
Внимание
Мы работаем в штатном режиме. Наши склады готовы поставлять оборудование клиентам из Российской Федерации несмотря на санкционные запреты ЕС и США. Оборудование в РФ ввозится легально благодаря новому законодательству с параллельным импортом. Звоните и уточняйте! Информация актуальна на 16.03.26В связи с участившимися случаями недобросовестной конкуренции обращаем ваше внимание, что мы не передаем персональные данные третьим лицам
Поиск по сайту

Серверная платформа NVIDIA HGX A100 8-GPU
Наличие по запросу 

 Запросить сертификат
Запросить сертификат
 Прямой импорт оборудования
Прямой импорт оборудованияиз Китая и ОАЭ без посредников

Наличие по запросу
Почему нет цен?
Уточнить ценуГарантия до 5 лет
Диагностика перед отправкой
С нами выгодно и удобно!
- Поддержка персонального менеджера
- Партнёрские скидки до 70%
- Онлайн-кабинет гарантийного сервиса
?
Как купить?
Раз, два и все делаРассчитаем стоимость
Присылайте спецификацию для подбора и расчета стоимости оборудования
1Раз
Привезём и подключим
Подключим и настроим оборудование в вашем офисе или ЦОДе
2Два
Характеристики
Производитель
Модель
HGX A100 8-GPU
Максимальное количество GPU
8
Тип поддерживаемых GPU
8x встроенных GPU
Совместимые GPU
NVIDIA A100
Семейство процессоров
Intel Xeon Scalable Gen3
Максимальный объем оперативной памяти (ГБ)
2048
Слоты для оперативной памяти
32
Жесткие диски
2x NVMe M.2, 6x NVMe U.2
Максимальное количество отсеков для жестких дисков
6
Тип корпуса
Rack
Тип оперативной памяти
DDR4
Интерфейс накопителей
NVMe
Количество отсеков 3.5" Hot Swap
0
Количество отсеков 2.5" Hot Swap
6
Комплектующие для NVIDIA HGX A100 8-GPU
PCI-модули


Жесткие диски














Процессоры

Совместимость
Серверы Supermicro

Серверы GIGABYTE









Лицензии

NVIDlA Al Enterprise Essentials Subscription per GPU, 2 Years one Year subscription

Лицензия NVIDlA Al Enterprise Essentials Subscription per GPU, 2 Years one Year subscription

NVIDIA Al Enterprise Essentials Perpetual License & Support per GPU, Permanent + 5 Years Original Service
Лицензия NVIDIA Al Enterprise Essentials Perpetual License & Support per GPU, Permanent + 5 Years Original Service

NVIDlA Al Enterprise Essentials Subscription per GPU, 3 Year one Year subscription
Лицензия NVIDlA Al Enterprise Essentials Subscription per GPU, 3 Year one Year subscription

Отсрочка платежа
В зависимости от суммы поставляемого товара можем предоставить отсрочку платежа на срок от 5 до 90 дней. Условия отсрочки платежа рассматриваются индивидуально. Подробную информацию уточняйте у вашего менеджера.
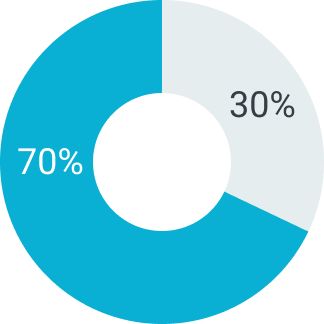
70%
Первый платеж
Первый платеж
30%
Второй платеж
Второй платеж
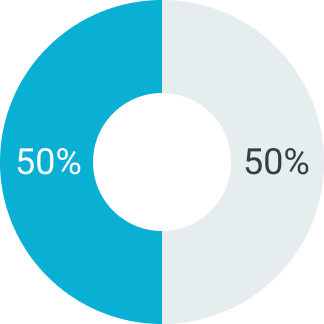
50%
Первый платеж
Первый платеж
50%
Второй платеж
Второй платеж
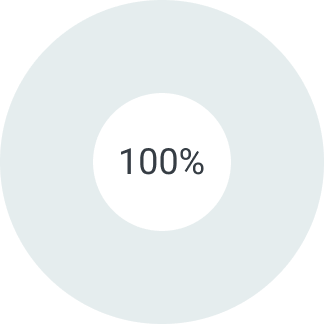
0%
Первый платеж
Первый платеж
100%
Второй платеж
Второй платеж
Описание
Серверная платформа NVIDIA HGX A100 с восемью графическими ускорителями A100 — это передовая вычислительная платформа для задач искусственного интеллекта, высокопроизводительных вычислений и анализа больших данных. Спроектированный на базе архитектуры NVIDIA Ampere и технологии NVSwitch, эта серверная платформа обеспечивает максимальную вычислительную плотность и полную связность GPU, что делает ее идеальным решением для самых ресурсоёмких задач: от обучения крупных языковых моделей и генеративных нейросетей до моделирования физических процессов и научных симуляций. Система ориентирована на крупные исследовательские центры, облачные провайдеры, суперкомпьютерные кластеры и корпорации, создающие собственные ИИ-инфраструктуры. Благодаря невероятной производительности, масштабируемости и гибкости HGX A100 8-GPU является технологическим сердцем решений уровня NVIDIA DGX SuperPOD и аналогичных экосистем.

Вычислительная архитектура Ampere и преимущества A100
Каждый из восьми ускорителей NVIDIA A100 в составе серверной платформы построен на архитектуре Ampere и оснащён высокоскоростной памятью HBM2e объёмом 40 ГБ или 80 ГБ, обеспечивающей пропускную способность до 2 ТБ/с. Ускорители поддерживают вычисления в форматах FP64, FP32, TF32, FP16, INT8, а также технологию sparsity-aware, позволяющую значительно повысить эффективность обучения моделей. Совокупная мощность всех восьми A100 позволяет обрабатывать триллионы операций в секунду, обеспечивая рекордную скорость обучения трансформеров, генеративных ИИ, систем предиктивной аналитики и многопоточных HPC-задач.
Ключевым элементом архитектуры HGX A100 является интеграция NVSwitch, создающая симметричную высокоскоростную топологию между всеми восьмью GPU. Это обеспечивает равномерный и сверхбыстрый обмен данными между ускорителями (до 600 ГБ/с на GPU), что критически важно для распределённого обучения и масштабируемых симуляций. Такая структура исключает “бутылочные горлышки” при межграфическом взаимодействии, позволяя задействовать весь потенциал системы без потерь.
Технология Multi-Instance GPU (MIG), реализованная в A100, позволяет разделить каждый GPU на несколько изолированных экземпляров, предоставляя виртуальные ресурсы для одновременной работы разных приложений или пользователей. Это значительно повышает эффективность использования оборудования и делает систему пригодной не только для монолитных задач, но и для высоконагруженных мультизадачных сред.
Инфраструктура, интеграция и ключевые возможности
Серверная платформа HGX A100 8-GPU — это платформа, подготовленная для использования в корпоративных ЦОДах, научных кластерах, государственных системах и ИИ-облаках. Она совместима с программной экосистемой NVIDIA AI Enterprise и поддерживает ведущие фреймворки и библиотеки: CUDA, cuDNN, NCCL, TensorRT, RAPIDS, Triton Inference Server, PyTorch, TensorFlow, JAX и другие. Это обеспечивает быструю интеграцию и сокращает время до продуктивного запуска моделей и приложений.
- 8 ускорителей NVIDIA A100 с 40 ГБ или 80 ГБ HBM2e на каждом
- Полносвязная NVSwitch-топология с пропускной способностью 600 ГБ/с между GPU
- Поддержка TF32, FP64, FP16, INT8 и sparsity-aware вычислений
- Функция Multi-Instance GPU (MIG) для виртуализации GPU
- Совместимость с NVIDIA AI, NGC, TensorRT, Triton и другими инструментами
- Оптимизация под масштабируемые кластеры и суперкомпьютеры
- Интерфейсы PCIe Gen4, поддержка NVLink, InfiniBand и NVIDIA GPUDirect
Такая система идеально подходит для запуска моделей, содержащих сотни миллиардов параметров, построения цифровых двойников, симуляции климата, аэродинамики, биоинформатики, расчёта рисков и других задач, где требуется максимальная вычислительная производительность. Кроме того, серверная платформа широко используется в облачных ИИ-сервисах, дата-центрах для инференса, в научных и медицинских центрах для обработки и анализа данных. NVIDIA HGX A100 8-GPU — это не просто серверная платформа, это фундамент для следующих этапов технологической эволюции, позволяющий организациям реализовать амбициозные проекты и ускорить внедрение ИИ в бизнес и науку.
Сферы применения NVIDIA HGX A100
- Обучение и инференс крупных ИИ-моделей
- Высокопроизводительные вычисления (HPC)
- Обработка больших данных
- Научное моделирование и симуляции
- ИИ в здравоохранении и нефтегазе
- Обработка видео и изображений
- Интеграция в суперкомпьютеры и дата-центры
Официальное сертифицированное оборудование
Бесплатный
подбор оборудования
подбор оборудования
Расчёт КП за 20 минут
Отсрочка платежа
до 90 дней
до 90 дней
Доставка по Москве 2-3 дня