
Внимание
Мы работаем в штатном режиме. Наши склады готовы поставлять оборудование клиентам из Российской Федерации несмотря на санкционные запреты ЕС и США. Оборудование в РФ ввозится легально благодаря новому законодательству с параллельным импортом. Звоните и уточняйте! Информация актуальна на 04.04.26В связи с участившимися случаями недобросовестной конкуренции обращаем ваше внимание, что мы не передаем персональные данные третьим лицам
Поиск по сайту

Серверная платформа NVIDIA HGX H100 4-GPU
Наличие по запросу 

 Запросить сертификат
Запросить сертификат
 Прямой импорт оборудования
Прямой импорт оборудованияиз Китая и ОАЭ без посредников

Наличие по запросу
Почему нет цен?
Уточнить ценуГарантия до 5 лет
Диагностика перед отправкой
С нами выгодно и удобно!
- Поддержка персонального менеджера
- Партнёрские скидки до 70%
- Онлайн-кабинет гарантийного сервиса
?
Как купить?
Раз, два и все делаРассчитаем стоимость
Присылайте спецификацию для подбора и расчета стоимости оборудования
1Раз
Привезём и подключим
Подключим и настроим оборудование в вашем офисе или ЦОДе
2Два
Характеристики
Производитель
Модель
HGX H100 4-GPU
Максимальное количество GPU
4
Тип поддерживаемых GPU
4x встроенных GPU
Совместимые GPU
NVIDIA H100
Семейство процессоров
Intel Xeon Scalable Gen4
Максимальный объем оперативной памяти (ГБ)
2048
Слоты для оперативной памяти
32
Жесткие диски
4x 2.5" NVMe
Максимальное количество отсеков для жестких дисков
4
Тип корпуса
Rack
Тип оперативной памяти
DDR5
Интерфейс накопителей
NVMe
Количество отсеков 3.5" Hot Swap
0
Количество отсеков 2.5" Hot Swap
4
Комплектующие для NVIDIA HGX H100 4-GPU
PCI-модули
Видеокарты

Совместимость
Серверы HPE

Серверы Fujitsu

Серверы GIGABYTE




Лицензии

NVIDlA Al Enterprise Essentials Subscription per GPU, 3 Year one Year subscription

Лицензия NVIDlA Al Enterprise Essentials Subscription per GPU, 3 Year one Year subscription

NVIDlA Al Enterprise Essentials Subscription per GPU, 2 Years one Year subscription
Лицензия NVIDlA Al Enterprise Essentials Subscription per GPU, 2 Years one Year subscription

NVIDlA Al Enterprise Essentials Subscription per GPU, 1 Year one Year subscription
Лицензия NVIDlA Al Enterprise Essentials Subscription per GPU, 1 Year one Year subscription

Отсрочка платежа
В зависимости от суммы поставляемого товара можем предоставить отсрочку платежа на срок от 5 до 90 дней. Условия отсрочки платежа рассматриваются индивидуально. Подробную информацию уточняйте у вашего менеджера.
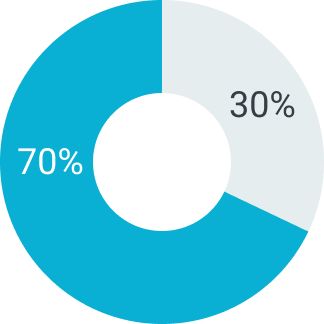
70%
Первый платеж
Первый платеж
30%
Второй платеж
Второй платеж
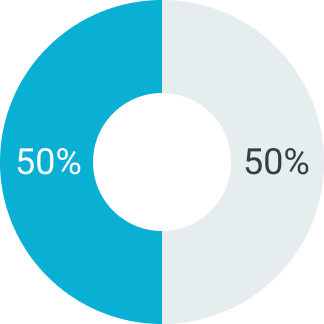
50%
Первый платеж
Первый платеж
50%
Второй платеж
Второй платеж
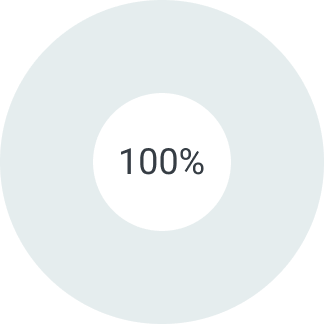
0%
Первый платеж
Первый платеж
100%
Второй платеж
Второй платеж
Описание
Серверная платформа NVIDIA HGX H100 с четырьмя графическими ускорителями H100 — это современная вычислительная платформа, предназначенная для работы с самыми ресурсоёмкими задачами в области искусственного интеллекта, глубокого обучения, моделирования и научных вычислений. Построенная на архитектуре NVIDIA Hopper, HGX H100 4-GPU предлагает высокую производительность, масштабируемость и энергоэффективность, объединяя возможности графических и тензорных вычислений в одном решении. Благодаря тесной связке между GPU через NVLink и NVSwitch, система обеспечивает сверхнизкие задержки и высокую пропускную способность, что особенно важно при распределённом обучении моделей и выполнении многопоточечных задач. Серверная платформа идеально подходит для исследовательских центров, ИИ-лабораторий, суперкомпьютерных кластеров и организаций, стремящихся использовать потенциал больших языковых моделей, симуляций и генеративного ИИ в своей работе.

Преимущества архитектуры Hopper и GPU H100
Графические ускорители NVIDIA H100 — это основа архитектуры Hopper, обеспечивающая значительный прирост производительности по сравнению с предыдущим поколением A100. Каждый H100 оснащён 80 ГБ памяти HBM3 с пропускной способностью до 3 ТБ/с, что позволяет эффективно обрабатывать огромные объёмы данных в реальном времени. Благодаря использованию Transformer Engine и поддержке формата FP8, H100 значительно ускоряет обучение и инференс трансформеров и других нейросетевых моделей, снижая при этом требования к вычислительным ресурсам и энергопотреблению.
Технология NVLink 4-го поколения и интеграция NVSwitch обеспечивают высокоскоростную коммуникацию между всеми четырьмя GPU в системе. Это позволяет задействовать весь потенциал памяти и вычислений без узких мест при обмене данными, что критично при распределённой обработке и многозадачной нагрузке. Благодаря поддержке Multi-Instance GPU (MIG), каждый H100 может быть разделён на изолированные экземпляры, обеспечивая параллельную работу различных приложений или пользователей в рамках одной системы.
Серверная платформа HGX H100 поддерживает работу с современными фреймворками: PyTorch, TensorFlow, JAX, Megatron, DeepSpeed и другими. Он также оптимизирован для использования с CUDA, cuDNN, TensorRT и другими компонентами экосистемы NVIDIA AI Enterprise, позволяя быстро развернуть и масштабировать приложения машинного обучения и анализа данных в производственной среде.
Инфраструктурные возможности и сценарии применения
Платформа HGX H100 4-GPU разработана для развёртывания в современных дата-центрах, ИИ-кластерах и вычислительных инфраструктурах, требующих высокой отказоустойчивости, масштабируемости и энергоэффективности. Благодаря модульной конструкции и поддержке новейших стандартов подключения, серверная платформа легко интегрируется в существующую ИТ-инфраструктуру и может использоваться как в одиночном узле, так и в составе распределённой системы.
- 4 графических ускорителя NVIDIA H100 (80 ГБ HBM3 каждый)
- Суммарная пропускная способность межсвязи — до 900 ГБ/с на GPU
- Поддержка TF32, FP64, FP16, FP8, INT8 и Transformer Engine
- Механизм MIG для виртуализации GPU-ресурсов
- Интеграция с NVIDIA AI Enterprise, NGC и Triton Inference Server
- Совместимость с PCIe Gen5, NVLink 4.0 и InfiniBand
- Оптимизация для больших языковых моделей и генеративного ИИ
Серверная платформа находит применение в таких отраслях, как медицина, энергетика, автомобилестроение, оборона, финансы, научные исследования и облачные ИИ-сервисы. Она используется для обучения LLM-моделей (GPT, PaLM, BERT), молекулярного моделирования, предиктивной аналитики, обработки изображений и видео, анализа временных рядов и создания цифровых двойников. NVIDIA HGX H100 4-GPU Server — это фундамент для цифрового будущего, позволяющий организациям кратно ускорить научные открытия, оптимизировать ИИ-процессы и вывести инновационные разработки на новый уровень производительности.
Сферы применения NVIDIA HGX H100
- Обучение и инференс крупных ИИ-моделей
- HPC и научные расчёты
- Анализ больших данных
- Моделирование и симуляции
- ИИ в здравоохранении и нефтегазе
- Обработка видео и изображений
- Дата-центры и суперкомпьютеры
Официальное сертифицированное оборудование
Бесплатный
подбор оборудования
подбор оборудования
Расчёт КП за 20 минут
Отсрочка платежа
до 90 дней
до 90 дней
Доставка по Москве 2-3 дня