
Внимание
Мы работаем в штатном режиме. Наши склады готовы поставлять оборудование клиентам из Российской Федерации несмотря на санкционные запреты ЕС и США. Оборудование в РФ ввозится легально благодаря новому законодательству с параллельным импортом. Звоните и уточняйте! Информация актуальна на 13.12.25В связи с участившимися случаями недобросовестной конкуренции обращаем ваше внимание, что мы не передаем персональные данные третьим лицам
Поиск по сайту

Серверная платформа NVIDIA HGX H200 8-GPU
Наличие по запросу 

 Запросить сертификат
Запросить сертификат
 Прямой импорт оборудования
Прямой импорт оборудованияиз Китая и ОАЭ без посредников


Наличие по запросу
Почему нет цен?
Уточнить ценуГарантия до 5 лет
Диагностика перед отправкой
С нами выгодно и удобно!
- Поддержка персонального менеджера
- Партнёрские скидки до 70%
- Онлайн-кабинет гарантийного сервиса
?
Как купить?
Раз, два и все делаРассчитаем стоимость
Присылайте спецификацию для подбора и расчета стоимости оборудования
1Раз
Привезём и подключим
Подключим и настроим оборудование в вашем офисе или ЦОДе
2Два
Характеристики
Производитель
Модель
HGX H200 8-GPU
Максимальное количество GPU
8
Тип поддерживаемых GPU
8x встроенных GPU
Совместимые GPU
NVIDIA H200
Семейство процессоров
Intel Xeon Scalable Gen5
Максимальный объем оперативной памяти (ГБ)
2048
Слоты для оперативной памяти
32
Жесткие диски
5x 2.5" NVMe
Максимальное количество отсеков для жестких дисков
5
Тип корпуса
Rack
Тип оперативной памяти
DDR5
Интерфейс накопителей
NVMe
Количество отсеков 3.5" Hot Swap
0
Количество отсеков 2.5" Hot Swap
5
Комплектующие для NVIDIA HGX H200 8-GPU
PCI-модули


Жесткие диски


Оперативная память



Процессоры


Видеокарты

Лицензии

NVIDlA Al Enterprise Essentials Subscription per GPU, 1 Year one Year subscription

Лицензия NVIDlA Al Enterprise Essentials Subscription per GPU, 1 Year one Year subscription

NVIDIA Al Enterprise Essentials Perpetual License & Support per GPU, Permanent + 5 Years Original Service
Лицензия NVIDIA Al Enterprise Essentials Perpetual License & Support per GPU, Permanent + 5 Years Original Service

NVIDlA Al Enterprise Essentials Subscription per GPU, 3 Year one Year subscription
Лицензия NVIDlA Al Enterprise Essentials Subscription per GPU, 3 Year one Year subscription

Отсрочка платежа
В зависимости от суммы поставляемого товара можем предоставить отсрочку платежа на срок от 5 до 90 дней. Условия отсрочки платежа рассматриваются индивидуально. Подробную информацию уточняйте у вашего менеджера.
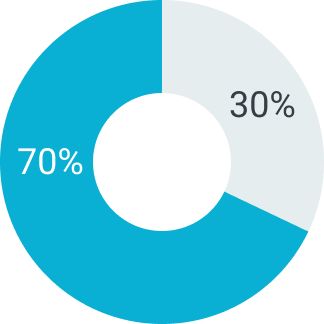
70%
Первый платеж
Первый платеж
30%
Второй платеж
Второй платеж
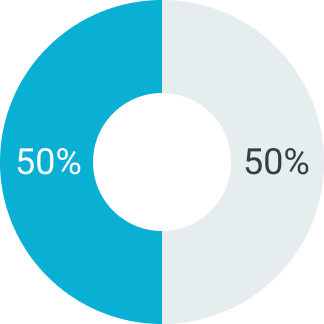
50%
Первый платеж
Первый платеж
50%
Второй платеж
Второй платеж
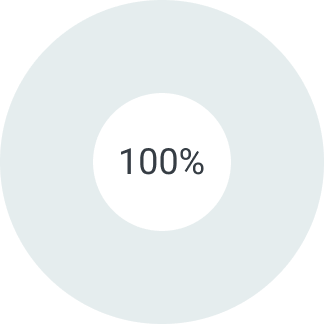
0%
Первый платеж
Первый платеж
100%
Второй платеж
Второй платеж
Описание
Серверная платформа NVIDIA HGX H200 с восемью графическими ускорителями H200 — это флагманская вычислительная платформа нового поколения, предназначенная для высокопроизводительных вычислений, обучения больших языковых моделей (LLM), генеративного ИИ, цифровых двойников и комплексных симуляций. Построенный на базе архитектуры NVIDIA Hopper и усовершенствованный в направлении ИИ и работы с большими объёмами данных, HGX H200 8-GPU представляет собой технологический прорыв в области ИИ-инфраструктуры. Он обеспечивает рекордную производительность на ватт, высочайшую пропускную способность, расширенные возможности передачи данных между GPU и поддержку новейших форматов вычислений, включая FP8, что делает его незаменимым компонентом суперкомпьютеров, ИИ-кластеров и дата-центров гипермасштаба. Эта платформа ориентирована на предприятия, научные учреждения и провайдеров облачных сервисов, которые внедряют масштабируемый ИИ в ядро своего бизнеса.

Графические ускорители H200: максимум вычислений и памяти
Ускоритель NVIDIA H200 — это следующий шаг в развитии архитектуры Hopper, получивший значительное обновление по сравнению с H100. Главное отличие — использование сверхбыстрой памяти HBM3e объёмом 141 ГБ на каждом GPU, с пропускной способностью до 4,8 ТБ/с, что даёт почти 2-кратное преимущество в работе с большими моделями и наборами данных. Это критично для задач, связанных с генерацией, обучением и инференсом языковых моделей, содержащих сотни миллиардов параметров.
Восемь H200 в составе серверной платформы соединены через NVSwitch с поддержкой NVLink 4.0, формируя полностью связную топологию с пропускной способностью до 900 ГБ/с между GPU. Это позволяет организовать межграфическую обработку без задержек и перегрузок шины, необходимую для распределённых вычислений и сложных параллельных симуляций. H200 также поддерживает технологию Multi-Instance GPU (MIG), позволяя разбивать каждый GPU на до 7 изолированных логических блоков, что актуально в мультиарендных средах и при работе с виртуализированными ИИ-сервисами.
Ключевой особенностью H200 остаётся Transformer Engine, который автоматически переключает точность между FP8 и FP16, в зависимости от этапа обработки и чувствительности модели. Это обеспечивает ускорение как обучения, так и вывода моделей, с сохранением требуемого уровня точности и снижением энергозатрат. Серверная платформа NVIDIA HGX H200 8-GPU поддерживает всё программное окружение NVIDIA AI Enterprise: CUDA, cuDNN, NCCL, TensorRT, Triton, RAPIDS, а также все популярные фреймворки — PyTorch, TensorFlow, JAX, DeepSpeed и Megatron.
Инфраструктура, масштабирование и практическое применение
Платформа HGX H200 создана для масштабирования в крупнейших ИИ-инфраструктурах: от частных дата-центров и корпоративных кластеров до глобальных облаков. Поддержка PCIe Gen5, NVLink, InfiniBand и GPUDirect RDMA позволяет максимально эффективно подключать серверную платформу к системам хранения, другим вычислительным узлам и сети с минимальными задержками. Устройство рассчитано на круглосуточную эксплуатацию в условиях высокой плотности, поддерживает резервируемое питание, интеллектуальное охлаждение и интеграцию в стоечную архитектуру формата 4U или 6U (в зависимости от производителя).
- 8 GPU NVIDIA H200 (по 141 ГБ HBM3e, до 4,8 ТБ/с каждый)
- Полносвязная NVSwitch-топология с NVLink 4.0 — до 900 ГБ/с
- Transformer Engine с поддержкой FP8 и FP16
- Multi-Instance GPU (до 56 MIG-инстансов на сервер)
- Поддержка PyTorch, TensorFlow, JAX, DeepSpeed, CUDA и Triton
- Совместимость с PCIe Gen5, InfiniBand, GPUDirect
- Интеграция с NVIDIA AI Enterprise и NGC-контейнерами
Серверная платформа HGX H200 8-GPU востребована в самых передовых сценариях: от обучения LLM и мультимодальных ИИ (текст, изображение, видео) до климатических симуляций, цифровых аватаров, генерации медицинских изображений и предиктивной аналитики в реальном времени. Она применяется в разработке автономных систем, анализе ДНК, химических симуляциях, в оборонных, медицинских и финансовых отраслях. Это флагман в мире вычислений, созданный для организаций, которым нужно больше, чем просто сервер — нужна инфраструктура будущего, уже сегодня.
Сферы применения NVIDIA HGX H200
- Обучение и инференс ИИ-моделей
- HPC и научные расчёты
- Анализ больших данных
- Моделирование и симуляции
- ИИ в здравоохранении и нефтегазе
- Обработка видео и изображений
- Дата-центры и суперкомпьютеры
Официальное сертифицированное оборудование
Бесплатный
подбор оборудования
подбор оборудования
Расчёт КП за 20 минут
Отсрочка платежа
до 90 дней
до 90 дней
Доставка по Москве 2-3 дня