
Внимание
Мы работаем в штатном режиме. Наши склады готовы поставлять оборудование клиентам из Российской Федерации несмотря на санкционные запреты ЕС и США. Оборудование в РФ ввозится легально благодаря новому законодательству с параллельным импортом. Звоните и уточняйте! Информация актуальна на 27.02.26В связи с участившимися случаями недобросовестной конкуренции обращаем ваше внимание, что мы не передаем персональные данные третьим лицам
Поиск по сайту

Стойка NVIDIA GB200 NVL72





Наличие по запросу
Почему нет цен?
Уточнить ценуГарантия до 5 лет
Диагностика перед отправкой
С нами выгодно и удобно!
- Поддержка персонального менеджера
- Партнёрские скидки до 70%
- Онлайн-кабинет гарантийного сервиса
?
Как купить?
Раз, два и все делаРассчитаем стоимость
Присылайте спецификацию для подбора и расчета стоимости оборудования
1Раз
Привезём и подключим
Подключим и настроим оборудование в вашем офисе или ЦОДе
2Два
Характеристики
Производитель
Модель
GB200 NVL72
Максимальное количество GPU
72
Тип поддерживаемых GPU
72x встроенных GPU
Совместимые GPU
NVIDIA Blackwell B200
Семейство процессоров
NVIDIA Grace
Тип видеопамяти
HBM3E
Архитектура
Blackwell
Объем видеопамяти
13,5 TB
Комплектующие для NVIDIA GB200 NVL72
PCI-модули









Блоки питания



Жесткие диски








Оперативная память





Опции


Процессоры






Видеокарты

Лицензии

NVIDlA Al Enterprise Essentials Subscription per GPU, 1 Year one Year subscription

Лицензия NVIDlA Al Enterprise Essentials Subscription per GPU, 1 Year one Year subscription

NVIDIA Al Enterprise Essentials Perpetual License & Support per GPU, Permanent + 5 Years Original Service
Лицензия NVIDIA Al Enterprise Essentials Perpetual License & Support per GPU, Permanent + 5 Years Original Service

NVIDlA Al Enterprise Essentials Subscription per GPU, 2 Years one Year subscription
Лицензия NVIDlA Al Enterprise Essentials Subscription per GPU, 2 Years one Year subscription

Отсрочка платежа
В зависимости от суммы поставляемого товара можем предоставить отсрочку платежа на срок от 5 до 90 дней. Условия отсрочки платежа рассматриваются индивидуально. Подробную информацию уточняйте у вашего менеджера.
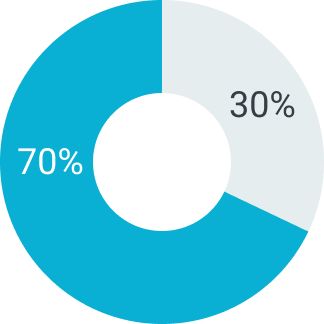
70%
Первый платеж
Первый платеж
30%
Второй платеж
Второй платеж
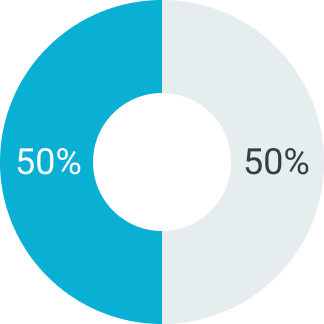
50%
Первый платеж
Первый платеж
50%
Второй платеж
Второй платеж
0%
Первый платеж
Первый платеж
100%
Второй платеж
Второй платеж
Описание
NVidia B200 NVL72 — это фактически серверная стойка, которая объединяет в себе 36 Grace Blackwell Superchip и пару коммутаторов NVSwitch 7.2T. Таким образом данная система включает в себя 72 графических процессора B200 Blackwell и 36 центральных процессоров Grace, соединенных NVLink пятого поколения. На систему приходится 13,5 Тбайт памяти HBM3E с общей пропускной способностью до 576 Тбайт/с, а общий объём оперативной памяти достигает 30 Тбайт.Платформа GB200 NVL72 работает как единый GPU с ИИ-производительностью 1,4 эксафлопс (FP4) и 720 Пфлопс (FP8). Эта система станет строительным блоком для новейшего суперкомпьютера Nvidia DGX SuperPOD.

Сердцем GB200 NVL72 является суперчип NVIDIA GB200 Grace Blackwell. Он соединяет два высокопроизводительных графических процессора NVIDIA Blackwell Tensor Core и процессор NVIDIA Grace с помощью межчипового интерфейса NVLink (C2C), обеспечивающего двунаправленную пропускную способность 900 ГБ/с. Благодаря NVLink-C2C приложения имеют согласованный доступ к единому пространству памяти. Это упрощает программирование и поддерживает большие потребности в памяти для LLM с триллионом параметров, моделей преобразователей для мультимодальных задач, моделей для крупномасштабного моделирования и генеративных моделей для 3D-данных. Вычислительный лоток GB200 основан на новом дизайне NVIDIA MGX. Он содержит два процессора Grace и четыре графических процессора Blackwell. GB200 имеет холодные пластины и разъемы для жидкостного охлаждения, поддержку PCIe 6-го поколения для высокоскоростной сети и разъемы NVLink для кабельного картриджа NVLink. Вычислительный лоток GB200 обеспечивает производительность искусственного интеллекта 80 петатопс и 1,7 ТБ быстрой памяти.
Самые серьезные проблемы требуют достаточного количества инновационных графических процессоров Blackwell для эффективной параллельной работы, поэтому они должны обмениваться данными с высокой пропускной способностью и низкой задержкой и быть постоянно занятыми. Стоечная система GB200 NVL72 обеспечивает эффективность параллельной модели для 18 вычислительных узлов с помощью системы коммутаторов NVIDIA NVLink с девятью лотками для переключателей NVLink и кабельными картриджами, соединяющими графические процессоры и коммутаторы. GB200 NVL72 плотно упаковывает и соединяет графические процессоры с помощью картриджа с медным кабелем для простоты эксплуатации. Он также использует конструкцию системы жидкостного охлаждения, обеспечивающую в 25 раз снижение затрат и энергопотребления.
NVLink и система коммутации NVLink пятого поколения

NVIDIA GB200 NVL72 представляет NVLink Wf-го поколения, который соединяет до 576 графических процессоров в одном домене NVLink с общей пропускной способностью более 1 ПБ/с и 240 ТБ быстрой памяти. Каждый лоток коммутатора NVLink имеет 144 порта NVLink емкостью 100 ГБ, поэтому девять коммутаторов полностью подключают каждый из 18 портов NVLink на каждом из 72 графических процессоров Blackwell. Революционная двунаправленная пропускная способность в 1,8 ТБ/с на каждый графический процессор более чем в 14 раз превышает пропускную способность PCIe Gen5, обеспечивая бесперебойную высокоскоростную связь для самых сложных современных крупных моделей.
NVLink на протяжении поколений
Ведущая в отрасли инновация NVIDIA для высокоскоростных SerDes с низким энергопотреблением способствует развитию связи между графическими процессорами, начиная с внедрения NVLink для ускорения связи между несколькими графическими процессорами на высокой скорости. Пропускная способность NVLink между графическими процессорами составляет 1,8 ТБ/с, что в 14 раз превышает пропускную способность PCIe. NVLink второго поколения в 12 раз быстрее, чем первое поколение со скоростью 160 ГБ/с, представленное в 2014 году. Связь между графическими процессорами NVLink сыграла важную роль в масштабировании производительности нескольких графических процессоров в системах искусственного интеллекта и высокопроизводительных вычислений. Увеличение пропускной способности графического процессора в сочетании с экспоненциальным увеличением размера домена NVLink увеличило общую пропускную способность домена NVLink в 900 раз с 2014 года до 1 ПБ/с для домена NVLink с 576 графическими процессорами Blackwell.

Охлаждение
Система жидкостного охлаждения будет поддерживать оптимальную рабочую температуру. Для связи всех компонентов используется более 3 км кабеля. При необходимости такие серверы можно связывать друг с другом, масштабирую всю систему. Nvidia отмечает, что новые устройства помогут ускорить обучение моделей с триллионами параметров и снизить потребление электроэнергии.
18 узлов с парой GB200 (суммарно 72 шт.) и 9 узлов с парой коммутаторов NVSwitch 7.2T, которые провязывают все ускорители по схеме каждый-с-каждым (агрегированно 130 Тбайт/с, более 3 км соединений), формируют 120-кВт суперускоритель GB200 NVL72 размером со стойку, оснащённый СЖО и единой DC-шиной питания. GB200 NVL72 одновременно является и узлом DGX GB200. Восемь DGX GB200 формируют DGX SuperPOD. Впрочем, будет доступен и SuperPOD попроще, на базе DGX B200.
Варианты использования и результаты производительности
Вычислительные и коммуникационные возможности GB200 NVL72 беспрецедентны, что делает грандиозные задачи в области искусственного интеллекта и высокопроизводительных вычислений практически достижимыми.
Обучение искусственному интеллекту
GB200 оснащен более быстрым трансформаторным двигателем второго поколения с точностью FP8. Он обеспечивает в 4 раза более высокую производительность обучения с 32 КБ ГБ200 NVL72 для больших языковых моделей, таких как GPT-MoE-1.8T, по сравнению с тем же количеством графических процессоров NVIDIA H100.
Вывод ИИ
GB200 обладает передовыми возможностями и трансформаторным механизмом второго поколения, который ускоряет рабочие нагрузки LLM-вывода. Он обеспечивает 30-кратное ускорение ресурсоемких приложений, таких как параметр 1,8T GPT-MoE, по сравнению с предыдущим поколением H100. Этот прогресс стал возможен благодаря новому поколению тензорных ядер, которые обеспечивают точность FP4 и множество преимуществ NVLink Wfth-поколения. 30-кратное ускорение сравнивается с 64 графическими процессорами NVIDIA Hopper, масштабируемыми с помощью 8-канального NVLink и InWniBand, по сравнению с 32 графическими процессорами Blackwell в GB200 NVL72 с использованием GPT-MoE-1.8T.
Обработка данных
Аналитика больших данных помогает организациям получать ценную информацию и принимать более обоснованные решения. Организации постоянно генерируют данные в больших масштабах и полагаются на различные методы сжатия, чтобы устранить узкие места и сэкономить на затратах на хранение. Для эффективной обработки этих наборов данных на графических процессорах в архитектуре Blackwell реализован аппаратный механизм распаковки, который может естественным образом распаковывать сжатые данные в любом масштабе и ускорять сквозные конвейеры аналитики. Механизм распаковки изначально поддерживает распаковку данных, сжатых с использованием форматов сжатия LZ4, DeTate и Snappy. Механизм распаковки ускоряет операции ядра, связанные с памятью. Он обеспечивает производительность до 800 ГБ/с и позволяет Грейс Блэквелл работать в 18 раз быстрее, чем процессоры (Sapphire Rapids) и в 6 раз быстрее, чем графические процессоры NVIDIA H100 с тензорными ядрами при тестировании запросов. Благодаря невероятно высокой пропускной способности памяти (8 ТБ/с) и высокоскоростному соединению чип-чип (C2C) процессора Grace процессор ускоряет весь процесс запросов к базе данных. Это приводит к первоклассной производительности в сценариях использования анализа данных и науки о данных. Это позволяет организациям быстро получать ценную информацию, одновременно сокращая свои расходы.


Моделирование на основе физики
Моделирование на основе физики по-прежнему остается основой проектирования и разработки продуктов. От самолетов и поездов до мостов, кремниевых чипов и даже фармацевтических препаратов — тестирование и улучшение продуктов с помощью моделирования экономит миллиарды долларов. Интегральные схемы, предназначенные для конкретных приложений, разрабатываются почти исключительно на центральных процессорах в ходе длительной и сложной работы, включая аналоговый анализ для определения напряжений и токов. Симулятор Cadence SpectreX является одним из примеров решателя. Следующий рисунок показывает, что SpectreX работает в 13 раз быстрее на процессоре GB200, чем на процессоре x86.
За последние два года отрасль все чаще обращалась к вычислительной динамике Tuid (CFD) с ускорением на графическом процессоре в качестве ключевого инструмента. Инженеры и проектировщики оборудования используют его для изучения и прогнозирования поведения своих конструкций. Cadence Fidelity, большой симулятор вихревых явлений (LES), выполняет моделирование на процессоре GB200 до 22 раз быстрее, чем на процессоре x86.
Стоечная конструкция GB200 NVL72 имеет возможность подключать 72 графических процессора Blackwell через один домен NVIDIA NVLink. Это снижает накладные расходы на связь, возникающие при масштабировании в традиционных сетях. В результате возможен вывод в реальном времени для параметра MoE LLM 1,8T, а обучение этой модели происходит в 4 раза быстрее. Работа 72 графических процессоров Blackwell, подключенных к NVLink, с 30 ТБ единой памяти в вычислительной фабрике со скоростью 130 ТБ/с создает суперкомпьютер AI exaFLOP в одной стойке.
Официальное сертифицированное оборудование
Бесплатный
подбор оборудования
подбор оборудования
Расчёт КП за 20 минут
Отсрочка платежа
до 90 дней
до 90 дней
Доставка по Москве 2-3 дня