
Внимание
Мы работаем в штатном режиме. Наши склады готовы поставлять оборудование клиентам из Российской Федерации несмотря на санкционные запреты ЕС и США. Оборудование в РФ ввозится легально благодаря новому законодательству с параллельным импортом. Звоните и уточняйте! Информация актуальна на 27.02.26В связи с участившимися случаями недобросовестной конкуренции обращаем ваше внимание, что мы не передаем персональные данные третьим лицам
Поиск по сайту

Графический процессор NVIDIA Blackwell B200
Наличие по запросу 

 Запросить сертификат
Запросить сертификат
 Прямой импорт оборудования
Прямой импорт оборудованияиз Китая и ОАЭ без посредников
Наличие по запросу
Почему нет цен?
Уточнить ценуГарантия до 5 лет
Диагностика перед отправкой
С нами выгодно и удобно!
- Поддержка персонального менеджера
- Партнёрские скидки до 70%
- Онлайн-кабинет гарантийного сервиса
?
Как купить?
Раз, два и все делаРассчитаем стоимость
Присылайте спецификацию для подбора и расчета стоимости оборудования
1Раз
Привезём и подключим
Подключим и настроим оборудование в вашем офисе или ЦОДе
2Два
Характеристики
Производитель
Модель
Blackwell B200
Тип видеопамяти
HBM3E
Архитектура
Blackwell
Объем видеопамяти
192 GB
Лицензии

NVIDlA Al Enterprise Essentials Subscription per GPU, 2 Years one Year subscription

Лицензия NVIDlA Al Enterprise Essentials Subscription per GPU, 2 Years one Year subscription

NVIDlA Al Enterprise Essentials Subscription per GPU, 1 Year one Year subscription
Лицензия NVIDlA Al Enterprise Essentials Subscription per GPU, 1 Year one Year subscription

NVIDIA Al Enterprise Essentials Perpetual License & Support per GPU, Permanent + 5 Years Original Service
Лицензия NVIDIA Al Enterprise Essentials Perpetual License & Support per GPU, Permanent + 5 Years Original Service

Отсрочка платежа
В зависимости от суммы поставляемого товара можем предоставить отсрочку платежа на срок от 5 до 90 дней. Условия отсрочки платежа рассматриваются индивидуально. Подробную информацию уточняйте у вашего менеджера.
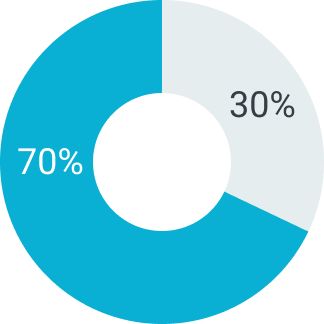
70%
Первый платеж
Первый платеж
30%
Второй платеж
Второй платеж
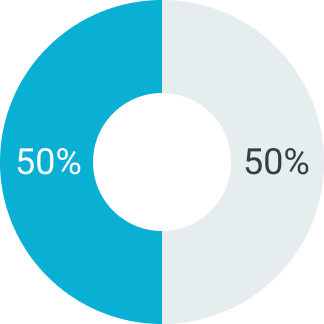
50%
Первый платеж
Первый платеж
50%
Второй платеж
Второй платеж
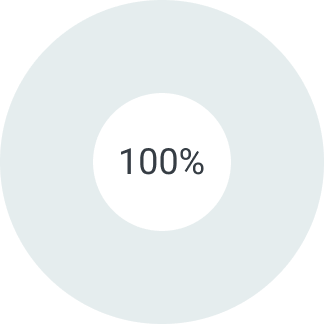
0%
Первый платеж
Первый платеж
100%
Второй платеж
Второй платеж
Описание

ИИ-графические процессоры Blackwell B200 выполнены на новой архитектуре Blackwell. Графический процессор B200 выполнен по 4-нанометровому техпроцессу компании TSMC и содержит в себе 208 млн транзисторов. В вычислениях FP4 и FP8 новый GPU обеспечивает производительность до 20 и 10 Пфлопс соответственно. Новый GPU состоит из двух кристаллов, которые произведены по специальной версии 4-нм техпроцесса TSMC 4NP и объединены 2,5D-упаковкой CoWoS-L.
Особенности
Blackwell B200 является самым большим чипом, который физически возможен при использовании существующих технологий производства. Это первый GPU компании Nvidia с чиплетной компоновкой. Он содержит два чиплета, каждый из которых построен на передовом 4 нм техпроцессе и содержит 104 миллиарда транзисторов.
Чипы соединены шиной NV-HBI с пропускной способностью 10 Тбайт/с и работают как единый GPU. Всего новинка насчитывает 208 млрд транзисторов. Каждый чипсет Blackwell имеет 4096-битную шину памяти и подключен к 96 ГБ HBM3E.
Одними из главных источников более высокой производительности B200 стали новые тензорные ядра и второе поколение механизма Transformer Engine. Последний научился более тонко подбирать необходимую точность вычислений для тех или иных задач, что влияет и на скорость обучения и работы нейросетей, и на максимальный объём поддерживаемых LLM. Теперь Nvidia предлагает тренировку ИИ в формате FP8, а для запуска обученных нейросетей хватит и FP4. Blackwell поддерживает работу с самыми разными форматами, включая FP4, FP6, FP8, INT8, BF16, FP16, TF32 и FP64. И во всех случаях кроме последнего есть поддержка разреженных вычислений.

Пара из таких чипов станет ядром видеокарты GB200. Её производительность можно оценить в 20 петафлопс. Новая архитектура Blackwell позволяет ускорить процесс обмена данными между несколькими подобными устройствами. К примеру, кластер из 16 графических ускорителей прошлого поколения тратил только 40% времени на полезные вычисления. Всё остальное занимал обмен информацией между единицами кластера. С их помощью можно значительно ускорить обучение нейросетей и сделать процесс более энергоэффективным.
Для объединения нескольких ускорителей Blackwell в одной системе новый GPU получил поддержку интерфейса NVLink пятого поколения, которая обеспечивает пропускную способность до 1,8 Тбайт/с в обоих направлениях. С помощью данного интерфейса (коммутатор NVSwitch 7.2T) в одну связку можно объединить до 576 GPU.
Blackwell GB200, который состоит из двух графических процессоров B200. GB200 обеспечивает более высокую производительность последовательной обработки и имеет высокую пропускную способность интерфейса NVLink для связи с GPU. В отличие от процессоров Intel Xeon Scalable или AMD EPYC, технология NVLink обеспечивает более быструю передачу данных между процессорами и графическими процессорами NVIDIA AI. Каждый чип B200 имеет производительность 20 PFLOPs в области искусственного интеллекта и поддерживает NVIDIA Transformer второго поколения и ядро Tensor шестого поколения.
Производительность
| Blackwell GPU | |
|---|---|
| FP4 Tensor Core | 20 petaFLOPS |
| FP8/FP6 Tenor Core | 10 petaFLOPS |
| INT8 Tensor Core | 10 petaOPS |
| FP16/BF16 Tensor Core | 5 petaFLOPS |
| TF32 Tensor Core | 2.5 petaFLOPS |
| FP64 Tensor Core | 45 teraFLOPS |
| GPU memory | Bandwidth | Up to 192 GB HBM3e | Up to 8 TB/s |
| Interconnect |
NVLink v5: 1.8TB/s PCIe Gen6: 256GB/s |
Интерфейс NVLink масштабируется внутри узла и может подключить до 576 графических процессоров. GB200 обеспечивает производительность 20 PFLOPs FP4 Tensor, 40 PFLOPs FP4 Tensor, 10 PFLOPs FP8 Tensor, 20 PFLOPs FP8 Tensor, 5 PFLOPs Bfloat16 и FP16, 2,5 PFLOPs TF32 Tensor. B200 также обеспечивает высокую производительность в высокоточных вычислениях (90 TFLOPs FP64). Эти новые процессоры обещают значительное улучшение производительности и мощности для облачных вычислений и искусственного интеллекта.
Официальное сертифицированное оборудование
Бесплатный
подбор оборудования
подбор оборудования
Расчёт КП за 20 минут
Отсрочка платежа
до 90 дней
до 90 дней
Доставка по Москве 2-3 дня