
Внимание
Мы работаем в штатном режиме. Наши склады готовы поставлять оборудование клиентам из Российской Федерации несмотря на санкционные запреты ЕС и США. Оборудование в РФ ввозится легально благодаря новому законодательству с параллельным импортом. Звоните и уточняйте! Информация актуальна на 02.04.26В связи с участившимися случаями недобросовестной конкуренции обращаем ваше внимание, что мы не передаем персональные данные третьим лицам
Поиск по сайту

GPU‑сервер NVIDIA с 8 ускорителями NVIDIA H200 (SXM)
Наличие по запросу 
")
 Запросить сертификат
Запросить сертификат
 Прямой импорт оборудования
Прямой импорт оборудованияиз Китая и ОАЭ без посредников
")
")
")
Наличие по запросу
Гарантия до 5 лет
Диагностика перед отправкой
С нами выгодно и удобно!
- Поддержка персонального менеджера
- Партнёрские скидки до 70%
- Онлайн-кабинет гарантийного сервиса
?
Как купить?
Раз, два и все делаРассчитаем стоимость
Присылайте спецификацию для подбора и расчета стоимости оборудования
1Раз
Привезём и подключим
Подключим и настроим оборудование в вашем офисе или ЦОДе
2Два
Характеристики
Производитель
Модель
nvidia nvidia h200 sxm
Максимальное количество GPU
8
Совместимые GPU
NVIDIA H200 (SXM)
Форм-фактор
8U
Максимальный объем оперативной памяти (ГБ)
2048
Слоты для оперативной памяти
32
Жесткие диски
10x 2.5" NVMe
Максимальное количество отсеков для жестких дисков
10
Тип корпуса
Rack
Тип оперативной памяти
DDR5
Количество отсеков для БП
6
Интерфейс накопителей
NVMe
Количество отсеков 3.5" Hot Swap
0
Количество отсеков 2.5" Hot Swap
10
Лицензии

NVIDlA Al Enterprise Essentials Subscription per GPU, 1 Year one Year subscription

Лицензия NVIDlA Al Enterprise Essentials Subscription per GPU, 1 Year one Year subscription

NVIDIA Al Enterprise Essentials Perpetual License & Support per GPU, Permanent + 5 Years Original Service
Лицензия NVIDIA Al Enterprise Essentials Perpetual License & Support per GPU, Permanent + 5 Years Original Service

NVIDlA Al Enterprise Essentials Subscription per GPU, 2 Years one Year subscription
Лицензия NVIDlA Al Enterprise Essentials Subscription per GPU, 2 Years one Year subscription

Отсрочка платежа
В зависимости от суммы поставляемого товара можем предоставить отсрочку платежа на срок от 5 до 90 дней. Условия отсрочки платежа рассматриваются индивидуально. Подробную информацию уточняйте у вашего менеджера.
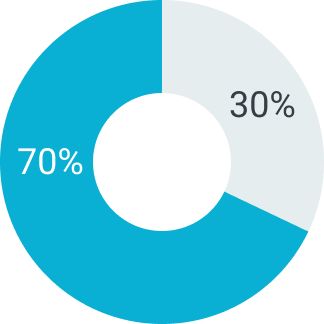
70%
Первый платеж
Первый платеж
30%
Второй платеж
Второй платеж
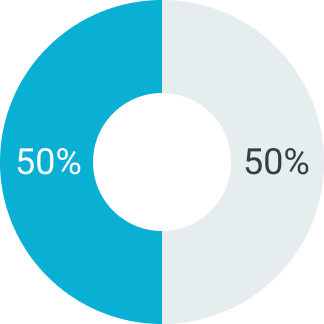
50%
Первый платеж
Первый платеж
50%
Второй платеж
Второй платеж
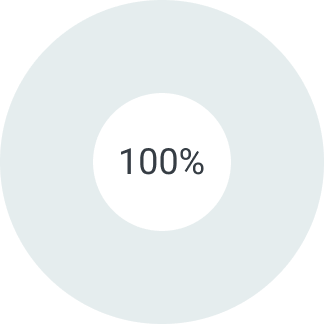
0%
Первый платеж
Первый платеж
100%
Второй платеж
Второй платеж
Описание
GPU‑сервер NVIDIA с 8 ускорителями NVIDIA H200 (SXM) представляет собой передовое вычислительное решение, созданное для интенсивных задач искусственного интеллекта, глубокого обучения и высокопроизводительных научных вычислений. Оснащённый восемью графическими процессорами NVIDIA H200 с 141 ГБ памяти HBM3e на каждый и пропускной способностью до 4,8 ТБ/с, сервер обеспечивает исключительную производительность и масштабируемость для обучения крупных AI-моделей и инференса в современных дата-центрах и вычислительных кластерах.
Архитектура NVIDIA H200 и ключевые особенности сервера

Ускорители NVIDIA H200 построены на архитектуре Hopper с использованием 4-нм техпроцесса и включают 456 тензорных ядер четвёртого поколения, обеспечивающих высокую точность и производительность благодаря поддержке новейших числовых форматов FP8 и FP16. Каждый GPU оснащён 141 ГБ памяти HBM3e с пропускной способностью до 4,8 ТБ/с. Топология NVLink 5.0 и NVSwitch обеспечивает высокоскоростное соединение между восемью GPU с пропускной способностью до 900 ГБ/с, что минимизирует задержки при обмене данными и способствует масштабируемой параллельной обработке вычислений.
Технология Multi-Instance GPU (MIG) позволяет разделить каждый ускоритель на до 7 виртуальных инстансов, что повышает гибкость и эффективность распределения ресурсов.
Инфраструктура, программное обеспечение и сферы применения
Сервер NVIDIA с 8 H200 SXM поддерживает современные технологии дата-центров, включая NVMe SSD и высокопроизводительные сетевые интерфейсы InfiniBand и Ethernet со скоростью до 400 Гбит/с. Он совместим с программным стеком NVIDIA AI Enterprise, включающим CUDA, TensorRT, Triton, а также основными AI-фреймворками такими как PyTorch, TensorFlow и DeepSpeed. Это делает сервер оптимальным выбором для масштабируемого обучения языковых моделей, генеративного ИИ, HPC и научных исследований.
- 8 ускорителей NVIDIA H200 SXM с 141 ГБ памяти HBM3e каждый
- Пропускная способность памяти до 4,8 ТБ/с на GPU
- NVLink 5.0 и NVSwitch с пропускной способностью до 900 ГБ/с
- Поддержка Multi-Instance GPU (MIG) для эффективной виртуализации ресурсов
- Высокоскоростные сетевые интерфейсы InfiniBand и Ethernet
- Совместимость с NVIDIA AI Enterprise и ведущими AI-фреймворками
- Идеальное решение для масштабируемого обучения, инференса и HPC задач
Официальное сертифицированное оборудование
Бесплатный
подбор оборудования
подбор оборудования
Расчёт КП за 20 минут
Отсрочка платежа
до 90 дней
до 90 дней
Доставка по Москве 2-3 дня