

Когда в стойке появляются плотные GPU-конфигурации серверов, охлаждение перестаёт быть задачей «для инженеров эксплуатации». Оно становится частью архитектуры вычислений. Ошибка тут дорогая: можно купить сильные серверы для ИИ, а потом упереться не в CUDA, память ECC или NVLink, а в тепло, питание и ограничения зала.
Методология: что подтверждено, а что требует расчёта
Подтверждено входными данными:
- TDP H100, B200, MI300X;
- принципы D2C и иммерсионного охлаждения;
- различие greenfield и brownfield по логике внедрения.
Требует расчёта под объект:
- допустимая мощность на стойку;
- эффект по PUE и CAPEX/OPEX;
- сроки интеграции и требования производителя к гарантии.
Почему охлаждение серверов ИИ стало отдельной задачей
Охлаждение серверов ИИ стало отдельной задачей потому, что тепловая нагрузка у таких систем выше, чем у классического серверного оборудования. Плотность размещения растёт быстрее, чем возможности традиционного воздушного охлаждения.
Для AI-нагрузок критичны не только CPU, но и GPU. А значит растут и кВт на стойку, и требования к стабильности работы ИИ, и энергопотребление системы охлаждения.
Обучение моделей и работа серверов для ИИ нагружают вычислительные блоки долго, плотно и без заметных пауз. Если классический сервер может жить на более рваном профиле, то серверы ИИ часто держат высокую загрузку часами и сутками. В этом режиме охлаждение влияет не только на температуру, но и на производительность, надёжность и ресурс компонентов.
Откуда берётся больше тепла в AI-кластерах
Больше тепла в AI-кластерах берётся прежде всего из GPU. Современные ускорители для обучения моделей машинного обучения и больших языковых моделей работают на высокой мощности и отдают огромное количество тепла в компактном объёме.
То есть работы ИИ в режиме обучения моделей — это не просто «сервер греется сильнее». Это поток постоянной тепловой нагрузки на GPU/CPU, оперативную память, питание, материнские платы и воздушный поток внутри серверного шасси.
Небольшой пример из практики интеграции.
Ситуация: заказчик подбирает серверы для ИИ под обучение моделей и смотрит только на число GPU.
Действие: инженер считает не только GPU, но и суммарную мощность узла, мощность на стойку, схему питания и отвод тепла.
Результат: часть конфигураций отпадает ещё до закупки, потому что существующая серверная не выдержит такую плотность размещения без перестройки инфраструктуры охлаждения.
Почему традиционные системы начинают упираться в предел
Традиционное воздушное охлаждение начинает упираться в предел, когда растут мощности на стойку и плотность размещения. Тогда холодного воздуха становится недостаточно, а системы кондиционирования и CRAC/CRAH начинают работать на грани физической и экономической эффективности.
Здесь важно не выдумывать цифры.
Точный порог зависит от компоновки стойки, типа серверов, горячих компонентов, организации холодных и горячих коридоров, запаса по вентиляторам и общей инфраструктуры дата центров.
Но логика понятна. Если одна стойка получает всё больше GPU, воздух должен:
- дойти до горячих компонентов,
- забрать тепло,
- вывести это тепло из стойки и зала.
И вот тут начинаются ограничения по объёму воздушного потока, перепаду температур, шуму, энергопотреблению вентиляторов и эффективности кондиционирования.
Пороговые ориентиры и методики расчёта
Типичные диапазоны плотностей по подходам
| Подход | Типичная плотность (кВт/стойку) | Температурные окна | Источник |
|---|---|---|---|
| Воздух с контейнментом | 8–15 | ASHRAE A1–A4: inlet 18–27°C | ASHRAE TC 9.9 (2023) |
| RDHx (Rear Door Heat Exchanger) | 15–25 | supply/return 15–30°C | HPE Whitepaper (2024) |
| D2C (Direct-to-Chip) | 25–60 | жидкость 30–50°C | NVIDIA DGX H100 (2024) |
| Иммерсия | 60–100+ | жидкость 45–65°C | NIST Immersion Guide (2024) |
Воздух с контейнментом подходит для умеренных плотностей до 15 кВт на стойку. RDHx позволяет повысить плотность до 25 кВт без полной переделки инфраструктуры. D2C справляется с нагрузками до 60 кВт, а иммерсия — с самыми плотными конфигурациями свыше 60 кВт.
Пример расчёта: 8× H100 в 42U стойке
Исходные данные:
- 8× NVIDIA H100 (700 Вт каждый) = 5600 Вт
- 2× Intel Xeon Platinum (270 Вт каждый) = 540 Вт
- Память, NIC, БП: ~860 Вт
- Итого узел: ~7 кВт
- Стойка (4 узла): ~28 кВт
Вывод:
- Воздух: требует мощный контейнмент и резерв CRAC/CRAH
- RDHx: подходит при модернизации части зала
- D2C: оптимален для новых проектов
- Иммерсия: избыточна для данной плотности
Базовые формулы sizing
Для воздуха:
Q (м³/с) = P (кВт) / (ρ × Cp × ΔT) где ρ = 1.2 кг/м³, Cp = 1.005 кДж/(кг·К), ΔT = 10–15°C
Для жидкости:
Q (л/с) = P (кВт) / (ρ × Cp × ΔT) где ρ = 1000 кг/м³, Cp = 4.18 кДж/(кг·К), ΔT = 10–20°C
Пример для 30 кВт/стойку:
- Воздух: ~2.5 м³/с (~5300 CFM)
- Жидкость: ~0.36 л/с (~21 л/мин)
Эти формулы помогают оценить требуемый расход теплоносителя и понять, справится ли текущая инфраструктура с нагрузкой.
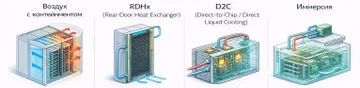
Какие методы охлаждения используют для серверов ИИ
Для серверов ИИ используют пять базовых подходов: воздушное охлаждение, in-row кондиционеры, RDHx (Rear Door Heat Exchanger), жидкостное охлаждение direct to chip и иммерсионное охлаждение.
Выбор зависит от плотности, типа нагрузки, ограничений ЦОД и того, строите вы новый зал или встраиваетесь в существующую инфраструктуру.
Воздушное охлаждение: холодные и горячие коридоры, вентиляторы, CRAC/CRAH
Воздушное охлаждение — это классическая система охлаждения серверов, где тепло уносит поток холодного воздуха через стойки и зал. Её база — холодные и горячие коридоры, серверные вентиляторы, CRAC/CRAH и общие системы кондиционирования.
Плюс: понятность, совместимость с большим числом современных серверов, проще для серверных комнат и привычнее эксплуатации.
Минус: воздух плохо отводит тепло по сравнению с жидкостью. При высокой плотности размещения и когда серверы ИИ работают долго под нагрузкой, традиционное воздушное охлаждение становится менее эффективным.
In-Row кондиционеры и RDHx: промежуточные варианты
In-Row кондиционеры устанавливаются непосредственно в ряд стоек и забирают тепло локально, до того как оно распространится по залу. Это повышает эффективность по сравнению с периметральными CRAC/CRAH.
RDHx (Rear Door Heat Exchanger) — теплообменник, встроенный в заднюю дверь стойки. Горячий воздух проходит через него и охлаждается водой/гликолем, не попадая в зал.
Когда применять:
- In-Row: для модернизации существующих залов с локальными горячими зонами
- RDHx: когда нужно повысить плотность без полной переделки инфраструктуры
Жидкостное охлаждение: direct to chip и cold plates
Жидкостное охлаждение нужно там, где воздух уже не справляется с локальным отводом тепла от CPU и GPU.
Вариант direct to chip работает так: cold plates устанавливаются прямо на горячие компоненты, жидкость в замкнутом контуре забирает тепло и отводит его дальше в теплообменник или CDU.
Это и есть прямое жидкостное охлаждение.
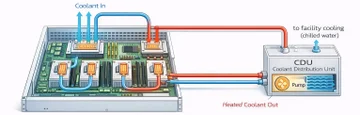
Важно: сервер при этом не обязательно целиком «на воде». Обычно жидкостное охлаждение direct to chip забирает тепло у наиболее горячих зон, а часть остальных компонентов всё равно остаётся на воздушном контуре.
Короткий SAR-кейс.
Ситуация: в проекте заказчик хочет сохранить существующий ЦОД, но поставить плотные серверы для ИИ.
Действие: вместо полной переделки зала рассматривают часть стоек с direct to chip, а остальную инфраструктуру оставляют на воздухе.
Результат: можно модернизировать только критичный сегмент, а не перестраивать весь дата центр сразу.
Иммерсионное охлаждение: когда серверы погружены в жидкость
Иммерсионное охлаждение — это подход, при котором серверы погружены в жидкость, обычно диэлектрическую, которая не проводит ток. Такой метод используют, когда нужно очень эффективно отводить тепло и работать с высокой плотностью.
Однофазное иммерсионное охлаждение использует жидкость с температурой кипения выше 100 °C: она остаётся жидкой и отводит тепло конвекцией. Двухфазное использует жидкость с кипением в диапазоне примерно 34–61 °C: жидкость кипит на горячих компонентах, пар потом конденсируется в теплообменнике.
— NIST Immersion Cooling Guide (2024), ASHRAE TC9.9 Data Center Cooling (2023), ISO 22096:2023.
Жидкости имеют диэлектрическую прочность >30 kV/mm и не проводят ток.
Расширенная матрица сравнения
| Метод | кВт/стойку | ΔT | Инфраструктура | Сервис/утечки | Отказоустойчивость | PUE/WUE | Совместимость |
|---|---|---|---|---|---|---|---|
| Воздух | 8–15 | 10–15°C | CRAC/CRAH, контейнмент | Низкий риск | N, N+1 | 1.5–2.0 | Универсальная |
| In-Row | 15–20 | 8–12°C | In-Row блоки, холодная вода | Средний | N+1 | 1.3–1.6 | Высокая |
| RDHx | 15–25 | 10–20°C | Водяной контур, CDU | Средний | N+1 | 1.2–1.5 | Высокая |
| D2C | 25–60 | 10–20°C | CDU, FWS, cold plates | Высокий | N+1, 2N | 1.1–1.3 | HGX/OCP |
| Иммерсия | 60–100+ | 5–15°C | Баки, насосы, теплообменники | Очень высокий | 2N | 1.05–1.2 | Специальная |
Воздух универсален, но ограничен по плотности. RDHx и In-Row — промежуточные варианты для модернизации. D2C справляется с высокими нагрузками и подходит для новых проектов. Иммерсия — для экстремальных плотностей и специальных задач.
Когда воздушное охлаждение ещё работает, а когда нужен переход на жидкостные решения
Как принять решение за 5 шагов
- Зафиксируйте состав узла: GPU, CPU, память, NIC, БП.
- Посчитайте суммарную мощность узла и мощность на стойку.
- Сверьте это с текущими возможностями зала: воздух, коридоры, CRAC/CRAH, питание.
- Определите профиль нагрузки: инференс / обучение / смешанный режим.
- Выберите сценарий:
- воздух — если текущая инфраструктура выдерживает расчётную тепловую нагрузку с запасом;
- D2C — если горячие CPU/GPU уже становятся ограничением, но остальная инфраструктура пригодна;
- иммерсия — если нужна очень высокая плотность или проект строится под специальную архитектуру.
Таблица «Сигнал → риск → рекомендуемое действие»
| Сигнал | Что это значит | Риск | Что делать |
|---|---|---|---|
| GPU-узлы ставятся в существующий зал без пересчёта тепловой нагрузки | Выбор делают по compute, а не по инфраструктуре | Перегрев, throttling, точечные аварии | До закупки посчитать мощность узла, стойки и инженерный резерв |
| В стойке горячие только часть узлов | Локальная, а не тотальная проблема охлаждения | Ненужная полная переделка ЦОД | Рассмотреть D2C только для горячего сегмента |
| Требуется высокая плотность в новом зале | Ограничения brownfield отсутствуют | Ошибка проектного выбора закрепится надолго | Сравнить воздух, D2C и иммерсию на этапе проекта |
| Нет мониторинга контура и датчиков утечек | Эксплуатация не готова | Инциденты и простой | Включить требования к мониторингу в ТЗ |
Эти сигналы помогают заранее выявить узкие места и избежать дорогих ошибок при внедрении систем охлаждения.
Мини-матрица по сценариям нагрузки
| Сценарий | Профиль нагрузки | Что проверять первым | Базовый кандидат | Комментарий |
|---|---|---|---|---|
| Инференс | переменная/умеренная | текущая мощность и воздух | воздух / гибрид | если нет горячих зон |
| Смешанный | неравномерная | какие узлы реально горячие | D2C для части стоек | не надо переделывать всё |
| Обучение | длительная высокая загрузка | стойка, контур, питание, мониторинг | D2C / иммерсия | считать проектно |
Для инференса часто хватает воздуха. Смешанные нагрузки требуют точечного подхода. Обучение больших языковых моделей — это зона D2C или иммерсии.
Greenfield и brownfield: новый или существующий ЦОД
В новом проекте greenfield выбор шире: можно сразу проектировать инфраструктуру охлаждения, питание, разводку и зал под нужную плотность.
В существующем ЦОД, то есть brownfield-сценарии, ограничения жёстче: мешают текущая инженерка, схема коридоров, свободная мощность, место под контуры и требования к остановкам.
Это одна из главных развилок.
Для современного дата центра, который строят с нуля под AI-нагрузки, прямое жидкостное охлаждение часто проще заложить сразу. Для существующей инфраструктуры всё зависит от того, модернизируете вы весь зал или только часть стоек.
Как охлаждение влияет на производительность, надёжность и счета за электричество
Охлаждение напрямую влияет на производительность систем, стабильность работы и общий расход энергии.
Если система охлаждения подобрана плохо, серверы ИИ могут продолжать работать, но уже медленнее, шумнее, менее предсказуемо и с более высоким риском отказов оборудования.
Что происходит с AI-серверами при перегреве
Перегрев влияет на AI-кластер в 4 шага:
- растёт температура GPU/CPU;
- автоматика повышает обороты вентиляторов и/или снижает частоты;
- падает предсказуемость времени выполнения задач;
- бизнес получает те же счета за электричество при меньшей полезной отдаче.
Небольшой кейс.
Ситуация: компания видит, что кластер формально доступен, но обучение моделей идёт медленнее расчёта.
Действие: проверяют не только загрузку GPU, но и датчики температуры, профиль вентиляторов и горячие зоны по стойке.
Результат: узкое место оказывается не в сети и не в коде, а в охлаждении.
Почему более эффективное охлаждение снижает общий расход энергии
Более эффективное охлаждение снижает общий расход энергии потому, что системе не нужно тратить столько ресурсов на борьбу с перегревом.
Это касается и серверных вентиляторов, и общих систем кондиционирования, и потерь из-за неэффективного распределения тепла по залу.
Охлаждение может снижать энергопотребление, но величина эффекта зависит от архитектуры ЦОД, климата, режима работы и доли AI-нагрузок.
Какие риски и требования нужно учесть при внедрении
При внедрении жидкостных и гибридных систем надо заранее учесть совместимость оборудования, контроль качества, риски протечек, требования к питанию охлаждение, мониторингу и сервису.
Чем выше плотность и цена простоя, тем опаснее относиться к охлаждению как к «добавке после закупки серверов».
Совместимость оборудования и контроль качества
Совместимость оборудования — это первый фильтр.
Нужно проверять производителя серверов, список совместимых платформ, материалы cold plates, материнские платы, CPU Intel Xeon или AMD EPYC, память ECC, шасси, коннекторы и требования к теплоносителю.
Трубы из 316L, толщина стенки не менее 1,65 мм, давление 10–20 бар, датчики протечек с автоотключением, двухконтурная система, поднятый пол с дренажем.
— ASHRAE TC 9.9 (2023), Uptime Institute Tier Standard (2022). Обновлено: использовать как ориентир для проектирования, проверять по актуальным нормам.
Таблица несовместимых материалов/жидкостей
| Материал | Несовместимые жидкости | Риск | Рекомендация |
|---|---|---|---|
| Алюминий | Гликоль без ингибиторов | Коррозия | pH 7–9, ингибиторы |
| Медь | Аммиак | Коррозия | Избегать |
| Резина EPDM | Минеральные масла | Набухание | Использовать Viton |
| Сталь | Вода без обработки | Ржавчина | Деионизация, ингибиторы |
Эти комбинации могут привести к коррозии, утечкам и выходу из строя системы охлаждения. Контроль качества теплоносителя и материалов — критически важен.
Требования к химии воды
- pH: 7.0–9.0
- Проводимость:
- Ингибиторы: нитриты, молибдаты (по ASHRAE)
- Контроль: ежемесячный анализ
Мониторинг в реальном времени и управление нагрузкой
Мониторинг в режиме реального времени нужен не как украшение, а как способ удержать стабильность работы.
Для AI-стоек важны датчики температуры, контроль давления, состояние контуров, распределение нагрузки и интеграция с DCIM/BMS.
Список метрик мониторинга:
- T supply/return (°C)
- ΔP (бар)
- Расход (л/мин)
- Состояние клапанов
- Датчики утечек
- Температура GPU/CPU
Рекомендуемые пороги алертов:
- ΔT >15°C: проверить расход
- ΔP
- Утечка >10 мл: немедленная остановка
Пошаговый план для brownfield: миграция без остановки зала
- Обследование (site survey):
- Замер текущей мощности на стойку
- Оценка свободного места под CDU
- Проверка питания и резерва
- Гидравлика/теплотехника:
- Расчёт требуемого расхода жидкости
- Выбор диаметра труб и насосов
- Моделирование ΔT и ΔP
- Выбор оборудования:
- Совместимые серверы/шасси
- CDU с нужной мощностью
- Датчики и клапаны
- Пилот:
- Установка 1–2 стоек с D2C
- Тестирование под нагрузкой
- Сбор телеметрии
- Поэтапный rollout:
- Миграция по стойкам/рядам
- Параллельная работа воздуха и D2C
- Постепенное выведение воздуха
Чек-лист ввода в эксплуатацию
- Плотность/герметичность соединений проверена
- Промывка контура выполнена
- Химия воды соответствует требованиям
- LOTO (Lock-Out/Tag-Out) процедуры утверждены
- Сценарии отказов протестированы
- Failover CDU работает
- Тест утечки пройден
- Телеметрия в DCIM/BMS настроена
- Пороги алертов установлены
- Персонал обучен
Экономика: CAPEX/OPEX, PUE/WUE, окупаемость
Модель TCO (упрощённая)
CAPEX:
- Сервер/шасси: базовая стоимость
- CDU: $50–150k на 100 кВт
- Трубопроводы: $10–30k на ряд
- RDHx: $5–15k на стойку
- Иммерсия: $200–500k на зал
OPEX (годовой):
- Энергия вентиляторов: 10–15% от IT-нагрузки
- Энергия помп/чиллеров: 5–10% от IT-нагрузки
- Обслуживание: 2–5% от CAPEX
- Жидкости: $1–5k/год на контур
Диапазоны влияния на PUE/WUE
| Подход | PUE | WUE (л/кВт·ч) | Источник |
|---|---|---|---|
| Воздух | 1.5–2.0 | 0 | ASHRAE (2023) |
| RDHx | 1.2–1.5 | 1–3 | HPE (2024) |
| D2C | 1.1–1.3 | 2–5 | NVIDIA (2024) |
| Иммерсия | 1.05–1.2 | 0.5–2 | NIST (2024) |
Чем эффективнее охлаждение, тем ниже PUE и тем меньше энергии уходит на инфраструктуру. Это напрямую влияет на счета за электричество.
Кейс: окупаемость D2C для 60 кВт/стойку
Исходные данные:
- 10 стоек × 60 кВт = 600 кВт IT-нагрузки
- Воздух: PUE 1.6 → 960 кВт общая
- D2C: PUE 1.2 → 720 кВт общая
- Экономия: 240 кВт × 8760 ч × $0.10/кВт·ч = $210k/год
- CAPEX D2C: $500k
- Окупаемость: 2.4 года
Типичные ошибки при выборе охлаждения
- Выбирать по числу GPU, а не по тепловому профилю
- Риск: недооценка реальной мощности узла
- Коррекция: считать TDP всех компонентов
- Считать охлаждение отдельно от питания
- Риск: упереться в PDU/UPS
- Коррекция: проектировать комплексно
- Игнорировать brownfield-ограничения
- Риск: невозможность установки CDU
- Коррекция: site survey до закупки
- Не проверять гарантийные условия
- Риск: потеря гарантии при D2C
- Коррекция: запросить письменное подтверждение
- Закладывать мониторинг «потом»
- Риск: слепая эксплуатация
- Коррекция: DCIM/BMS в ТЗ сразу
Стандарты и соответствие
Таблица мэппинга стандартов
| Стандарт | Применимые разделы | Что регулирует |
|---|---|---|
| ASHRAE TC 9.9 (2023) | Liquid Cooling Guidelines | Температурные окна, материалы труб |
| ISO 22096:2023 | Dielectric Fluids | Свойства жидкостей для иммерсии |
| IEC 62698-2 (2022) | Material Compatibility | Совместимость материалов с жидкостями |
| Uptime Tier III/IV (2022) | Redundancy | Требования к отказоустойчивости |
| OCP LC Specs (2024) | Open Compute | Спецификации D2C для OCP-серверов |
Выжимка ключевых параметров
ASHRAE A1–A4:
- A1: 15–32°C, 20–80% RH
- A2: 10–35°C, 20–80% RH
- A3: 5–40°C, 8–85% RH
- A4: 5–45°C, 8–90% RH
Жидкостные контуры:
- Supply: 30–50°C (D2C), 45–65°C (иммерсия)
- Return: +10–20°C от supply
- Давление: 10–20 бар (D2C)
Детекция утечек:
- Датчики на полах/трубах
- Автоотключение при срабатывании
- Резервуары сбора ≥10 л/м²
Что запросить у вендора или интегратора до закупки
- Поддерживаемые платформы и совместимые шасси
- Схема отвода тепла (воздух/D2C/иммерсия)
- Требования к теплоносителю (тип, pH, проводимость)
- Условия гарантии при использовании жидкостного охлаждения
- Требования к датчикам утечек и автоматике
- Схема сервисного обслуживания (периодичность, процедуры)
- Сценарий аварийной остановки (LOTO, failover)
- Требования к BMS/DCIM (протоколы, телеметрия)
- Условия brownfield-интеграции (место под CDU, питание)
- Пусконаладочные процедуры (промывка, тесты, ATP)
Как выбрать систему охлаждения серверов ИИ под вашу задачу
Короткий чек-лист выбора для стойки, зала и ЦОД
- Какова реальная мощность на стойку сейчас и какой будет после установки новых AI-узлов?
- Какие GPU/CPU используются и какой у них тепловой профиль в режиме обучения и инференса?
- Это новый дата центр, модернизация части стоек или существующая серверная с жёсткими ограничениями?
- Справляются ли текущие воздушные системы с нагрузкой без перегрева и перерасхода энергии?
- Есть ли у выбранных серверных платформ поддержка direct to chip или других жидкостных решений?
- Как устроены мониторинг, датчики температуры, обнаружение утечек и ввод в эксплуатацию?
- Кто будет обслуживать систему после запуска: внутренний персонал или интегратор с опытом работы?
Когда стоит подключать интегратора
Если задача в том, чтобы подобрать серверное оборудование, СХД, сетевую часть и собрать это в работающий проект без субподрядчиков, у Kvantech это как раз профильная зона.
Компания поставляет серверы, СХД, сетевое оборудование, проектирует решения и выполняет монтаж и настройку своими силами.
Для B2B-заказчика это удобнее, чем разрывать проект между несколькими подрядчиками: проще связать серверов для ИИ, питание, сеть и охлаждение в один проект.
FAQ: Часто задаваемые вопросы
Когда воздушного охлаждения уже недостаточно для AI-серверов?
Когда мощность на стойку превышает 15–20 кВт и текущие CRAC/CRAH не справляются с отводом тепла без перегрева или перерасхода энергии.
Чем direct-to-chip отличается от иммерсионного охлаждения?
D2C отводит тепло от горячих компонентов через cold plates в замкнутом контуре, остальное — на воздухе. Иммерсия погружает весь сервер в диэлектрическую жидкость.
Подходит ли жидкостное охлаждение для существующего ЦОД?
Да, если есть место под CDU, свободная мощность питания и возможность проложить контур. Brownfield требует site survey и поэтапного внедрения.
Нужно ли жидкостное охлаждение для инференса?
Не всегда. Для кратковременных пиковых нагрузок часто хватает мощного воздуха или RDHx. Для круглосуточного обучения моделей — D2C предпочтительнее.
Какие риски есть у D2C?
Утечки, коррозия, конденсация, несовместимость материалов, сложность сервиса. Требуется мониторинг, датчики утечек и обученный персонал.
Что запросить у поставщика перед закупкой AI-серверов?
Совместимые платформы, схему отвода тепла, требования к теплоносителю, условия гарантии, требования к датчикам утечек, схему сервиса, сценарий аварийной остановки, требования к BMS/DCIM, условия brownfield-интеграции, пусконаладочные процедуры.
Глоссарий терминов
TDP (Thermal Design Power) — расчётная тепловая мощность процессора или GPU, которую система охлаждения должна отводить.
D2C (Direct-to-Chip) — прямое жидкостное охлаждение, где cold plates устанавливаются на горячие компоненты.
Cold plate — теплообменник, устанавливаемый на CPU/GPU для отвода тепла жидкостью.
CDU (Coolant Distribution Unit) — блок распределения охлаждающей жидкости в контуре D2C.
CRAC (Computer Room Air Conditioning) — система кондиционирования воздуха для серверных залов.
CRAH (Computer Room Air Handler) — система обработки воздуха для серверных залов.
PUE (Power Usage Effectiveness) — коэффициент эффективности использования энергии в ЦОД (общая мощность / IT-нагрузка).
Greenfield — новый проект ЦОД, строящийся с нуля.
Brownfield — модернизация существующего ЦОД.
Throttling — снижение частот CPU/GPU при перегреве для защиты от повреждений.
Источники и материалы по теме
Ниже — не «идеальный список настольных документов», а честный перечень того, что упомянуто во входных данных и может служить стартовой точкой для проверки:
- NVIDIA H100 specifications / DGX H100 whitepaper, 2024 — для TDP GPU и характера тепловой нагрузки в обучении.
- NVIDIA GTC 2024 materials по B200 — для оценки роста мощности новых ускорителей.
- AMD Instinct MI300X official datasheet, 2023 и ROCm docs, 2024 — для TDP и профиля загрузки.
- NIST Immersion Cooling Guide, 2024 — по принципам однофазного иммерсионного охлаждения.
- ASHRAE TC9.9 Data Center Cooling, 2023 — по общим инженерным ориентирам для охлаждения дата центров.
- ISO 22096:2023 и IEC 62698-2, 2022 — по свойствам диэлектрических жидкостей и совместимости материалов.
- Документация производителей серверных платформ — для проверки совместимости, гарантий и требований к охлаждению конкретного оборудования.
И важная оговорка напоследок.
Для части вопросов в этой теме у нас сейчас не хватает подтверждённых исследований именно в составе входных данных. Поэтому если вы проектируете современную серверную, AI-кластер или модернизируете ЦОД под GPU-нагрузки, финальное решение нужно принимать не по статье и не по маркетингу, а по тепловому расчёту, спецификациям производителя серверов и проекту инженерной инфраструктуры.