
Внимание
Мы работаем в штатном режиме. Наши склады готовы поставлять оборудование клиентам из Российской Федерации несмотря на санкционные запреты ЕС и США. Оборудование в РФ ввозится легально благодаря новому законодательству с параллельным импортом. Звоните и уточняйте! Информация актуальна на 21.03.26В связи с участившимися случаями недобросовестной конкуренции обращаем ваше внимание, что мы не передаем персональные данные третьим лицам
Поиск по сайту

GPU‑сервер HPE с 8 ускорителями NVIDIA H200 (SXM)
Наличие по запросу 
")
 Запросить сертификат
Запросить сертификат
 Прямой импорт оборудования
Прямой импорт оборудованияиз Китая и ОАЭ без посредников
Наличие по запросу
Гарантия до 5 лет
Диагностика перед отправкой
С нами выгодно и удобно!
- Поддержка персонального менеджера
- Партнёрские скидки до 70%
- Онлайн-кабинет гарантийного сервиса
?
Как купить?
Раз, два и все делаРассчитаем стоимость
Присылайте спецификацию для подбора и расчета стоимости оборудования
1Раз
Привезём и подключим
Подключим и настроим оборудование в вашем офисе или ЦОДе
2Два
Характеристики
Производитель
Модель
hpe nvidia h200 sxm
Максимальное количество GPU
8
Совместимые GPU
NVIDIA H200 (SXM)
Форм-фактор
5U
Семейство процессоров
Intel Xeon
Слоты для оперативной памяти
32
Максимальное количество отсеков для жестких дисков
8
Тип корпуса
Rack
Тип оперативной памяти
DDR5
Количество отсеков для БП
6
Отсрочка платежа
В зависимости от суммы поставляемого товара можем предоставить отсрочку платежа на срок от 5 до 90 дней. Условия отсрочки платежа рассматриваются индивидуально. Подробную информацию уточняйте у вашего менеджера.
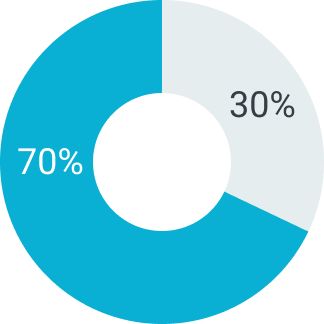
70%
Первый платеж
Первый платеж
30%
Второй платеж
Второй платеж
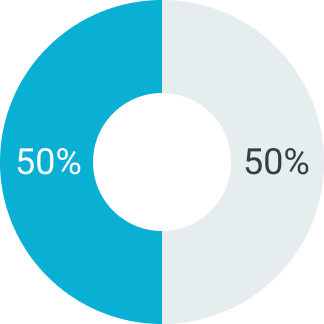
50%
Первый платеж
Первый платеж
50%
Второй платеж
Второй платеж
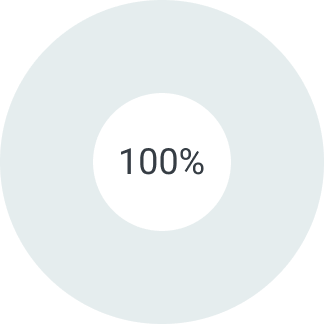
0%
Первый платеж
Первый платеж
100%
Второй платеж
Второй платеж
Описание
GPU‑сервер HPE с 8 ускорителями NVIDIA H200 (SXM) представляет собой мощную вычислительную платформу, предназначенную для выполнения сложных задач искусственного интеллекта, глубокого обучения и высокопроизводительных научных вычислений. Оснащённый восемью графическими ускорителями NVIDIA H200, каждый с 141 ГБ памяти HBM3e и пропускной способностью до 4,8 ТБ/с, сервер обеспечивает значительный объём видеопамяти и высокую скорость обработки данных, необходимые для масштабируемых AI моделей и ресурсоёмких рабочих нагрузок.
Архитектура и основные характеристики NVIDIA H200 SXM в сервере HPE

Ускорители NVIDIA H200 основаны на архитектуре Hopper с 4-нм техпроцессом, включают 456 тензорных ядер четвёртого поколения и поддерживают передовые числовые форматы FP8 и FP16 для повышения эффективности и точности вычислений. Каждый GPU оборудован 141 ГБ памяти HBM3e с пропускной способностью до 4,8 ТБ/с. Высокоскоростная топология NVLink 5.0 и NVSwitch позволяет объединять восемь GPU в высокопроизводительный кластер с пропускной способностью до 900 ГБ/с, обеспечивая эффективное масштабирование и ускорение параллельных вычислений.
Технология Multi-Instance GPU (MIG) позволяет разделять каждый GPU на до 7 независимых виртуальных инстансов, что значительно повышает гибкость и ресурсную эффективность системы при одновременном выполнении различных задач.
Инфраструктура, совместимость и сферы применения
Сервер HPE с 8 NVIDIA H200 SXM поддерживает современные дата-центровые технологии, включая NVMe SSD, высокопроизводительные сетевые интерфейсы с пропускной способностью до 400 Гбит/с, такие как InfiniBand и Ethernet. Платформа совместима с программным пакетом NVIDIA AI Enterprise, включающим CUDA, TensorRT, Triton, а также популярные AI-фреймворки, такие как PyTorch, TensorFlow и DeepSpeed. Это делает сервер идеальным для обучения и инференса крупных языковых моделей, генеративного AI, а также для решений HPC и научных вычислений.
- 8 ускорителей NVIDIA H200 SXM с 141 ГБ памяти HBM3e каждый
- Пропускная способность памяти до 4,8 ТБ/с на каждое устройство
- NVLink 5.0 и NVSwitch для высокоскоростного объединения GPU
- Поддержка Multi-Instance GPU (MIG) для разделения ресурсов
- Эффективное охлаждение и высокая энергетическая эффективность
- Совместимость с NVIDIA AI Enterprise и ведущими AI-фреймворками
- Подходит для масштабируемого обучения и инференса AI моделей
Официальное сертифицированное оборудование
Бесплатный
подбор оборудования
подбор оборудования
Расчёт КП за 20 минут
Отсрочка платежа
до 90 дней
до 90 дней
Доставка по Москве 2-3 дня
для бизнеса
