
Внимание
Мы работаем в штатном режиме. Наши склады готовы поставлять оборудование клиентам из Российской Федерации несмотря на санкционные запреты ЕС и США. Оборудование в РФ ввозится легально благодаря новому законодательству с параллельным импортом. Звоните и уточняйте! Информация актуальна на 27.02.26В связи с участившимися случаями недобросовестной конкуренции обращаем ваше внимание, что мы не передаем персональные данные третьим лицам
Поиск по сайту

Платформа NVIDIA SXM HGX H100
Наличие по запросу 

 Запросить сертификат
Запросить сертификат
 Прямой импорт оборудования
Прямой импорт оборудованияиз Китая и ОАЭ без посредников
Наличие по запросу
Почему нет цен?
Уточнить ценуГарантия до 5 лет
Диагностика перед отправкой
С нами выгодно и удобно!
- Поддержка персонального менеджера
- Партнёрские скидки до 70%
- Онлайн-кабинет гарантийного сервиса
?
Как купить?
Раз, два и все делаРассчитаем стоимость
Присылайте спецификацию для подбора и расчета стоимости оборудования
1Раз
Привезём и подключим
Подключим и настроим оборудование в вашем офисе или ЦОДе
2Два
Характеристики
Производитель
Модель
NVIDIA SXM HGX H100
Совместимость
Серверы Dell PowerEdge


Серверы Supermicro





Серверы GIGABYTE




GPU серверы

Лицензии

NVIDlA Al Enterprise Essentials Subscription per GPU, 1 Year one Year subscription

Лицензия NVIDlA Al Enterprise Essentials Subscription per GPU, 1 Year one Year subscription

NVIDlA Al Enterprise Essentials Subscription per GPU, 2 Years one Year subscription
Лицензия NVIDlA Al Enterprise Essentials Subscription per GPU, 2 Years one Year subscription

NVIDlA Al Enterprise Essentials Subscription per GPU, 3 Year one Year subscription
Лицензия NVIDlA Al Enterprise Essentials Subscription per GPU, 3 Year one Year subscription

Отсрочка платежа
В зависимости от суммы поставляемого товара можем предоставить отсрочку платежа на срок от 5 до 90 дней. Условия отсрочки платежа рассматриваются индивидуально. Подробную информацию уточняйте у вашего менеджера.
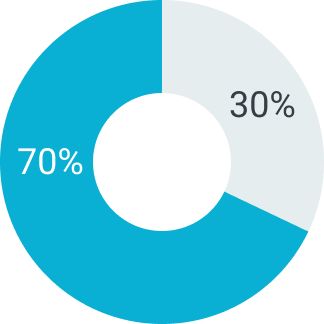
70%
Первый платеж
Первый платеж
30%
Второй платеж
Второй платеж
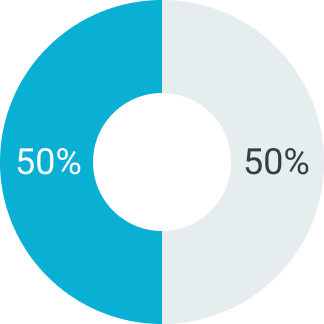
50%
Первый платеж
Первый платеж
50%
Второй платеж
Второй платеж
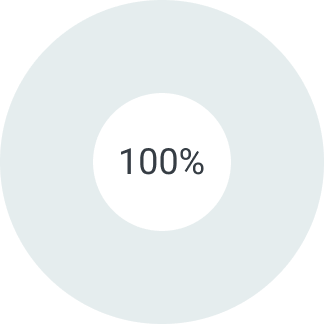
0%
Первый платеж
Первый платеж
100%
Второй платеж
Второй платеж
Описание
NVIDIA SXM HGX H100 4-GPU (80GB) Liquid cooling, Passive SXM 4 GPU Onboard 5th Gen Intel® Xeon®/4th Gen Intel® Xeon® Scalable processors 2 NVIDIA-Qualified
NVIDIA SXM HGX H100 — это серверная платформа на базе GPU NVIDIA H100 (архитектура Hopper), предназначенная для обучения и инференса крупных моделей искусственного интеллекта, работы с LLM, а также высокопроизводительных вычислений в современных дата‑центрах. Узлы HGX H100 выпускаются в вариантах с 4 или 8 GPU H100 SXM5, объединёнными высокоскоростными межсоединениями NVIDIA NVLink и NVSwitch четвёртого поколения, что обеспечивает очень высокую межграфическую пропускную способность и почти линейное масштабирование при распределённом обучении. В типичной конфигурации 8× H100 суммарный объём памяти HBM2e достигает 640 ГБ, а агрегированная пропускная способность памяти узла — порядка 27 ТБ/с, что критично для работы с генеративными моделями масштаба десятков и сотен миллиардов параметров. Платформа HGX H100 является референсной для OEM‑производителей и служит основой для серверов Dell, HPE, Supermicro и других брендов, ориентированных на задачи генеративного ИИ, мульти‑GPU инференса, анализа больших данных и HPC‑нагрузок. Конструкция узла рассчитана на эксплуатацию в стойковых системах высокой плотности с воздушным или жидкостным охлаждением и учитывает требования по энергопотреблению и устойчивости в круглосуточных рабочих режимах.
Архитектура и ключевые характеристики
В основе платформы NVIDIA SXM HGX H100 лежат GPU NVIDIA H100 Tensor Core с архитектурой Hopper, которая объединяет тензорные ядра нового поколения, оптимизированные CUDA‑ядра и поддержку расширенных форматов чисел для задач искусственного интеллекта и HPC. В составе узла HGX H100 может использоваться 4 или 8 ускорителей H100 SXM5, что даёт суммарную вычислительную мощность в сотни TFLOPS в FP16/TF32 и PFLOPS‑уровень в тензорных режимах с использованием форматов FP8 и других режимов смешанной точности. Такая конфигурация позволяет эффективно обучать и обслуживать крупные модели глубокого обучения, включая трансформерные архитектуры и LLM‑модели.
Подсистема памяти узла HGX H100 представлена высокоскоростной HBM2e, установленной на каждом GPU H100, с объёмом до 80 ГБ на ускоритель. В конфигурации 8× H100 суммарный объём HBM‑памяти достигает 640 ГБ, а общая пропускная способность памяти узла — до 27 ТБ/с, что обеспечивает возможность работы с крупными моделями и большими батчами данных без постоянных обращений к внешним системам хранения. Межграфическое взаимодействие реализуется через NVLink и NVSwitch четвёртого поколения, обеспечивая точка‑к‑точке и всепортовое подключение GPU с совокупной полосой пропускания на уровне терабайт в секунду, что минимизирует задержки и повышает эффективность распределённого обучения и инференса.
Платформа HGX H100 проектируется как модульный узел для интеграции в серверы форм‑фактора 4U и аналогичные шасси высокой плотности. Конструктив предусматривает размещение GPU H100 SXM5 на общей плате‑носителе с интегрированными NVSwitch, системой питания и разводкой высокоскоростных линий, а также интерфейсами подключения к CPU и сетевым адаптерам. Это позволяет OEM‑производителям строить серверы с поддержкой 4 или 8 GPU, optimized для задач ИИ и HPC, с возможностью применения воздушного или жидкостного охлаждения и соответствующей инфраструктурой питания.
Сценарии применения
Характеристики NVIDIA SXM HGX H100 определяют её как базовую платформу для крупномасштабных AI‑кластеров и систем высокопроизводительных вычислений.
- Идеально подходит для обучения нейросетей (Deep Learning) крупного масштаба, включая трансформеры, LLM‑модели и другие архитектуры, требующие большого объёма HBM‑памяти, высокой пропускной способности и быстрого обмена между GPU.
- Оптимизирована для инференса LLM моделей и генеративных AI‑сервисов, включая чат‑боты, системы генерации текста, кода и мультимодальные модели, где важны низкая задержка, высокая пропускная способность по запросам и эффективное масштабирование на множество GPU.
- Предназначена для высокопроизводительных вычислений (HPC): численное моделирование, методы Монте‑Карло, климатические и геофизические модели, вычислительная гидродинамика и структурный анализ, где требуется высокая производительность в FP64 и смешанных режимах.
- Подходит для построения кластеров генеративного ИИ и RAG‑систем, где необходимо тесное взаимодействие вычислительных ресурсов с высокопроизводительными хранилищами и сетями для работы с большими корпусами данных.
- Используется в облачных и корпоративных платформах как основа для предоставления GPU‑ресурсов в виде сервиса (GPU as a Service), обеспечения multi‑tenant‑сред и виртуализированных рабочих нагрузок.
Совместимость
Платформа NVIDIA SXM HGX H100 выступает в роли референсного модуля, на основе которого ведущие производители серверов строят готовые решения для ИИ и HPC, соответствующие требованиям NVIDIA‑Certified Systems. Ускоритель протестирован на совместимость с широким спектром серверных платформ, где обеспечиваются необходимые параметры по питанию, охлаждению и размещению узлов HGX H100 в стойках дата‑центров.
- Dell PowerEdge GPU‑серверы, для которых доступны конфигурации на базе HGX H100 4‑GPU и 8‑GPU узлов, предназначенные для задач обучения LLM, инференса и HPC‑нагрузок.
- HPE ProLiant и специализированные GPU‑серверы HPE Apollo, поддерживающие установку узлов HGX H100 и рассчитанные на высокоплотные конфигурации для ИИ и научных вычислений.
- Supermicro серверные системы, включающие платформы с HGX H100 4‑ и 8‑GPU и поддержкой воздушного или жидкостного охлаждения, используемые для построения кластеров ИИ и HPC.
Совместимость платформы SXM HGX H100 с конкретными конфигурациями серверов и кластеров фиксируется в документации NVIDIA‑Certified Systems и в технических описаниях OEM‑производителей. При проектировании инфраструктуры учитываются требования к электропитанию, схемам охлаждения, доступности высокоскоростных сетевых интерфейсов и интеграции с существующими системами хранения данных, что позволяет создавать масштабируемые и отказоустойчивые решения на базе HGX H100.
Энергоэффективность и программная экосистема
NVIDIA SXM HGX H100 разработана с учётом требований к энергоэффективности и устойчивому развитию, позволяя достигать высокой производительности ИИ и HPC‑нагрузок при оптимальном энергопотреблении на один узел и на кластер в целом. Использование архитектуры Hopper, современных технологических процессов производства GPU и продуманных схем питания и охлаждения в серверных платформах позволяет операторам дата‑центров снижать совокупную стоимость владения при росте вычислительной плотности. Платформа поддерживает инструменты мониторинга и управления питанием, позволяющие детально контролировать энергопотребление, тепловые характеристики и загрузку ресурсов GPU в реальном времени.
HGX H100 полностью интегрируется в программную экосистему NVIDIA для дата‑центров: CUDA, библиотеки CUDA‑X для глубокого обучения, машинного обучения, анализа данных и научных вычислений, а также стеки для оркестрации, виртуализации и мониторинга. Поддержка популярных фреймворков (TensorFlow, PyTorch и др.) реализуется через оптимизированные контейнеры и образы, что упрощает развёртывание и сопровождение приложений ИИ и HPC на кластерах HGX H100. В совокупности это делает NVIDIA SXM HGX H100 фундаментальной платформой для построения современных инфраструктур генеративного ИИ, LLM‑сервисов и высокопроизводительных вычислительных комплексов в корпоративных и облачных средах.
Официальное сертифицированное оборудование
Бесплатный
подбор оборудования
подбор оборудования
Расчёт КП за 20 минут
Отсрочка платежа
до 90 дней
до 90 дней
Доставка по Москве 2-3 дня