты можешь взять ящик, положить в него файлы, повесить ярлык, а потом найти его по номеру. Вот это и есть объектное хранилище.
В отличие от привычной файловой системы, где важна структура папок, в S3 всё лежит в одном «бакете» — как в большой бочке. А поиск и доступ строится не по путям, а по ключам.
Что делает S3 удобным
- Не надо следить за деревом каталогов — всё по ключу.
- Нет ограничений на количество файлов — хоть миллион.
- Работает через интернет — можно подключиться из любой точки мира.
- Поддерживает автоматическое архивирование, шифрование и контроль доступа.
Проще говоря: если тебе нужно хранить много данных, не заморачиваться с серверами и обеспечить доступ к этим данным через API — S3 идеально подходит. Именно поэтому его любят разработчики, сисадмины и DevOps-инженеры.
Как работает объектное хранилище S3
Если ты когда-нибудь работал с файловыми системами на жестких дисках, то знаешь, как важно организовать данные. Но S3 работает по-другому. Здесь все устроено гораздо проще, и при этом более гибко.
Что такое объект в S3?
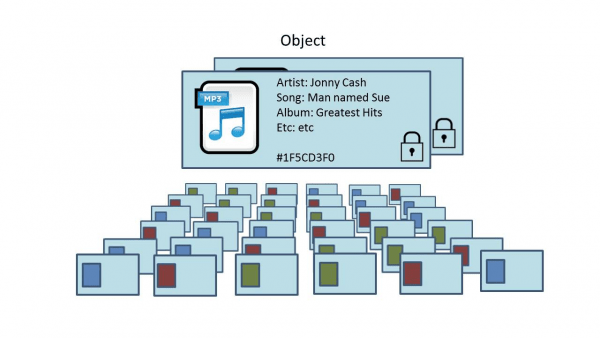
Объект в S3 — это не просто файл, а набор данных с метаданными. Представь, что ты загружаешь файл в хранилище, а S3 не просто сохраняет его на сервере, но и добавляет дополнительные данные о нем. Например, дату загрузки, тип файла, владельца и другие параметры. Эти метаданные позволяют быстрее искать, фильтровать и управлять данными.
Объект состоит из:
- Данных: сам файл (например, изображение или текстовый документ).
- Метаданных: дополнительная информация, например, размер файла, дата загрузки, права доступа и т.д.
- Ключа: уникальный идентификатор для каждого объекта, по которому можно его найти.
Как устроены бакеты и ключи в Amazon S3?
В отличие от привычных папок на диске, в S3 для хранения объектов используются бакеты. Это как контейнеры, в которых хранятся данные. У каждого бакета есть уникальное имя, и каждый объект внутри этого бакета имеет свой ключ — уникальное имя файла.
Ты можешь создавать сколько угодно бакетов, но у каждого бакета будет своё уникальное имя в пределах региона. То есть название бакета должно быть уникальным по всей системе S3.
Пример: если ты создаешь бакет с именем my-backups, то все объекты, которые туда загрузишь, будут иметь уникальные ключи. Например, объект backup1.zip или database_backup_2023.sql. Таким образом, каждый объект получает полный путь: s3://my-backups/backup1.zip.
Протокол доступа
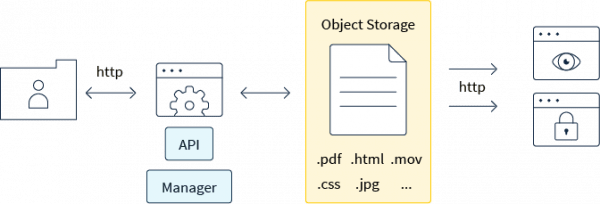
Доступ к данным в S3 можно получить через разные каналы: веб-интерфейс, командную строку и программные инструменты. Например, в AWS ты можешь использовать Management Console для работы через браузер, AWS CLI — для управления хранилищем из терминала, или API и SDK — для интеграции с другими сервисами. Способ подключения зависит от задачи. Лично я чаще всего использую AWS CLI — он удобен для автоматизации, особенно когда нужно делать бэкапы или переносить данные между сервисами.
Протокол S3: от идеи до стандарта
Протокол S3 был разработан Amazon и стал стандартом для облачного хранения данных. Это своего рода RESTful API, которое позволяет клиентам взаимодействовать с хранилищем через HTTP-запросы. S3 используется не только для хранения данных, но и для их загрузки, скачивания, удаления и изменения. Протокол позволяет работать с большими объемами данных, использовать гибкие методы управления доступом и интегрироваться с другими сервисами и приложениями через API.
Каждый запрос в S3 — это HTTP-запрос с определённым методом, таким как GET, PUT, DELETE. Всё работает как обычный веб-сервис, что даёт гибкость и позволяет легко интегрировать S3 с любыми приложениями или системами.
Что такое объект в S3 и как он устроен
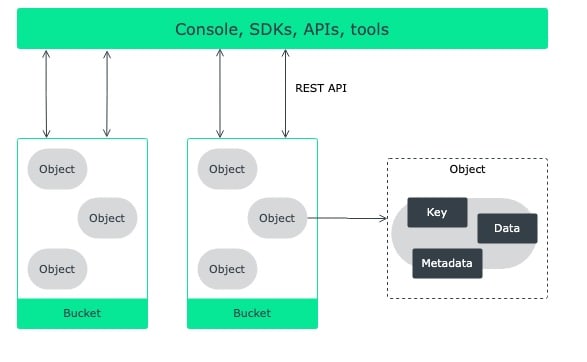
В S3 каждый файл называется объектом, и он хранится не как обычный файл на диске, а как самостоятельная единица с набором важных характеристик. Помимо самого файла, объект включает в себя метаданные (например, дата загрузки, тип файла) и уникальный идентификатор — ключ, по которому его можно найти. Это всё, что нужно для работы с объектами.
Объект в S3 — это самодостаточная сущность, которая может быть чем угодно: от небольшого текстового документа до огромного видеофайла. Главное, что нужно помнить, — это уникальность ключа. Ключ — это как адрес объекта, который позволяет всегда находить нужный файл в большом хранилище.
Что включает в себя объект в S3:
- Данные — это сам файл, который ты загружаешь. Он может быть любого типа — от картинок до баз данных.
- Метаданные — дополнительная информация о файле (например, размер, дата создания и т.д.).
- Ключ — уникальный идентификатор, который помогает найти объект в хранилище. Он может быть в виде простого имени или более сложной структуры.
При загрузке файла в S3, система автоматически назначает ему уникальный ключ, и тебе достаточно этого ключа, чтобы найти объект в будущем. Главное отличие от обычных файловых систем в том, что S3 не использует папки для хранения объектов. Всё организуется через бакеты и ключи, что значительно упрощает структуру.
Преимущества такого подхода:
- Нет необходимости следить за кучей папок — ищешь объект по его ключу.
- Легко управлять доступом и правами, т.к. для каждого объекта можно настроить свои правила.
Таким образом, объектное хранилище S3 помогает работать с данными проще, гибче и эффективнее, особенно когда нужно хранить или обрабатывать большие объемы информации.
Как начать работу с S3: пошаговая инструкция
Пугаться не надо — настроить S3 проще, чем кажется. Даже если ты никогда не работал с облаками, за 10–15 минут всё заведётся. Главное — не путаться в терминах и следовать инструкции. Вот она, без лишних слов.
Шаг 1. Зарегистрируйся в облачном сервисе
Если ты работаешь с Amazon S3 — зайди на официальный сайт компании. А если нужен российский аналог, обрати внимание на Selectel, Яндекс Облако или VK Cloud. У всех этих провайдеров есть бесплатные тарифы, с которых удобно начать. После регистрации ты получишь доступ к консоли управления — это и будет твой центр командования всеми ресурсами, включая хранилище.
Шаг 2. Создай бакет
Бакет — это как контейнер, в котором будут лежать твои файлы. Название должно быть уникальным в пределах региона, например: my-backup-2024.
Важно:
- Не пиши пробелы, кириллицу и спецсимволы.
- Лучше использовать что-то в стиле company-backups или project-name-logs.
При создании бакета можно сразу задать регион (например, eu-west-1) и включить версионирование, если нужно сохранять историю изменений.
Шаг 3. Настрой доступ
Выбираешь, кто может видеть твои данные:
- Только ты (приватный бакет)
- Ты и команда
- Все (если хочешь использовать как хостинг, например, для сайта)
В большинстве случаев лучше оставить бакет приватным. Публичный доступ — это как дверь без замка: удобно, пока кто-то не унес всё содержимое.
Шаг 4. Загрузи первый файл
Просто перетаскиваешь нужный файл в веб-интерфейсе или используешь AWS CLI:
aws s3 cp localfile.txt s3://my-backup-2024/
Если используешь Yandex Cloud или Selectel — команды будут похожи, только URL может отличаться.
Шаг 5. Проверь, что всё работает
Зайди в бакет, найди свой файл и проверь, доступен ли он. Если включил публичный доступ — у тебя будет прямая ссылка, по которой можно скачать или посмотреть файл. Например:
https://my-backup-2024.s3.amazonaws.com/localfile.txt
Если всё видно — поздравляю, ты только что стал пользователем объектного хранилища.
Основные возможности S3-хранилищ
S3 не просто «облако, куда можно скинуть файлы». Это набор инструментов, которые позволяют автоматизировать, масштабировать и не париться о падениях сервера. Ниже — функции, которые я использую чаще всего.
Почти неограниченная масштабируемость
Когда в проекте копятся терабайты логов, изображений, видео и бэкапов — локальное хранилище начинает задыхаться. В S3 таких проблем нет: система спокойно переваривает миллионы объектов, и ты не ограничен по количеству или структуре.
Пример из практики: проект по видеонаблюдению. Камеры пишут круглосуточно, каждая — по 3–5 ГБ в день. С3 справляется без перегрузок и просадок. А ты не тратишь время на закупку новых дисков.
Распределённое хранение и высокая доступность
Объекты в S3 хранятся с избыточностью: данные автоматически копируются в несколько дата-центров. Это работает как RAID, но в облаке. У Amazon в каждом регионе три зоны доступности. Если одна выходит из строя, вы этого даже не замечаете.
Риски потери данных при таком подходе минимальны. Даже если один узел выходит из строя, доступ к файлам сохраняется без перебоев.
Гибкое управление и автоматизация
S3 позволяет настраивать «жизненный цикл» объектов. Например:
- Загруженные более 30 дней назад — архивировать в Glacier (дёшево, но медленно).
- Через 90 дней — удалить.
Автоматизируешь — и забываешь. Я так делаю с журналами: залил, сохранил на случай разборок, потом система сама почистит.
Мониторинг и логирование
Можно включить логирование операций: видно, кто, когда, с какого IP и к какому файлу обращался. S3 легко интегрируется с CloudTrail, Grafana и Prometheus. Если ты работаешь в продакшене — это обязательная опция. Логирование помогает в самых разных ситуациях: при утечке данных ты сможешь быстро определить, кто скачал файл; при ошибках в доступе — отследить источник запроса. А если бизнес требует отчётности, — нужный отчёт по доступам строится за пару кликов.
Важно понимать: S3 — это не «жёсткий диск в облаке», а полноценный инструмент для хранения данных. Он берёт на себя задачи, которые раньше требовали целую команду админов: резервное копирование, дублирование, мониторинг, очистку и контроль доступа. И чем больше у тебя данных, тем заметнее эта разница.
Безопасность данных в S3
Хранилище надёжное — это не значит, что можно расслабиться. В S3 есть хорошие инструменты безопасности, но работать они будут только если ты сам их включишь. Да, по умолчанию бакеты приватные, но дальше всё зависит от твоих настроек. А настроить неправильно — это как положить ключ от сейфа рядом с табличкой "ключ здесь".
Шифрование: в покое и при передаче
Данные можно шифровать двумя способами:
- На уровне объекта (SSE) — при сохранении файл автоматически шифруется ключом.
- На клиенте (CSE) — ты сам шифруешь файл до загрузки.
По умолчанию Amazon шифрует всё, что ты загружаешь, но лучше включить явное шифрование бакета и не надеяться на дефолт.
Если подключаешь сторонние клиенты (Rclone, MinIO) — убедись, что они умеют работать с SSE. Бывали случаи, когда клиент грузит файл, но в интерфейсе он отображается битым из-за несовместимого шифрования.
Контроль доступа: приватность по умолчанию
Доступ к данным регулируется через IAM-политики, которые действуют глобально по аккаунту, ACL на уровне объекта и политики бакета, которые позволяют настроить гибкие правила — кто и что может делать. Однако не стоит полагаться только на ACL. Если бакет должен быть приватным, лучше полностью отключить публичный доступ. Это всего одна галочка, которая защитит от случайного слива данных.
Из практики: один клиент открыл доступ к бакету с логами для тестов и забыл об этом. Через две недели поисковик заглянул в этот бакет, и файлы появились в результатах поиска. Хорошо, что там был только шум. Поэтому лучше сразу поставить настройку Block all public access и не переживать.
Соответствие требованиям и 152-ФЗ
Если ты хранишь персональные данные граждан РФ, то обязательно соблюдай требования 152-ФЗ. Это подразумевает, что шифрование данных — обязательное условие, дата-центр должен находиться в России (Selectel, VK Cloud и Яндекс Облако подойдут). Логи доступа должны храниться и регулярно проверяться, а уведомления при утечке информации должны быть отправлены в течение суток.
S3 сам по себе не нарушает требования закона. Нарушение происходит, когда выбираешь неправильную площадку для хранения данных или неправильно настраиваешь доступ.
Мониторинг, логирование и тревоги
Включи логирование запросов к бакету — это позволит увидеть, кто заходил, что смотрел и с какого IP. Так ты сможешь отследить подозрительную активность. Логи можно сохранить в отдельный бакет и проанализировать вручную или через систему SIEM. Чтобы отслеживать действия на уровне API, подключи CloudTrail. А если хочешь перестраховаться, настрой алерты — например, при попытке скачать больше 100 объектов за минуту тебе придёт уведомление.
Публичные блокировки — не забывай
Даже если ты дал объекту публичный доступ, S3 может его заблокировать, если включена глобальная блокировка. И наоборот — снял блокировку, и весь бакет стал доступен. Тут важно не забывать, что безопасность в S3 — это не одна настройка, а комбо: шифрование + политики + логирование.
Хочешь спать спокойно? Включи шифрование, заблокируй публичный доступ, настрой IAM, собери логи. Всё просто. А если что — восстановишь из версии или логов. S3 позволяет.
Классы хранения и тарифы в S3
В объектных хранилищах нет единого тарифа «на всё». Всё зависит от того, как часто ты обращаешься к файлам. Поэтому провайдеры делят хранилище на классы — от «горячих» для активной работы до «архивных», где данные просто лежат без движения.
Принцип простой: чем реже трогаешь файл, тем дешевле его хранить.
Горячее хранилище
Подходит для повседневной работы: ты загружаешь, скачиваешь, редактируешь. Это могут быть мультимедиа на сайте, документы сотрудников или пользовательские файлы в SaaS-сервисе. Доступ мгновенный, задержек нет. За это и платишь больше — ты используешь ресурс активно.
Холодное хранилище
Идеально для файлов, к которым обращаются редко: архивы отчётов, старые бэкапы, документы «на всякий случай». Доступ по-прежнему быстрый, но цена ниже — за счёт того, что ты к ним почти не лезешь.
Архивное хранилище
Это уже для хранения «в долгую». Данные лежат годами, а извлечение может занять часы. Подходит для юридических документов, видео с камер, старых логов. Здесь платишь за надёжность, а не за скорость. Архив — это не просто «холоднее», чем холодный класс, это другой режим хранения.
Как использовать все классы вместе
У большинства провайдеров можно настроить автоматическое перемещение данных. Например: первые 30 дней — горячий класс, потом холодный, а через полгода — архив или удаление. Один раз настроил — и система сама управляет хранением, без твоего участия.
Где применяется объектное хранилище S3
Если коротко — S3 подходит везде, где надо хранить файлы, не думать о серверах и иметь доступ к этим файлам в любой момент. Особенно когда файлов много, они весят прилично, и терять их нельзя. Ниже — практические кейсы, где S3 раскрывается на все сто.
Резервное копирование и бэкапы
Это самый частый сценарий. Всё, что можно сломать — надо бэкапить. Базы данных, конфиги, образы виртуалок, даже скриншоты переписки с заказчиком.
Как это выглядит на практике:
- Раз в сутки скрипт снимает дамп базы и отправляет в S3.
- Через 30 дней старые бэкапы автоматически уходят в архив или удаляются.
- Если что-то упало — достаёшь нужную версию за пару минут.
В одной из моих прошлых задач мы хранили бэкапы PostgreSQL из 15 филиалов компании. Каждый вечер — сжатый архив в S3. Всё просто и надёжно.
Big Data, аналитика и логирование
Когда собираешь логи со всех микросервисов — их становится слишком много, чтобы хранить на диске. S3 отлично держит петабайты логов и при этом легко интегрируется с системами аналитики: ClickHouse, Druid, Hadoop, Spark — все умеют забирать данные напрямую из S3.
Пример:
- Front пишет access-логи в формате JSON.
- Логи летят в S3 в реальном времени.
- Днём аналитики запускают отчёты на Spark — данные берутся прямо из бакета.
Ты не держишь отдельный сервер под логи, не чистишь вручную, не боишься, что места не хватит. Всё уходит в S3 — и живёт там, пока не скажешь удалить.
Статические сайты, видео и фотобанки
S3 можно использовать как хостинг: HTML-файлы, JS, изображения. Один бакет — и у тебя готова витрина сайта или медиабиблиотека.
Как это делается:
- Заливаешь сайт в бакет.
- Включаешь статический хостинг.
- Подключаешь CDN — и всё летает.
Пример — фотобанк для компании. 200 000 изображений, по 10 МБ каждое. Хранятся в S3, отдаются через Cloudflare. Никаких NGINX, никакого apache — только бакет и домен.
Персональные данные и документы
Если ты работаешь с договорами, паспортами клиентов, резюме или другими персональными данными, их можно хранить в S3, главное — шифровать данные и соблюдать требования 152-ФЗ. У Яндекс Облака и Selectel есть необходимые опции, а их дата-центры находятся на территории РФ.
Каждый файл шифруется при загрузке. Доступ предоставляется через временные ссылки, которые можно ограничить по времени или IP. Все действия с файлами логируются.
Файлы для приложений и SaaS
Если ты разработчик и у тебя сервис, где пользователи загружают документы, аватарки, видео, храни их в S3. Это избавит от необходимости забивать диск сервера и заботиться об отказоустойчивости.
В одном проекте я использовал такой подход: когда пользователь загружает аватарку, файл уходит в S3, а база данных сохраняет только ссылку на него. При удалении пользователя достаточно удалить объект по ключу.
Это удобно, гибко и не требует пересборки backend при росте нагрузки.
Видеонаблюдение и IoT
Камеры, датчики и сенсоры генерируют огромные объёмы данных — и всё это удобно хранить в S3. Ты получаешь удалённый доступ, долгосрочное хранение и дешёвые архивы без лишней мороки.
В одном реальном проекте камеры в торговом центре загружали видеофайлы объёмом по 2 ГБ. Эти файлы сразу попадали в холодный класс хранения, а через 60 дней удалялись автоматически.
Объектное хранилище S3 — универсальный инструмент, если ты не хочешь возиться с жёсткими дисками, RAID-массивами или заменой серверов. Всё хранится, как надо: доступно, быстро и безопасно.
Зачем подключать S3 к CDN и как это сделать
Хранилище — это половина дела. Вторая половина — как ты отдаёшь файлы пользователям. Если просто подключиться к S3 и расшарить файлы — всё будет работать, но не быстро. Особенно если у тебя видео, изображения или другие тяжёлые файлы. Вот тут и нужен CDN.
CDN (Content Delivery Network) — это как склад у дома. Вместо того чтобы каждый раз ехать за товаром на центральный склад (S3), клиент получает его с ближайшего узла CDN. Быстрее, стабильнее и без лишней нагрузки на хранилище.
Когда это нужно:
- У тебя трафик из разных регионов (например, сайт смотрят и в Новосибирске, и в Калининграде).
- На сайте или в приложении много медиафайлов.
- Надо снизить нагрузку на хранилище (S3 берёт плату за каждый запрос).
- Хочешь защититься от скачков нагрузки и DDoS.
Как подключить. Пример на Яндекс Облаке:
- Загружаешь нужные файлы в бакет Object Storage.
- Создаёшь CDN-ресурс через консоль или API.
- Указываешь источник — ссылку на бакет.
- Настраиваешь домен, кэш, HTTPS.
- Меняешь ссылки в коде или конфигурации — теперь всё идёт через CDN.
Похожий алгоритм у Selectel: создаёшь бакет, настраиваешь публичный доступ, подключаешь CDN Selectel или внешний, например, Gcore или Cloudflare. Если используешь фронтенд, не забудь про настройки CORS — иначе браузер устроит бойкот.
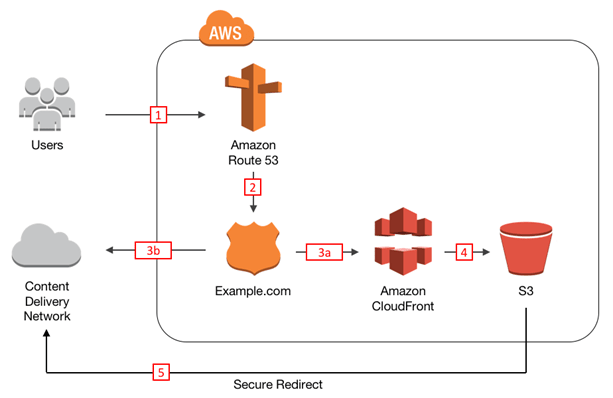
Реальный кейс: клиент хранил рекламные ролики в S3 и показывал их прямо с бакета. Всё работало, пока не вышли на федеральный уровень. Начались лаги, жалобы и просадки по метрикам. После подключения CDN от Gcore — загрузка видео стала мгновенной даже с мобильных сетей, нагрузка на S3 упала в 4 раза.
CDN — это не про понты. Это про скорость, экономию и стабильность. Подключается за 15 минут, даёт прирост сразу.
Почему бизнес выбирает Amazon S3 и аналоги
Когда у бизнеса начинают расползаться файлы — бэкапы, логи, фото, видео, документы клиентов — всё это надо где-то хранить. На флешке уже не получится, сервер быстро забивается, а на NAS'е всё падает, как только на него посмотрит менеджер. Тут и появляется объектное хранилище — как тихий и надёжный склад, который не требует внимания, но работает всегда.
Amazon S3 стал стандартом, потому что делает три вещи лучше всех: хранит, масштабируется и не ломается. У него 99.999999999% надёжности — это значит, что если ты загрузил туда файл, он останется там даже после ядерной зимы. Или, по крайней мере, после падения пары дата-центров. Но главное — всё это без участия админа. Не надо дежурить по выходным, перебирать «сдохшие» диски или думать, как отдать файл пользователю на другом конце страны.
С3 растёт вместе с проектом. У тебя 5 ГБ сегодня — ок. Завтра станет 5 ТБ — тоже ок. Ничего не меняется, кроме счёта в конце месяца. И то — если правильно настроить классы хранения, можно уложиться в разумный бюджет. Я работал с SaaS-платформой, которая за два месяца разрослась в пять раз. Никакой возни с железом — просто больше файлов, всё лежит в том же бакете.
И ещё одно — гибкость. Хочешь доступ через веб? Пожалуйста. Нужно подключить Rclone и заливать архивы с cron-скрипта? Работает. Интеграция с backend’ом? Есть SDK под Python, Go, JavaScript и даже PHP, если уж так случилось. Всё документировано, и если что — есть сообщество, где уже все грабли собраны в одной куче.
Теперь про деньги. Если сравнить с локальным решением: купить сервер, добавить диски, настроить RAID, а потом ещё обслуживать — выходит дороже. С3 не требует зарплаты админа, не уходит в отпуск и не ломается. А ещё можно сэкономить, если включить политики жизненного цикла — старые файлы будут сами перекладываться в холодный или архивный класс. Сэкономишь до 80% на объёмах, которые никто не трогает.

Если не хочется иметь дело с Amazon — в России хватает аналогов. Selectel, Яндекс Облако, VK Cloud, Cloud.ru — все они поддерживают S3 API, позволяют подключить CDN, дают классы хранения и работают с рублями, без плясок с валютой и налогами. Я сам использовал Selectel в трёх проектах подряд — ни одного сбоя, всё стабильно.
Именно поэтому бизнес и выбирает такие решения. Потому что это удобно, предсказуемо и снимает с тебя головную боль.
Российские аналоги S3-хранилищ: обзор лидеров
Не всё крутится вокруг Amazon. Особенно если ты работаешь в России и хочешь хранить персональные данные по 152-ФЗ, платить в рублях и быть уверенным, что дата-центр — не где-то в Ирландии. К счастью, у нас есть надёжные провайдеры, которые предлагают полноценные S3-совместимые хранилища. Вот те, с кем можно работать всерьёз.
Selectel
Один из первых, кто запустил полноценное объектное хранилище с поддержкой S3 API в РФ. Работает стабильно, есть горячие и холодные классы хранения, автоматическое перемещение по жизненному циклу, поддержка версионности, подробные политики доступа. Отлично подходит под любые задачи: от простого хранения до резервных копий на уровне корпоративных решений.
Плюс — мощная интеграция с другими сервисами Selectel и адекватная техподдержка. В одном из моих кейсов мы слили туда более 50 ТБ архивов с камер наблюдения. Через Glacier такой объём хранить было бы больно. Тут — легко.

Яндекс Облако (Object Storage)
Интерфейс похож на AWS, но всё по-русски, в рублях и с сервером в Москве. Интеграция с другими сервисами Яндекса (например, DataSphere или SpeechKit), есть поддержка классов хранения, CDN, политики доступа, CLI, SDK — всё на месте. Работает стабильно, в продакшн-сценариях — без сюрпризов.
Подходит как малым бизнесам, так и крупным. У меня есть кейс, где Яндекс Хранилище использовали для хранения обучающих курсов — всё, от видео до презентаций. Загружали 2–3 ТБ в месяц, отдавали в 5 раз больше — ни одного сбоя.
Timeweb Cloud
Менее известный, но развивающийся игрок. Поддерживает S3 API, даёт приятные тарифы и бонусы для стартапов. Интерфейс простой, документация читаемая. Хорошо подойдёт тем, кто только начинает или не хочет переплачивать. Правда, пока не хватает автоматизации и гибкости, как у старших братьев, но базовая функциональность есть.
VK Cloud Solutions
Отличный выбор, если нужно соответствие регуляторике и надёжность. Сервис построен на мощностях VK, даёт высокую скорость доступа, поддержку версий, шифрование, гибкие права. Есть даже своя система оповещений и логов. Подходит для тех, кто строит крупные системы или хочет гарантии уровня enterprise.
Cloud.ru
Платформа от МТС. Предлагает объектное хранилище с совместимостью с Amazon S3, но с уклоном в корпоративный сегмент. Удобно, если ты уже используешь другие сервисы экосистемы Cloud.ru: VPN, Kubernetes, машинное обучение. Хранилище гибкое, но пока не самое популярное среди небольших команд.
Каждый из этих провайдеров поддерживает базовые функции: загрузка через API, классы хранения, политики доступа, шифрование, интеграцию с CDN. Выбор зависит от твоих задач: где-то нужна скорость, где-то — цена, где-то — масштаб.
Если хочешь быстро стартовать и не разбираться долго — бери Selectel или Яндекс. Оба проверены, документация есть, техподдержка отвечает.
Ограничения и квоты в S3-хранилищах
Хотя S3-хранилища обеспечивают гибкость, масштабируемость и удобство, существуют некоторые ограничения, о которых важно помнить при работе с большими объёмами данных. Это нужно учитывать, чтобы избежать неприятных сюрпризов, например, неожиданных платежей или сбоев в процессе работы.
Общие ограничения по объёмам и количеству объектов
Объём данных в S3-хранилищах, включая Amazon S3 и российские аналоги, формально не ограничен — можно хранить терабайты, петабайты и больше. Но всё же есть технические лимиты, которые стоит учитывать.
Одно из ограничений — максимальный размер объекта. В Amazon S3 он составляет 5 ТБ. Загружать файлы больше можно, но только с помощью многочастной загрузки, что усложняет процесс. У российских провайдеров лимиты схожие, хотя возможны свои нюансы.
Также важно понимать, что количество объектов в бакете хоть и не ограничено, но при больших объёмах может страдать производительность. Особенно это заметно, когда бакет содержит множество маленьких файлов: растёт нагрузка на систему и увеличивается объём метаданных.
Квоты на количество запросов и их стоимость
S3-хранилища взимают плату за количество запросов, которые ты делаешь к объектам, и это важно учитывать, если ты работаешь с большими объёмами данных. Есть несколько типов запросов:
- PUT, COPY, POST, LIST — запросы, которые увеличивают стоимость.
- GET — запросы на извлечение данных. Чем больше запросов, тем больше платишь.
Например, запросы на извлечение данных из холодных классов хранения (например, Glacier) или на архивирование могут стоить дороже. Плата за запросы может варьироваться в зависимости от объёмов и тарифа. В некоторых облаках (например, Яндекс Облако) стоимость запросов к холодным данным может быть выше, чем в Amazon S3, где такие запросы идут через стандартный тариф.
Лимиты на пропускную способность и скорость
При передаче данных в облако или извлечении их из него можно столкнуться с ограничениями по пропускной способности. Это особенно важно для проектов, где происходит активная запись и чтение данных.
Для большинства облачных хранилищ скорость зависит от качества интернет-соединения.
В случае с S3-хранилищами скорость доступа к объектам напрямую зависит от класса хранения. Например, в стандартном классе доступ происходит мгновенно, а в архивном — с задержкой.
При массовой работе с большими объёмами данных важно учитывать использование многочастичной загрузки (multipart upload), что позволит более эффективно распределить нагрузку и ускорить процесс передачи.

Квоты на количество пользователей и доступ
Многие сервисы поддерживают создание множества пользователей с различными правами доступа через IAM (Identity and Access Management). Тем не менее, на количество пользователей или групп в IAM существуют лимиты. В случае с большими командами или распределёнными системами важно учитывать эти ограничения, чтобы не столкнуться с необходимостью перераспределять пользователей или создавать дополнительные аккаунты.
Что ещё нужно знать: политики и настройки безопасности
Если ты используешь S3 для хранения персональных данных или важной информации, важно понимать потенциальные риски и способы защиты.
Все данные, загружаемые в S3, можно шифровать. Однако на некоторых тарифах шифрование может быть платной опцией. Уточни условия у своего провайдера.
Кроме того, проверь настройки доступа. Особенно если к бакетам обращаются внешние пользователи. Ошибки в политиках доступа часто приводят к утечкам. Убедись, что у каждого объекта права доступа заданы корректно и избыточные разрешения отключены.
Безопасность в облаке — это не только про технологии, но и про внимательность к деталям.
Преодоление ограничений
Чтобы избежать проблем с лимитами и квотами, важно регулярно отслеживать количество запросов и общий объём хранимых данных. Нужно использовать правильные классы хранения для архивных данных и автоматизировать их перемещение по этим классам, например, архивируя старые данные. Также стоит проектировать систему с учётом возможных лимитов на запросы и скорость.
Несмотря на невероятную гибкость и масштабируемость S3-хранилищ, важно внимательно следить за ограничениями, чтобы избежать неприятных сюрпризов в процессе работы.
Как начать работу с объектным S3-совместимым хранилищем
Начать использовать S3-подобное хранилище можно буквально за 15 минут. Всё, что нужно — выбрать провайдера, зарегистрироваться, создать бакет и подключиться одним из трёх способов: через веб-интерфейс, API или консольную утилиту. Ниже — пошаговый сценарий, как это выглядит на практике.
Доступ через веб-интерфейс
Это самый простой способ — особенно если ты только начинаешь. В большинстве российских сервисов всё выглядит примерно одинаково:
- Регистрируешься на платформе (Selectel, Яндекс Облако, VK Cloud).
- Создаёшь бакет в разделе «Объектное хранилище» или «Object Storage».
- Загружаешь первый файл — перетаскиванием или через кнопку.
- Получаешь ссылку на объект — приватную или публичную (если разрешено).
Плюсы:
- Не нужно настраивать ни утилиты, ни доступы.
- Всё наглядно, видно, что где лежит.
- Подходит для хранения фото, документов, архивов.
Минусы:
- Не автоматизируется.
- Неудобно загружать сразу много файлов.
Доступ по S3 API: загружаем файлы через Rclone
Когда хочется автоматизировать процессы — например, делать ночной бэкап баз данных — без API не обойтись. Тут пригодится утилита вроде Rclone — она поддерживает большинство облачных хранилищ, включая все, кто умеет в S3.
Как подключиться:
- Устанавливаешь Rclone (sudo apt install rclone или скачиваешь с сайта).
- Настраиваешь конфиг: указываешь endpoint, ключи доступа и имя бакета.
- Проверяешь подключение командой rclone ls s3-selectel:backup-bucket.
- Загружаешь файл: rclone copy ./dump.sql s3-selectel:backup-bucket.
Важно: у разных провайдеров свои точки подключения (endpoint). Например:
- У Selectel: https://s3.storage.selcloud.ru
- У Яндекс Облака: https://storage.yandexcloud.net
Rclone хорош тем, что позволяет синхронизировать папки, удалять, копировать, закачивать сразу большие объёмы данных. И работает стабильно даже по кривому каналу связи.
Полезные ссылки и инструменты
- s3cmd — другая утилита, похожа на Rclone, но с чуть более дружелюбной CLI.
- Cyberduck — GUI-клиент, если хочешь работать как с FTP, но через окна.
- MinIO Client (mc) — кросс-платформенный инструмент, отлично подходит для админов.
- AWS CLI — если работаешь с Amazon или хочешь совместимость «на вырост».
Ещё можно использовать SDK (библиотеки) для Python, Go, Node.js, Java — удобно, если интегрируешь хранилище в своё приложение.
В реальных сценариях ты чаще всего комбинируешь всё: веб-интерфейс — для редких ручных операций, Rclone или CLI — для автоматизации, SDK — для связки с сервисами.
И да, если ты хранишь данные, к которым нужен ограниченный доступ — лучше генерируй временные ссылки. Это безопаснее, чем делать объект полностью публичным.
Выводы: стоит ли использовать объектное хранилище
Да, если ты работаешь с файлами, которых становится всё больше, и хочешь навести порядок. Объектное хранилище помогает не терять данные, не переплачивать за хранение и не тратить время на администрирование.
Представь: ты арендуешь ангар под документы — чисто, сухо, охрана на входе, круглосуточный доступ, автоматическая уборка. Только вместо бумажек — логи, бэкапы, медиафайлы и архивы проекта.
S3 особенно полезен, когда проект растёт и нужно хранить десятки или сотни гигабайт. Когда ты отдаёшь пользователям изображения, видео или документы. Когда хочешь наладить резервное копирование без лишних серверов и расписаний в cron. Когда есть требования по хранению персональных данных в РФ. Или когда хочешь, чтобы старые файлы удалялись автоматически, без твоего участия.
Это не волшебная палочка. Придётся настроить доступ, разобраться в API или освоить Rclone. Но потом всё работает на автопилоте: ничего не падает, ничего не пропадает, никто не звонит среди ночи с криком «файлы не открываются».
Объектное хранилище — это часть инфраструктуры. Если всё сделано правильно, оно просто работает. А ты — занимаешься проектом, а не цифровой уборкой.
Комментарии (0)
Новый комментарий
Новый комментарий отправлен на модерацию